
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- ue5.4
- Diffusion
- 딥러닝
- Unreal Engine
- multimodal
- userwidget
- Few-shot generation
- cv
- 생성모델
- BERT
- deep learning
- GAN
- motion matching
- Generative Model
- 오블완
- RNN
- 언리얼엔진
- 모션매칭
- WinAPI
- dl
- Stat110
- 폰트생성
- UE5
- WBP
- CNN
- Font Generation
- NLP
- animation retargeting
- ddpm
- 디퓨전모델
- Today
- Total
Deeper Learning
Attention is all you need: Transformer 본문
Transformer
트랜스포머 모델은 기존의 seq2seq 모델에서 Encoder, Decoder 형태를 유지하면서 RNN을 사용하지 않고 어텐션 스코어를 중심으로 학습을 하는 모델이다.
기존 Attention 모델에서 seq2seq의 Encoder가 Decoder로 정보를 전달할 때 hidden state에 정보를 모두 담기가 어렵고 시점에 따른 정보 희석의 문제를 해결하기 위해 어텐션 스코어를 사용하여 이를 보정하였다면 트랜스포머 모델은 어텐션 스코어 자체를 Encoder와 Decoder사이의 연결점으로 사용한다.
Multi-head-Self-Attention
트랜스포머 모델은 셀프 어텐션을 통해 계산한 어텐션 스코어를 사용하기 때문에 먼저 셀프 어텐션에 대해 알아보겠다.
셀프 어텐션은 한 문장에서 단어끼리 얼마나 관계가 있는지 계산하여 어텐션 스코어를 도출해낸다.
임베딩된 2개의 단어 벡터에서 구한 Query vector, Key vector를 내적 하여 어텐션 스코어를 계산한다.
feature차원(=embedding 차원, d_model)의 제곱근으로 이를 나누어 스케일을 조정하고 소프트맥스 함수를 사용하여 확률 값으로 변환한 후 이를 각 Value vector와 곱하고 모두 더하면 query에 대한 context vector를 구할 수 있다.

셀프 어텐션은 기존 어텐션과 다르게 Encoder또는 Decoder의
Query: 특정 timestep의 input token (hidden state)
Key: 모든 timestep의 input token (hidden state)
Value: 모든 timestep의 input token (hidden state)
와 같은 형식으로 입력 시퀀스간의 가중치를 반영하는 것이 가능하다.


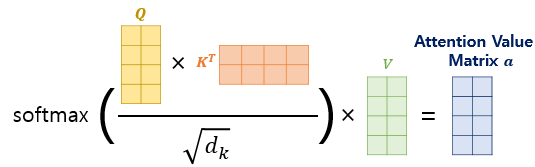
행렬 연산으로 이를 일괄적으로 처리할 수 있다.
Multi-head-self-attention
멀티 헤드 어텐션의 과정은 크게 5가지 단계로 요약이 가능하다.
- WQ, WK, WV에 해당하는 d_model 크기의 Dense layer를 지나게 한다.
- 지정된 헤드 수만큼 나눈다(split).
- Scaled dot product attention.
- 나눠졌던 헤드들을 연결(concatenatetion)한다.
- WO에 해당하는 Dense layer를 지나게 한다.

