
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
Tags
- 디퓨전모델
- Few-shot generation
- multimodal
- 생성모델
- RNN
- UE5
- BERT
- GAN
- Generative Model
- animation retargeting
- Font Generation
- ue5.4
- CNN
- 딥러닝
- deep learning
- Diffusion
- dl
- Stat110
- 언리얼엔진
- motion matching
- NLP
- cv
- Unreal Engine
- 폰트생성
- WBP
- ddpm
- userwidget
- WinAPI
- 모션매칭
- inductive bias
Archives
- Today
- Total
Deeper Learning
Squeeze-and-Excitation Networks (SE-Net) 본문
Abstract
- CNN의 메인 블록은 spatial, channel-wise information를 각 layer의 local receptive fields에서 결합하여 정보를 가지고 있는 feature를 만든다.
- 이전 연구들은 spatial encoding을 강화하는데 집중하였지만 저자는 channel relationship에 집중하여 "Squeeze-and-Excitation"(SE) block을 제시
- SE block은 adaptive 하게 channel-wise feature를 recalibrate(재교정, 재보정)한다.
- computational cost가 크지 않으며 ILSVRC에서 1등을 차지
1. Introduction
- CNN은 필터들은 spatial, channel-wise 정보를 함께 사용하여 input channels을 따라 인접한 spatial connectivity patterns 나타낸다.
- features 간 spatial correlations을 잡아내는 연구가 이전에 있었다. 이 논문에서는 relationship between channels에 집중
- conv features의 채널 간 interdependencies를 따로 모델링하여 network의 representation의 퀄리티를 높이는 SE block을 제시

- squeeze operation
- feature U에 먼저 squeeze operation을 적용
- spatial dimensions(HxW)를 통합하여 1x1xC의 channel descriptor를 만든다.
- channel descriptor는 각 채널의 global distribution의 임베딩
- excitation operation
- 간단한 self-gathing mechanism (input은 임베딩 벡터, output은 각 채널별 weight)
- 만들어진 각 채널별 weight는 feature map U와 곱하여 채널 간 feature를 recalibration
- SE block의 구조가 동일해도 earlier layer와 later layer에서 다른 일을 수행한다.
- earlier layer에서는 class-agnostic manner(class에 상관없이)하게 공유되는 저수준의 표현을 강화한다.
- layer layer에서는 점점 specialised되어 다른 input들에 대해 highly class-specific manner(class에 따라)로 응답
- 결론적으로 SE block에 의해 얻을 수 있는 feature recalibration의 장점은 누적될 수 있다.
- 새로운 CNN 아키텍쳐를 디자인하는 것은 매우 어려우나 SE block은 쉬우며 효과적으로 성능을 끌어올린다.
- ILSVRC 2017 분류 competition에서 1등을 기록
2. Related Work
- VGGNets, Inception modules은 network를 깊게 하면 학습에 도움이 되는 representation의 퀄리티를 향상시킬 수 있다.
- BN의 regulating으로 안정적인 학습, smoother optimisation surfaces
- ResNet, Highway networks
- Grouped convolutions은 학습된 transformation의 cardinality를 증가시키는 접근
- multi-branch convolutions
- 이전 연구들은 대부분 model의 크기와 계산량을 줄이기 위한 것이 cross-channel correlation을 다루는 목적이었으며 채널간 관계가 local receptive field에서 instance-agnostic function의 조합으로 정의될 수 있다는 가정이 있다.
- 예시로 1x1 conv는 kernel의 weight를 모든 input에 대해 instance-agnostic하게 적용할 수 있다는 가정이 있음.
- 하지만 저자는 SE block은 global information을 사용하여 채널 간 dynamic, non-linear dependency를 명시적으로 모델링하여 학습을 더 용이하게 하며 네트워크의 representational power를 향상시킬 수 있다고 주장하였다.
- Hourglass modules
- Attention
3. Squeeze-and-Excitation Blocks

