
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GAN
- 폰트생성
- ddpm
- userwidget
- deep learning
- UE5
- Unreal Engine
- Stat110
- WinAPI
- Diffusion
- 딥러닝
- ue5.4
- CNN
- Generative Model
- cv
- motion matching
- 언리얼엔진
- 모션매칭
- 생성모델
- dl
- multimodal
- WBP
- NLP
- 오블완
- Font Generation
- BERT
- RNN
- animation retargeting
- 디퓨전모델
- Few-shot generation
- Today
- Total
목록dl (8)
Deeper Learning
 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou (2022.01) [Google Research, Brain Team] Abstract일련의 중간 추론 과정을 뜻하는 사고의 흐름, Chain-of-Thought(이하 COT)를 사용하여 Large Language Model(이하 LLM)의 복잡한 추론성능을 향상시키는 방법을 소개한다. 간단하게 몇 가지 예시를 주는 방식으로 만든 COT 프롬프팅으로도 LLM의 추론 능력이 향상되었다.Arithmetic, Commonsence, Symbolic Reasoning 에서 더 좋은 퍼포먼스를 보였으며 PaLM 5..
 ConvMixer: Patches Are All You Need?
ConvMixer: Patches Are All You Need?
Asher Trockman, J.Zico Kolter. Carnegie Mellon University and Bosch Center for AI. (2022.01.24) Abstract CNN이 vision task에서 지배적인 아키텍처였으나 최근 ViT가 SOTA를 달성 self-attentoin의 quadratic runtime의 한계로 large images를 처리하기 위해 patch embedding을 사용한다. 여기서 질문, ViT의 성능은 Transformer 아키텍처로 인한 것인가? 아니면 input representation으로 patch를 사용한 것이 영향을 끼쳤는가? 논문은 후자에 대한 증거를 제시한다 patch를 바로 input으로 받는 MLP-Mixer, 같은 resolution을..
 StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila NVIDIA. (2019.12) Abstract StyleGAN은 unconditional data-driven 이미지 생성 SOTA 달성 모델 StyleGAN의 특징적인 아티팩트를 분석하고 이를 해결하기 위한 아키텍처와 학습방법을 제안 generator의 normalization을 새로 디자인, progressive growing을 재고(resolution을 증가시키며 학습하는 것), generator regularization을 통해 latent code에서 image로의 매핑을 개선 path length regularizer는 이미지 퀄리티를 개선할..
 ConvNeXt: A ConvNet for the 2020s
ConvNeXt: A ConvNet for the 2020s
[convnext] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, Facebook AI Research (FAIR), UC Berkeley (2022.01.02) Abstract 2020년도에 ViT는 이미지 분류 SOTA 모델로 CNN을 대체 하지만 vanilla ViT는 object detection 또는 semantic segmentation과 같은 general computer vision task에 적용하는데 어려움을 겪음 Swin Transformer와 같은 계층적 Transformer는 여러 vision task에서 좋은 성능을 냄 하지만 이러한 hybrid 접근의 유효성은 c..
 MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer: An all-MLP Architecture for Vision
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy. Google Research, Brain Team. (2021.05) Abstract CNN은 vision task에서 널리 사용되었음, 최근에는 ViT와 같이 attention-based networks도 사용 convolution과 attention는 좋은 성능을 내기 위한 필수조건이 아님 오직 multi-layer perceptrons을 사용한 MLP-..
 MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen Google Inc. CVPR Abstract 다양한 task, model size에서 mobile model SOTA를 달성한 MobileNetV2를 제시 SSDLite를 사용한 object detection, DeepLabv3 기반 semantic segmentation에서 MobileNetV2를 사용 thin bottle neck layers 간 shortcut connection에서 inverted residual structure를 사용 intermediate expansion layer는 lightweight depthwise convolution을 사용 narr..
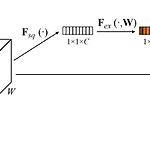 Squeeze-and-Excitation Networks (SE-Net)
Squeeze-and-Excitation Networks (SE-Net)
Abstract CNN의 메인 블록은 spatial, channel-wise information를 각 layer의 local receptive fields에서 결합하여 정보를 가지고 있는 feature를 만든다. 이전 연구들은 spatial encoding을 강화하는데 집중하였지만 저자는 channel relationship에 집중하여 "Squeeze-and-Excitation"(SE) block을 제시 SE block은 adaptive 하게 channel-wise feature를 recalibrate(재교정, 재보정)한다. computational cost가 크지 않으며 ILSVRC에서 1등을 차지 1. Introduction CNN은 필터들은 spatial, channel-wise 정보를 함께 사용..
 Attention Mechanism
Attention Mechanism
Attention seq2seq 모델에서 RNN, LSTM, GRU 모두 초기시점의 정보가 희석되고 Decoder로 전달되는 Encoder의 마지막 hidden state (+ cell state) 하나에 모든 Encoder의 input의 정보를 담기가 어려워 정보 손실이 일어난다. 이를 해결하기 위해 seq2seq 모델에서 Decoder에서 output 각각의 계산이 모두 Encoder의 hidden state를 참고하여 이루어지는 Attention Mechanism이 제시되었다. 기계번역의 예시에서 Encoder가 특정 단어를 input으로 받아 도출한 output은 상응하는 단어를 번역하는 Decoder가 예측을 하는데 필요한 input과 유사할 것이라는 가정하에 만들어진 Attention Mech..