Uni-Head Attention
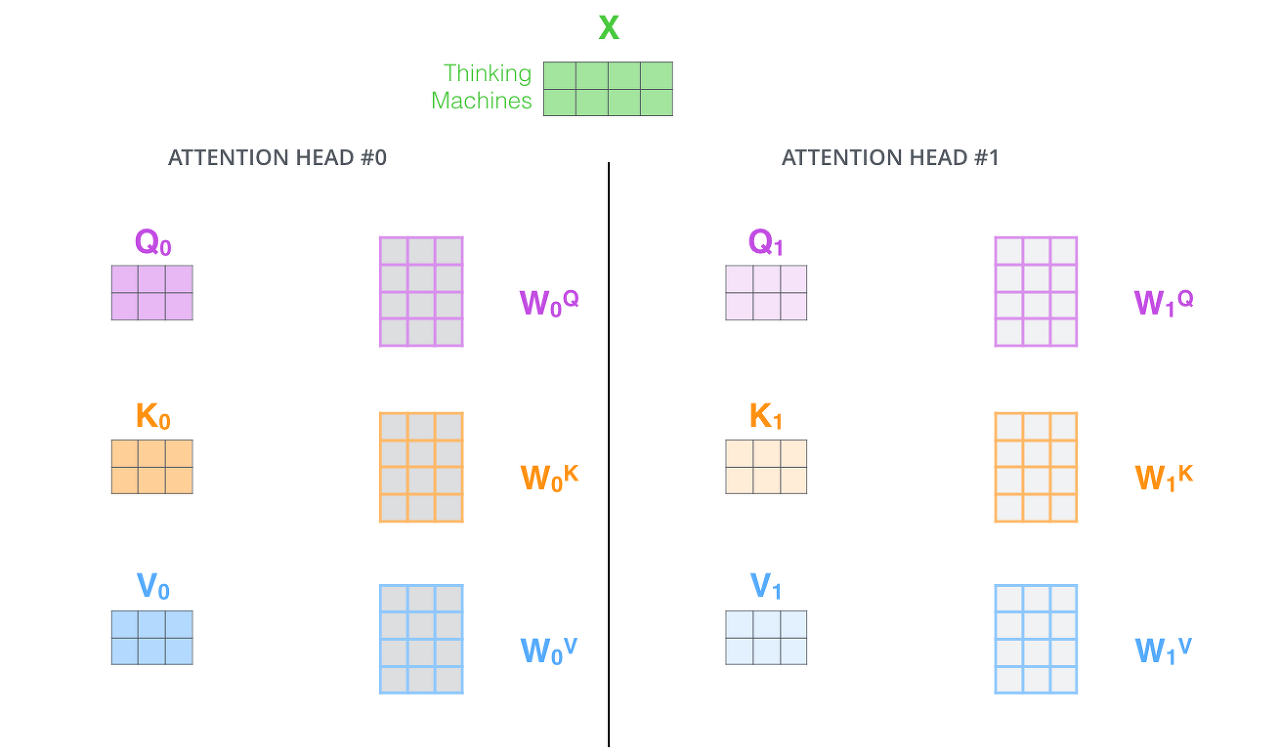
멀티헤드 셀프 어텐션은 다음과 같이 Dense Layer를 통과한 벡터가 여러 개의 heads를 가지도록 형태를 변경한다.
q : (batch_size, query의 문장 길이, d_model)
k : (batch_size, key의 문장 길이, d_model)
v : (batch_size, value의 문장 길이, d_model)
-->
q : (batch_size, num_heads, query의 문장 길이, d_model/num_heads)
k : (batch_size, num_heads, key의 문장 길이, d_model/num_heads)
v : (batch_size, num_heads, value의 문장 길이, d_model/num_heads)
논문에서는 feature가 512d인 q, k, v 벡터를 8개의 헤드로 나누어 64d로 reshape 하였다.
heads를 여러 개 생성하는 이유는 여러 개의 헤드가 모두 다른 시각 (나누어진 벡터)으로 Attention을 분석하기 때문에 이 정보를 모두 concatenate 하여 압축한 context vector는 기존의 하나의 head로 이루어진 셀프 어텐션 보다 더 다양한 시각의 정보를 가지고 있고 이는 모델 성능을 향상시키기 때문이다.

이렇게 구한 num_heads개의 vector를 concatenate 한 후 Dense layer를 사용하여 다시 feature의 차원이 d_model인 벡터로 변환한다.
Positional Encoding
RNN 모델을 사용하지 않기 때문에 순차적으로 Encoder의 정보가 Decoder로 전달되지 않는다.
따라서 순서 정보를 따로 추가하여야 하는데 이를 해결하기 위해 Positional Encoding을 사용한다.
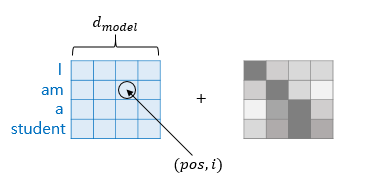
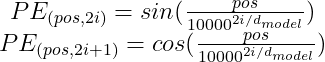
Position-wise Feedforward Neural Network (FFNN)

포지션-와이즈 피드 포워드 뉴럴 네트워크(FFNN)는 Self-attention의 context를 input으로 하는 2개의 Hidden layer를 사용하며 첫 hidden layer의 activation function이 relu인 신경망이다.
FFNN을 사용하는 이유는 Self-attention을 통과한 context vector는 Embedding의 관점으로 볼 수 있으며 이는 또 다른 형태의 Input 이다.
기본적인 복층의 NN을 예시로 들면 Multi-Head-Self-Attention은 Input을 준비하는 과정이며 FFNN이 hidden layer가 되는 것이다.
Residual Connection

