
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Font Generation
- RNN
- Diffusion
- animation retargeting
- UE5
- userwidget
- deep learning
- Few-shot generation
- WinAPI
- 딥러닝
- WBP
- 폰트생성
- ddpm
- 오블완
- Unreal Engine
- dl
- 언리얼엔진
- BERT
- 생성모델
- NLP
- CNN
- ue5.4
- cv
- multimodal
- motion matching
- 디퓨전모델
- Stat110
- GAN
- 모션매칭
- Generative Model
- Today
- Total
목록폰트생성 (4)
Deeper Learning
 FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
Yitian Liu, Zhouhui Lian, [Wangxuan Institute of Computer Technology, Peking University, Beijing, China] (2022.10.13) Abstract 적은 데이터로 고품질의 중국어 폰트를 생성해내는 것은 어려운 일이며 현존하는 few-shot 폰트 생성 방식은 low-resolution의 획이 끊기는 폰트를 만드는데 그쳤다 이러한 문제를 해결하기 위해 본 논문은 고품질의 few-shot 생성이 가능한 FontTransformer를 제시 key idea는 prediction error가 쌓이는 것을 피하기 위한 parallel Transformer, 생성된 획의 퀄리티를 높이기 위한 serial Transformer의 사용 실제 ..
 Few-Shot Font Generation by Learning Fine-Grained Local Styles
Few-Shot Font Generation by Learning Fine-Grained Local Styles
Licheng Tang, Yiyang Cai, Jiaming Liu, Zhibin Hong, Mingming Gong, Minhu Fan, Junyu Han, Jingtuo Liu, Errui Ding, Jingdong Wang [Baidu Inc, University of California, Berkeley, University of Melbourne] (2022.05) Abstract **Few-shot font generation(FFG)**는 노동 cost를 크게 줄여주어 주목을 받고 있는 기술 이전의 연구들은 reference glyph의 content와 style을 global, component-wise하게 disentangle 하는 방식으로 FFG에 접근 하지만 glyph의 style은 ..
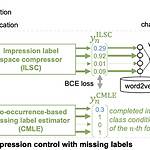 Font Generation with Missing Impression Labels
Font Generation with Missing Impression Labels
Seiya Matsuda, Akisato Kimura, Seiichi Uchida, Kyushu Univ., NTT, (2022.03) Abstract impression labeling 된 dataset을 사용하여 specific impression fonts를 GAN으로 생성하는 것이 목표 Main difficulty font impression은 애매 특정 impression label이 없다고 그 폰트가 해당 impression에 해당하지 않는 것이 아님 (dataset이 불안정) Key Idea co-occurrence-based missing label estimate impression label space compressor MyFonts 데이터셋은 전문가 + 비전문가가 tagging 한 ..
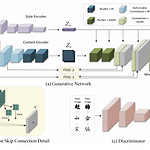 DG-Font: Deformable Generative Networks for Unsupervised Font Generation
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Abstract 현존 methods는 대부분 supervised learning, 매우 많은 paired data가 필요 image-to-image translation은 style을 텍스쳐와 색깔로 정의 냉림 Feature Deformation Skip Connection (FDSC)를 제시 predict pairs of displacement map employs the predicted maps to apply deformable convolution to the low-level feature maps from content encoder style-invariant feature 표현을 학습하기 위해 content encoder에 3개의 deformable convolutional layers를..