
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Few-shot generation
- GAN
- 딥러닝
- WinAPI
- 디퓨전모델
- motion matching
- ddpm
- WBP
- 오블완
- userwidget
- RNN
- Font Generation
- Stat110
- animation retargeting
- 생성모델
- multimodal
- deep learning
- UE5
- cv
- 폰트생성
- Diffusion
- NLP
- Unreal Engine
- 언리얼엔진
- BERT
- ue5.4
- CNN
- Generative Model
- 모션매칭
- dl
- Today
- Total
목록NLP (14)
Deeper Learning
 GraphCodeBERT: Pre-training Code Representations with Data Flow
GraphCodeBERT: Pre-training Code Representations with Data Flow
Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang and Ming Zhou [School of Computer Science and Engineering, Sun Yat-sen University, Beihang University, Peking University, Harbin Institute of Technology, Microsoft Research Asia, ..
 CodeBERT:A Pre-Trained Model for Programming and Natural Languages
CodeBERT:A Pre-Trained Model for Programming and Natural Languages
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, Ming Zhou, [Research Center for Social Computing and Information Retrieval, Harbin Institute of Technology, China, The School of Data and Computer Science, Sun Yat-sen University, China, Microsoft Research Asia, Beijing, China, Microsoft Search Technology Center Asia, Beijing, C..
 Longformer: The Long-Document Transformer
Longformer: The Long-Document Transformer
Iz Beltagy, Matthew E. Peters, Arman Cohan [Allen Institute for Artificial Intelligence, Seattle, WA, USA] (2020.04) Abstract Transformer 기반 모델은 sequence 길이에 따라 quadratic 하게 증가하는 계산 복잡도를 가지는 self-attention 연산으로 인해 긴 sequence를 처리하지 못하였다 sequence length에 따라 선형적으로 계산량이 증가하여 수천 개 이상의 토큰을 처리할 수 있는 Longformer를 제시 Longformer의 attention 메커니즘은 drop-in replacement, local windowed attention text8, enwik8에서..
 DeBERTa: Decoding-enhanced BERT with Disentangled Attention
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, [Microsoft Research, Microsoft Dynamics 365 AI] (2020.06) Abstract 두 새로운 테크닉으로 BERT, RoBERTa를 향상한 새로운 모델 아키텍처 **DeBERTa(Decoding-enhanced BERT with disentangled attention)**을 제시 첫 번째 테크닉은 disentangled attention mechanism 각 단어는 content와 position을 각각 encode하는 2개의 벡터로 표현 단어끼리의 attention weight 또한 content, relative position 각각에 disentangled matr..
 T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu [Google] (2019.10) Abstract Transfer learning은 NLP에서 강력한 기술로 부상하였다 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understandi..
 BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer [Facebook AI] (2019.10) Abstract sequence-to-sequence model을 사전학습시키기 위한 denoising autoencoder BART를 제시 BART는 text를 임의의 noise 함수로 corrupt시키고 모델은 corrupted text를 다시 original text로 재구성하는 방식으로 학습 기본 Transformer 기반 neural machine translation 아키텍처를 사용한 단순한 구조임에도 BERT, GPT 등 여러 최근 사..
 ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, [Google Brain] [Stanford University] (2020.03) Abstract Masked language modeling (MLM)은 input의 몇몇 token을 [MASK] token으로 바꾸고 원래 token을 재구성하는 방식으로 학습 MLM으로 학습한 모델은 downstream NLP task에 전이학습 하였을 때 성능 향상이 있었으나 효과를 보기 위해서는 많은 계산량을 요구한다 (비효율적인 sampling) 대안으로 저자는 sample-efficient pre-training task인 replaced token detection을 제시한다 token을 ..
 ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut, [Google Research][Toyota Technological Institute at Chicago], (2019.09) Abstract 자연어 표현을 사전학습 시킬 때 model size를 키우면 대체로 downstream task의 성능이 향상된다 하지만 model이 커짐에 따라 training time과 GPU, TPU memory 한계의 문제를 겪게 됨 이러한 문제를 해결하기 위해 BERT보다 더 적은 memory를 소모하고 학습 속도가 빠른 ALBERT를 제시 inter-sentence coherence를 모델링하기 위해 self..
 RoBERTa: A Robustly Optimized BERT Pretraining Approach
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, Facebook AI, (2019.07) Abstract 언어모델 사전학습은 큰 성능향상을 가져오지만 여러 접근법에 대한 비교가 어려움 BERT의 여러 주요 hyperparameters, training data size의 효과를 정밀하게 측정한 replication study를 제시 BERT가 undertrained 되었고 성능향상의 여지가 있음을 확인 저자가 제시한 모델은 GLUE, RACE, SQuAD에서 SOTA를 달성 1. Introduction ELMo, GPT..
