
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Diffusion
- CNN
- 딥러닝
- ue5.4
- cv
- Unreal Engine
- UE5
- animation retargeting
- RNN
- 모션매칭
- BERT
- Generative Model
- multimodal
- userwidget
- WinAPI
- dl
- 언리얼엔진
- deep learning
- WBP
- NLP
- 생성모델
- ddpm
- 오블완
- motion matching
- 폰트생성
- Few-shot generation
- 디퓨전모델
- GAN
- Font Generation
- Stat110
- Today
- Total
Deeper Learning
Few-Shot Font Generation by Learning Fine-Grained Local Styles 본문
Few-Shot Font Generation by Learning Fine-Grained Local Styles
Dlaiml 2022. 7. 12. 09:51Licheng Tang, Yiyang Cai, Jiaming Liu, Zhibin Hong, Mingming Gong, Minhu Fan, Junyu Han, Jingtuo Liu, Errui Ding, Jingdong Wang
[Baidu Inc, University of California, Berkeley, University of Melbourne] (2022.05)
Abstract
- **Few-shot font generation(FFG)**는 노동 cost를 크게 줄여주어 주목을 받고 있는 기술
- 이전의 연구들은 reference glyph의 content와 style을 global, component-wise하게 disentangle 하는 방식으로 FFG에 접근
- 하지만 glyph의 style은 여러 local detail이 큰 부분을 차지하며 spatial location에 따라 한 glyph이 여러 style을 담고 있을 수 있음
- 저자는 아래 2개 항목을 학습하는 방식으로 폰트 생성에 접근
- fine-grained local styles from references
- spatial correspondence between the content and reference glyphs
- 명시적인 global, content-wise modeling을 사용하지 않고 cross-attention을 사용하여 알맞은 local style에 attend 할 수 있도록 modeling
- FFG에서 SOTA를 달성, user study로 제시한 접근법이 이전 방식들보다 뛰어나다는 것을 보임
1. Introduction
- 이전 zi2zi, Pix2Pix로 폰트를 생성하는 것은 많은 학습 데이터를 필요로 하였음
- content와 style representation을 명시적으로 disentangle 하는 방식이 최근 인기 있는 FFG method
- 이전 연구들은 component-wise style에 집중하였으나 finer-grained styles을 무시하곤 했음
- 하지만 content와 style은 매우 entangle 되어 있음, disentangle은 매우 어려운 과제
- 저자는 fine-grained local styles을 학습하기 위한 reference encoder를 도입
- style representation은 content embedding과 style Aggregation 모듈에서 만나서 glyph을 생성하는데 쓰임 (Figure 1 참고)

- 모델이 reference의 세부사항을 잘 복원하도록 하기위해 self-reconstruction branch를 추가