기존의 Supervised Learning에서 H(x)-y를 최소화하는 최적의 H(x)를 찾는 방식으로 학습이 이루어진다.
Residual Learning은 잔차에 대한 학습으로 기존 Networks를 H(x) - x를 찾는 방식으로 수정하면 Weight는 H(x) - x를 찾도록 학습이 된다.
F(x) = H(x) - x 라고 하면 Weights는 F(x)를 찾도록 학습이 되며 출력 H(x) = F(x) + x가 된다.
이에 따라 수정한 Networks의 구조는 위와 같다.
H(x) - x를 최소화하려는 방향으로 학습이 이루어지면 F(x)는 0에 가까워져야 하며 이는 입력의 작은 변화를 쉽게 검출할 수 있는 효과를 가진다.
Encoder
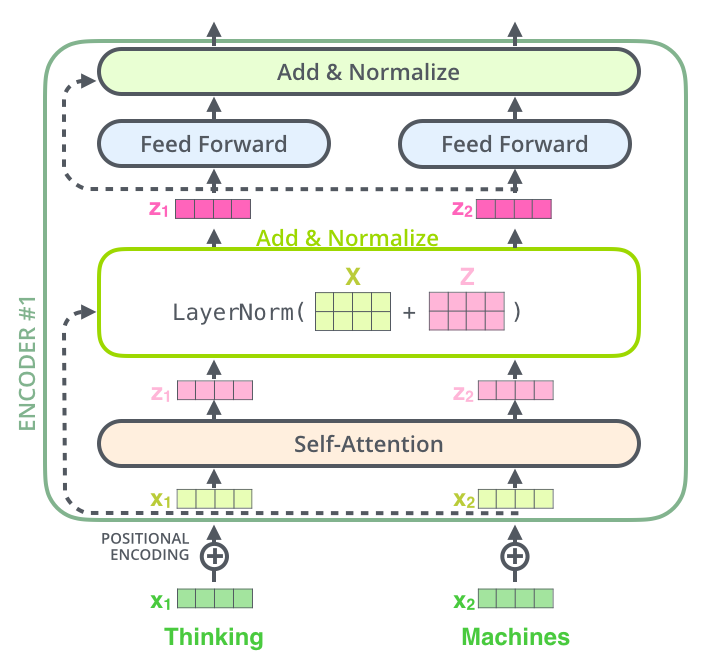
Layer Normalization은 Batch Normalization을 하나의 Layer 단계에서 해당하는 뉴런들에게 적용한다고 생각하면 된다.
위에 설명한 Positional-Encoding, Multi-Head-Self-Attention, Residual Connection, FFNN을 모두 적용하여 위와 같은 구조로 하나의 Encoder layer가 완성된다.
Encoder layer를 여러층으로 쌓아서 Encoder가 완성된다.
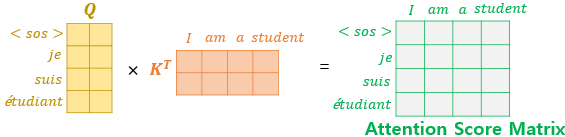
Subsequent Masked Attention
Decoder의 첫 Self-Attention의 경우 Encoder의 그것과 다른 점이 있다.
따라서 기존의 Self-Attention을 그대로 사용하면 현재 timestep보다 뒤 timestep의 embedding vector를 필요로 한다.