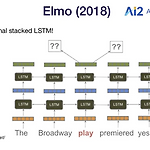 ELMo (Embeddings from Language Model)
ELMo (Embeddings from Language Model)
Beyond Embeddings Word2Vec, Glove 임베딩은 13~14년에 인기 많은 task에서 좋은 성능을 보였음 Problem: representations are shallow 첫 번째 layer만 all Wikipedia data로 pretrained한 embedding의 이점을 가짐 나머지 layer (LSTMs)는 pretrained data를 보지 못하고 own data로만 학습됨 Bank Account와 River Bank에서 Bank는 전혀 다른 의미를 가지지만 Word2Vec 또는 Glove로는 이를 반영하지 못하고 Bank가 같은 벡터로 임베딩 되어 사용됨 문맥을 반영한 워드 임베딩 (Contextualized Word Embedding)이 필요하다. → embedding ..
 XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNet XLNet은 구글 연구팀이 발표한 모델로 당시 SOTA를 여러 자연어 처리 태스크에서 달성하였다. Transformer-XL을 개선한 모델로 eXtra Long Network로 트랜스포머 모델보다 더 긴 문맥을 볼 수 있다. AE방식의 언어모델인 BERT의 장점과 AR방식의 언어 모델인 GPT의 장점을 갖춘 Permutation language modeling을 사용함. BERT에는 몇가지 한계가 존재한다. MASK 토큰이 독립적으로 예측됨 Token 사이의 관계 학습이 불가능하다 ( 서로 독립적이라는 가정하에 있음 ) Embedding length의 제한으로 Segment 간 관계 학습 불가능 예를 들어 New York is the city 라는 시퀀스에서 New York 두 토큰이 [MAS..
 BERT (Bidirectional Encoder Representations from Transformers)
BERT (Bidirectional Encoder Representations from Transformers)
BERT BERT는 구글에서 개발한 언어 모델로 2018년 10월 논문 출시 후 다수의 NLP 태스크에서 SOTA를 기록하였다. BERT는 Transformer 기반 모델로 Encoder 부분만을 사용한다. Input은 두 개의 문장을 tokenizer를 사용하여 토큰화 시키고 문장의 시작에 special token인 [CLS]를 추가하고 두 문장 사이와 두 번째 문장의 끝에 [SEP] 토큰을 삽입한다. BERT의 input embedding은 input sentence의 tokenizing 형태인 token embedding, 앞 문장, 뒷 문장을 0 or 1로 나타내는 Segment Embedding, RNN과 달리 poistiion정보가 내포되어있지 않기 때문에 이를 위해 추가한 Position e..
 GPT
GPT
Self-Supervised Pre-Training Models 문서 분류, 감성 분석, 질의응답, 문장 유사성 파악, 원문함의 등 과제는 각각 주어진 과제에 알맞은 처리가 완료된 데이터가 필요하다. 미분류 corpus의 경우 매우 많으나 특정 목적을 위해 Labeling, 전처리가 완료된 데이터는 현저히 부족하다. 미분류 corpus를 사용하여 언어 모델을 학습시키고 특정 목적에 맞게 fine-tuning 하는 것으로 이를 어느 정도 해결할 수 있다. 비지도 학습인 미분류 corpus로 학습한 언어모델과 이를 supervised fine-tuning 하는 Self-supervised pre-training을 통해 언어이해(NLU)를 달성하는 것이 GPT의 목적이다. GPT-1 GPT-1은 OpenAI에..
 Text similarity Model (CNN, MaLSTM)
Text similarity Model (CNN, MaLSTM)
텍스트 유사도 측정 자연어 처리에서 텍스트 유사도 문제는 Document의 유사도를 측정할 수 있는 모델을 만들어 해결이 가능하다. 두 질문이 유사한 질문일 경우 1, 아닐 경우 0으로 labeling 된 Quora Question Pairs 데이터셋을 CNN, MaLSTM 2가지 모델을 사용하여 텍스트 유사도를 측정해보겠다. Preprocessing 위와 같이 train 데이터는 2개의 질문인 question1, question2와 label인 is_duplicate로 이루어져 있다. Corpus의 특성상 ?와 : 같은 특수문자가 많아 정규표현식을 사용하여 영문을 제외한 특수문자나 숫자를 공백으로 대체한다. DataFrame에서 question1과 question2를 각각 list로 추출하여 할당하고 ..