- reference glyph을 선정하는 전략을 제시하였음
- 정리하면 contribution은 다음과 같다
- reference glyphs에서 FLS(fine-grained local style)을 추출하고 cross-attention을 사용하여 style을 혼합하는 module을 사용하는 FFG 모델 FSFont를 제시
- self-reconstruction branch를 사용하여 결과 이미지의 퀄리티와 모델이 detail을 잡아내는 능력을 모두 향상시키고 SOTA를 달성
- reference glyph을 선정하는 조합룰을 제시
2. Method
2.1. Problem Setting and Method Overview
- content image에 reference images에서 추출한 style representation을 Style Aggregation Module(SAM)을 사용하여 style을 변화시키고 Decoder를 통해 target image와 유사한 generated image를 생성하는 것이 목표
- multi-task projection discriminator를 사용
2.2. Style Aggregation Module
- SAM의 core는 spatially local style에 집중할 수 있도록 하는 multi-head cross attention block
- GANet과 같은 이전 FFG 도메인 논문에서 자주 등장하는 cross attention module이라 자세한 기술은 생략 (위 수식 및 Figure 3 참고)
2.3. Self Reconstruction
- k-shot font generation을 학습하는 것은 content-reference pairs의 약한 correlation으로 인해 매우 어려움
- 따라서 비교적 쉬운 Self-Reconstruction(SR) branch를 사용하여 학습을 쉽게 만듦
2.4. Reference Selection
- 이전 FFG 논문인 LF-Font에서는 reference set을 target character와 같은 component를 가진 character를 모아 랜덤하게 구성
- 위 방식의 문제는 모델이 매번 달라지는 reference set 구성에서 component-wise features를 추출하는 방식을 학습하기가 쉽지 않다는것
- 그러므로 저자는 target glyph에 따라 고정되는 reference set을 사용
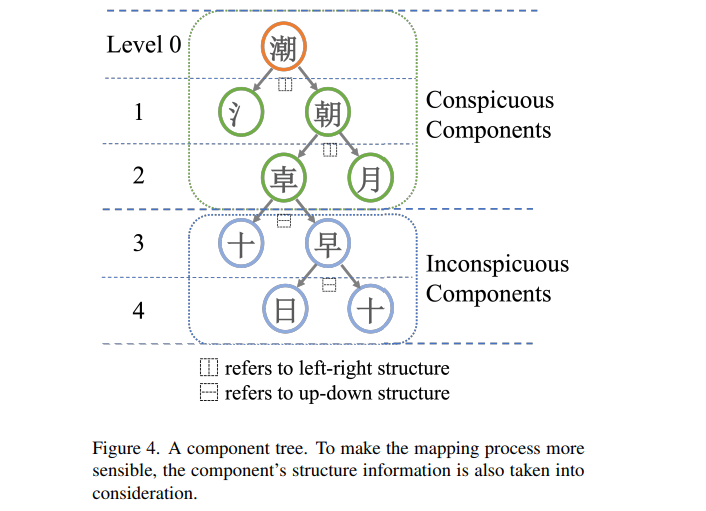
- target glyph의 component를 모두 포함하도록 reference set을 구성
2.5. Training
xc: content glyph image
Rs: fixed set of reference glyph images
ˆyc: main branch generated image
˜yc: Self-Reconstruction branch generated image
¯yc∈{^yc~yc}
Pg: generated image set
Pd: real image set
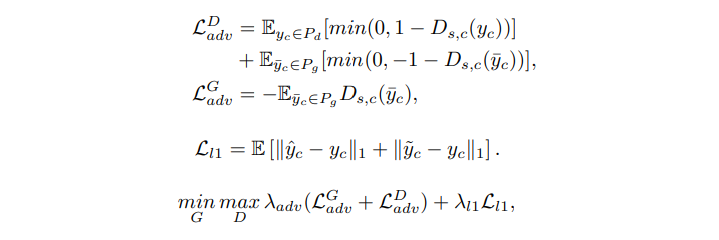
- adversarial loss와 L1 loss를 사용하며 실험에서는 λadv=1,λl1=0.1을 사용
3. Experiments
- 3396 chars를 가지고 있는 407개의 중국어 폰트 데이터셋 사용
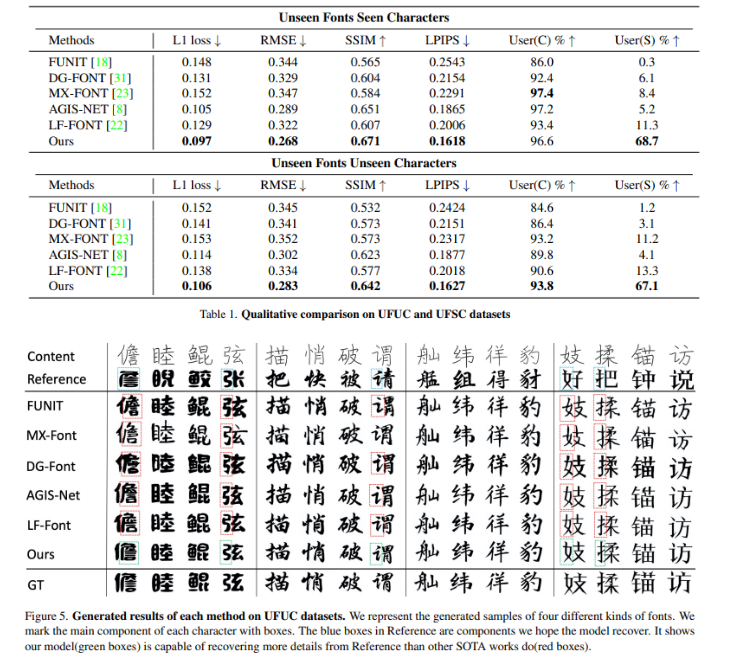
- 여러 metric에서 기존 FFG method 보다 좋은 결과를 보임
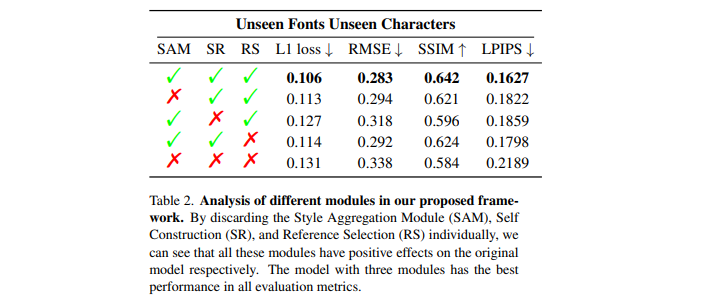
- ablation study를 통해 SAM, SR, RS(Reference selection)이 모두 효과가 있었음을 검증
