
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- userwidget
- dl
- Stat110
- NLP
- multimodal
- 언리얼엔진
- WBP
- Unreal Engine
- 폰트생성
- Font Generation
- deep learning
- RNN
- Few-shot generation
- 모션매칭
- 디퓨전모델
- 생성모델
- ddpm
- WinAPI
- cv
- BERT
- motion matching
- CNN
- GAN
- Diffusion
- ue5.4
- Generative Model
- 오블완
- animation retargeting
- UE5
- 딥러닝
- Today
- Total
목록RNN (6)
Deeper Learning
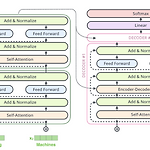 Attention is all you need: Transformer
Attention is all you need: Transformer
Transformer 트랜스포머 모델은 기존의 seq2seq 모델에서 Encoder, Decoder 형태를 유지하면서 RNN을 사용하지 않고 어텐션 스코어를 중심으로 학습을 하는 모델이다. 기존 Attention 모델에서 seq2seq의 Encoder가 Decoder로 정보를 전달할 때 hidden state에 정보를 모두 담기가 어렵고 시점에 따른 정보 희석의 문제를 해결하기 위해 어텐션 스코어를 사용하여 이를 보정하였다면 트랜스포머 모델은 어텐션 스코어 자체를 Encoder와 Decoder사이의 연결점으로 사용한다. Multi-head-Self-Attention 트랜스포머 모델은 셀프 어텐션을 통해 계산한 어텐션 스코어를 사용하기 때문에 먼저 셀프 어텐션에 대해 알아보겠다. 셀프 어텐션은 한 문장에서..
 Attention Mechanism
Attention Mechanism
Attention seq2seq 모델에서 RNN, LSTM, GRU 모두 초기시점의 정보가 희석되고 Decoder로 전달되는 Encoder의 마지막 hidden state (+ cell state) 하나에 모든 Encoder의 input의 정보를 담기가 어려워 정보 손실이 일어난다. 이를 해결하기 위해 seq2seq 모델에서 Decoder에서 output 각각의 계산이 모두 Encoder의 hidden state를 참고하여 이루어지는 Attention Mechanism이 제시되었다. 기계번역의 예시에서 Encoder가 특정 단어를 input으로 받아 도출한 output은 상응하는 단어를 번역하는 Decoder가 예측을 하는데 필요한 input과 유사할 것이라는 가정하에 만들어진 Attention Mech..
 Text similarity Model (CNN, MaLSTM)
Text similarity Model (CNN, MaLSTM)
텍스트 유사도 측정 자연어 처리에서 텍스트 유사도 문제는 Document의 유사도를 측정할 수 있는 모델을 만들어 해결이 가능하다. 두 질문이 유사한 질문일 경우 1, 아닐 경우 0으로 labeling 된 Quora Question Pairs 데이터셋을 CNN, MaLSTM 2가지 모델을 사용하여 텍스트 유사도를 측정해보겠다. Preprocessing 위와 같이 train 데이터는 2개의 질문인 question1, question2와 label인 is_duplicate로 이루어져 있다. Corpus의 특성상 ?와 : 같은 특수문자가 많아 정규표현식을 사용하여 영문을 제외한 특수문자나 숫자를 공백으로 대체한다. DataFrame에서 question1과 question2를 각각 list로 추출하여 할당하고 ..
 Beam Search
Beam Search
Why Beam Search? 기계번역, 이미지 캡션 생성 등 ˆy가 둘 이상의 연속적인 Sequence가 되는 Decoder 형태의 모델에서 예측된 값은 다음 예측을 위한 input 값으로 피딩 된다. 위의 예시에서 Greedy Search를 사용하면 빠른 속도로 예측 과정이 완료되나 하나의 예측만을 고려하기 때문에 minor 한 변화에 영향을 받지 않아 최적의 예측을 하지 못활 확률이 Beam Seach보다 높다. 따라서 여러가지 예측을 하는 Beam Search를 사용한다. Beam Search vocab size가 10000인 예시에서 Encoder 부분을 지나고 처음으로 예측이 이루어지는 부분에서 구해야 하는 값은 argmaxyP(y|x)이다. ($y..
 Word2Vec
Word2Vec
Word Embedding Vocabulary를 사용하여 One-hot encoding을 통해 비정형 텍스트 데이터를 수치형 데이터로 전환하여 input으로 사용이 가능하다. 하지만 오직 index하나로 단어의 정보를 표현하고 특정 단어의 index를 제외하고 모두 0으로 이루어진 one-hot vector를 사용하여 생기는 데이터의 Sparsity는 통계적 모델의 성공적인 학습을 방해한다. 특정 단어의 학습이 그 단어와 유사한 단어의 학습과 전혀 다른 과정이 되기 때문에 단어 간의 유사성의 학습이 쉽지 않다. 따라서 Word Embedding이 필요하다. Vocabulary의 size가 100,000 일 때 100,000 차원의 one-hot vector가 만들어진다. 하지만 Word Embedding..
 Recurrent Neural Network
Recurrent Neural Network
Vocabulary Recurrent Neural Network(이하 RNN)은 주로 비정형 문자 데이터를 다루는데 사용된다. 딥러닝 신경망 알고리즘의 적용을 위해 비정형 데이터는 수치형 데이터로 전환되어야 한다. Lorem ipsum dolor sit amet. consectetur adipiscing elit. 위와 같은 문장 2개가 데이터로 주어졌을 때 이를 수치형 데이터로 변환하기 위해 간단한 Vocab을 만들면 다음과 같다. 첫 번째 문장에 Vocabulary를 사용하여 One-hot encoding을 적용한다. 각 행은 단어를 나타내고 각 열은 vocab의 단어의 출현 여부를 1 또는 0으로 나타낸다. 이와 같이 수치로 변환한 텍스트 데이터를 input으로 모델을 학습시킬 수 있다. Seque..