
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- BERT
- dl
- 생성모델
- multimodal
- animation retargeting
- 오블완
- WinAPI
- motion matching
- 언리얼엔진
- UE5
- deep learning
- Font Generation
- RNN
- NLP
- ue5.4
- 디퓨전모델
- 폰트생성
- Unreal Engine
- 모션매칭
- WBP
- Few-shot generation
- userwidget
- 딥러닝
- ddpm
- GAN
- Diffusion
- CNN
- cv
- Stat110
- Generative Model
- Today
- Total
Deeper Learning
Adam Optimizer 본문
Momentum
Momentum 방식은 Gradient Descent에 관성을 적용한 것으로 각 weight의 과거 시점의 정보를 저장하고 이를 활용하여 weight가 업데이트된다.
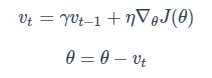
$\gamma$는 momentum term으로 0.9를 기본값으로 대부분 사용한다.

위의 그림처럼 Oscillation이 발생할 경우 Momentum을 사용하면 이동방향이 계속해서 바뀔 경우 업데이트가 덜 되며, 같은 방향으로 업데이트가 계속될 경우 더 빠르게 업데이트되기 때문에 결과적으로 SGD보다 빠르게 global minima에 도달할 수 있다.
Adagrad
Adagrad(Adaptive Gradient)는 지금까지 각 변수의 누적 변화 정도를 기록하여, 변화가 많았던 변수는 step size를 작게 하고 변화가 없었던 변수는 step size를 크게 하는 Gradient Descent Optimization 알고리즘이다.

$G_{t}$는 weight와 같은 차원의 벡터로 각 변수의 gradient의 제곱합을 저장한다.
SGD의 gradient descent 식에 gradient vector를 $G_{t}$에 epsilon을 더한 값의 제곱근으로 나누면 Adagrad가 된다.
학습이 진행될수록 $G_{t}$의 값이 점점 작아져 step size가 매우 작아져 더 이상 업데이트가 되지 않는 문제점이 있다.
RMSprop
RMSprop은 제프리 힌튼 교수가 별다른 논문의 발표가 아닌 수업 중에 소개한 방식으로 Adagrad에 지수 이동평균을 적용한 Optimizer입니다.

Adagrad의 $G$가 weight가 update 됨에 따라 계속해서 증가하는 문제를 어느 정도 해결이 가능하다.
Adam
Adam은 Momentum과 RMSprop을 동시에 적용한 것과 비슷한 알고리즘이다.

m과 v가 처음에 0으로 초기화되고 Beta 1, Beta2는 0.9, 0.999의 값을 주로 사용하기 때문의 초기에 weight update가 0에 편향된다.
이를 해결하기 위해 smoothing을 적용시킨다.
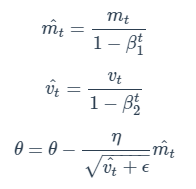
Momentum과 동일하게 SGD의 gradient vector 부분에 m이 들어가며 RMSprop과 동일하게 step size가 정해진다.
epsilon은 보통 $10^{-8}$으로 설정한다.
Adam Optimizer는 가장 보편적으로 사용되며 좋은 성능을 보이는 Optimizer이다.
'AI > Deep Learning' 카테고리의 다른 글
| Graph Neural Network (GNN) (0) | 2021.02.26 |
|---|---|
| GPT (0) | 2021.02.22 |
| Autoencoder (0) | 2021.02.11 |
| Gradient Descent (0) | 2021.02.10 |
| Attention Mechanism (0) | 2021.01.29 |