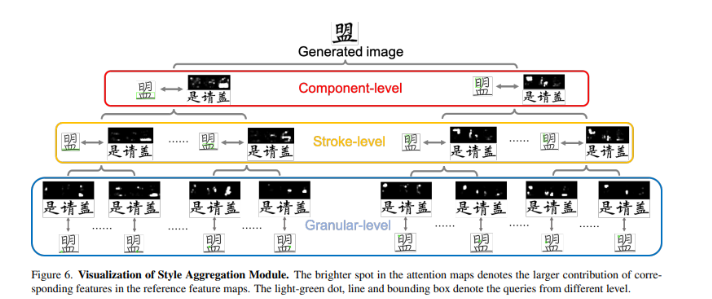
- cross attention block이 원하는 local style에 attend 하는 것을 Granular, Stroke, Component-level에서 visualization
4. Conclusion
- content, reference glyph의 component features를 기반으로 spatial correspondence를 계산하는 새로운 FFG model FSFont를 제시
- 고정된 reference set을 사용하여 content와 reference glyph이 공통된 component를 공유하도록 하여 component feature를 추출하기 용이
- 다양한 metric에서 기존 method보다 좋은 성능을 기록하여 FFG SOTA를 달성
- 한정된 데이터셋으로 학습하였기 때문에 font의 다양한 detail을 모두 표현할 수 없음
- FSFont는 인간의 손글씨를 모방하는데 악용될 수 있으나 아직 필적 감정 전문가에 의해 쉽게 구별될 수 있는 퀄리티
후기 & 정리
- fine-grained local style 학습을 목표로 모델링 된 새로운 FFG 모델 FSFont를 제시
- 다양한 metric에서 기존 method를 넘어서는 SOTA를 달성
- local style을 학습하기 위해 content, reference set에서 cross attention을 사용하는 기존 연구가 있었기 때문에(GANet 등) novelty를 찾기 힘들었던 논문
- 이번 년 초에 회사에서 FFG 연구할 때 실험해봤던 모델 아키텍처와 매우 유사해서 놀랐던 논문
- reference set을 고정하고 제시한 알고리즘에 따라 reference selection, 한국어의 경우 component가 초성, 중성, 종성이라 간단한 알고리즘을 사용하면 될 듯하다
- 구현체가 없어 직접 모델 아키텍처까지 구현한 논문
https://github.com/yjunej/FSFont-pytorch
GitHub - yjunej/FSFont-pytorch: Unofficial PyTorch implementation of Few-Shot Font Generation by Learning Fine-Grained Local Sty
Unofficial PyTorch implementation of Few-Shot Font Generation by Learning Fine-Grained Local Styles(FSFont) - GitHub - yjunej/FSFont-pytorch: Unofficial PyTorch implementation of Few-Shot Font Gene...
github.com
Reference
[0] Licheng Tang et al., (2022), "Few-Shot Font Generation by Learning Fine-Grained Local Styles". https://arxiv.org/abs/2205.09965
Few-Shot Font Generation by Learning Fine-Grained Local Styles
Few-shot font generation (FFG), which aims to generate a new font with a few examples, is gaining increasing attention due to the significant reduction in labor cost. A typical FFG pipeline considers characters in a standard font library as content glyphs
arxiv.org