위의 예시에서 보면 Training 단계에서 Decoder의 input과 target은 다음과 같다.
input=[<sos>, je, suis, etudiant]
target=[je, suis, etudiant, <eos>]
input의 je를 사용하여 다음 단어를 예측할 때 suis, etudiant와의 유사성을 사용하여 계산한 부분을 사용해서는 안된다.
따라서 매우 작은 음수 값을 Attention score matrix의 검은색 부분에 더해준다.
Softmax를 통과하면 이는 0에 매우 근접한 값으로 바뀐다.
Transformer Inference step
- encoder에는 full sequence가 들어간다.
- decoder의 input으로는 먼저 <sos> 토큰만 들어가며 output으로 나온 토큰은 다음으로 decoder input에 추가되어 들어간다.
- 1 step
- encoder input: full sequence
- decoder input: <sos>
- output = 'The'
- 2 step
- encoder input: full sequence
- decoder input: <sos> 'The'
- output = 'Attention'
- Seq2seq의 끝을 알리는 token인 <EOS> 토큰이 나올 때 까지 이를 반복한다.
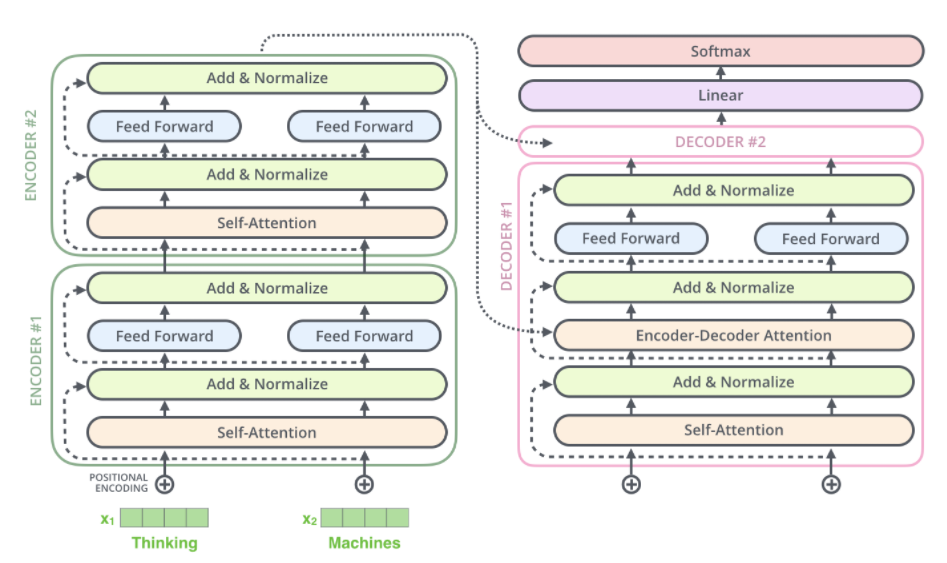
Encoder-Decoder Attention
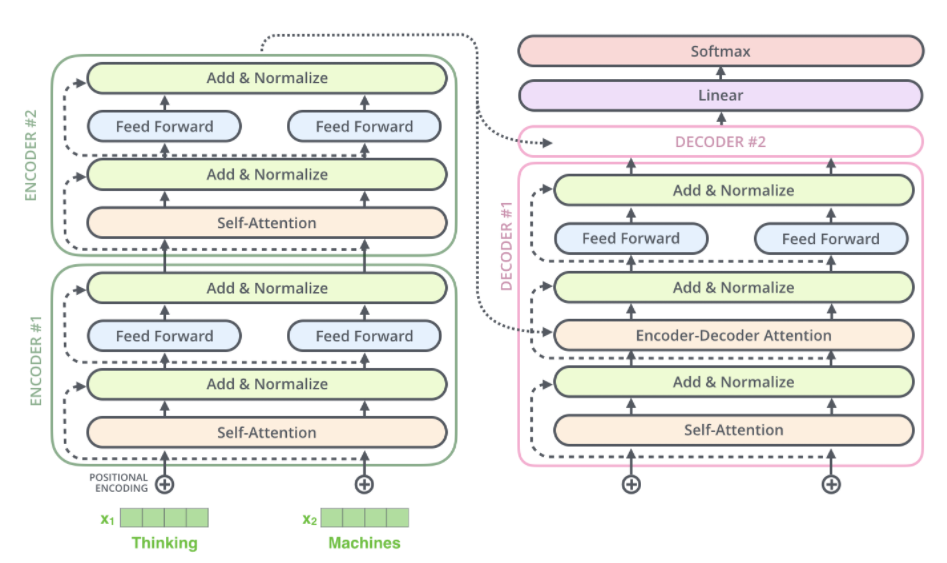
Encoder-Decoder Attention은 Key와 Value로 Encoder의 output을 사용하며 Query는 Decoder의 Self-Attention과 Add&Noramlize layer를 통과한 output이다.

위의 수식을 통해 계산하면 Encoder의 output을 Key와 Value로 하는 Attention이 반영된 Query의 Context vector를 구할 수 있다.
Encoder와 마찬가지로 Decoder도 여러층을 쌓을 수 있으며 마지막으로 본래 vocab size와 같은 수의 units을 가진 Dense layer를 사용하고 softmax 함수를 통해 output은 각 단어에 대한 예측 확률이 된다.
Loss 함수는 다중 분류 문제로 Categorical CrossEntropy를 사용한다.
Reference
[1] Ashish Vaswani et al. (2017). Attention Is All You Need. arXiv:1706.03762
[2] Jimmy Lei Ba et al. (2016). Layer Normalization. arXiv:1607.06450
[3] 딥 러닝을 이용한 자연어 처리 입문: 트랜스포머 wikidocs.net/31379
[4] Jay Alammar 'The Illustrated Transformer', jalammar.github.io/illustrated-transformer/
'AI > Deep Learning' 카테고리의 다른 글
| CBAM: Convolution Block Attention Module (0) | 2021.10.24 |
|---|---|
| Squeeze-and-Excitation Networks (SE-Net) (0) | 2021.10.14 |
| ELMo (Embeddings from Language Model) (0) | 2021.10.08 |
| Full Stack Deep Learning - Lecture 1 ~ 3 (0) | 2021.10.07 |
| Universal Approximation Theorem (0) | 2021.10.02 |