- $F_{tr}$ 은 X를 U로 매핑하며 learned filter set을 V = [v1, v2, v3, ..., vC] 라고 하였을 때 아래와 같다

- *는 convolution 연산을 뜻한다
- output이 channel 간 sum으로 구해지기 때문에 channel dependencies는 간접적으로 $v_c$ 에 임베디드 되어있다.
- 하지만 filter가 파악한 local spatial correlation 또한 함께 혼재되어 임베디드 되어있다.
- convolution에 의해 도출된 채널 간 관계는 지역적이며 함축적.
- 채널 interdependencies를 explicit 하게 모델링하여 네트워크가 informative features에 더 민감하게 작동할 수 있도록 SE block사용
- squeeze, excitation을 사용하여 global information에 접근하고 recalibrate filter responses를 하도록 함
3.1 Squeeze: Global Information Embedding
- normal CNN의 경우 learned filter가 local receptive field를 사용하기 때문에 region 밖의 contextual information을 사용할 수 없다.
- 이 문제를 해결하기 위해 global spatial information을 channel descriptor로 SQUEEZE
- 논문에서는 GAP를 사용하여 채널 와이즈 통계 값을 뽑아낸다.
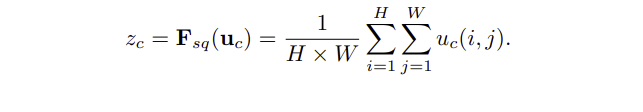
3.2 Excitation: Adaptive Recalibration
- 채널 간 의존성을 모두 capture 하기 위해 EXCITATION을 사용
- 위 목적을 달성하기 위해 2가지 조건이 필요하다.
- flexible
- 채널 간 nonlinear interaction을 학습할 수 있어야 함
- must learn a non-mutually-exclusive relationship
- 여러 채널을 강조할 수 있어야 하기 때문에 상호 배타적으로 하나의 채널을 강조해서는 안됨
- flexible
- 위 조건을 만족하기 위해 간단한 sigmoid activation을 사용한 gathing mechanism을 도입

- δ는 ReLU, $W_1$은 C dim의 Z를 C / r dim으로 $W_2$는 C / r dim의 $W_1z$ 를 다시 C dim으로 복원한다. r은 reduction ratio

- excitation opt를 통해 구한 scalar s를 feature map u에 channel-wise multiple
3.3 Instantiations
- SE block은 convolution, non-linearity 연산 후 어느 모듈에도 적용이 가능하다.

- SE-Inception Module에서는 Inception Module 자체가 X를 U로 바꾸는 $F_{tr}$
- SE-ResNet Module에서는 $F_{tr}$ 이 non-identity branch의 convolution layer
- Squeeze, Excitation 모두 identity branch와 더해지기 전에 적용
- ResNeXt, Inception-ResNet, MobileNet, ShuffleNet에 모두 적용 가능
4. Model and Computational Complexity
- SE block은 모델의 복잡도를 크게 증가시키지 않고 모델의 성능을 향상시킬 수 있도록 디자인되었다
- ResNet-50에서 forward & backward single pass가 190 ms, SE-ResNet-50에서는 209ms가 소요될 정도로 효율적이다
- 추가 parameters는 gating 알고리즘에 사용되는 2개의 FC layer의 parameters가 전부이며 그 수는 다음 식과 같다. (S= stages, C_s = output dim, N_s = repeated blocks for stage s)


5. Experiments

6, 7 Ablation Study, Role of SE Blocks


정리
- CNN은 spatial, channel-wise가 entangled 되어 있는 형태로 채널에 정보가 implicit 하게 임베딩 되어있다.
- 명시적으로 채널 간 interdependency를 모델링하여 network의 representation power를 높이기 위해 SE-block을 제시
- SE-block은 squeeze에서 global information을 얻기 위해 GAP를 사용, 전역적인 채널 정보를 담고 있는 임베딩 벡터를 만든다.
- Excitation에서 2개의 FC layer를 사용하여 채널 간 interdependency를 adaptive 하게 capture, weight를 뽑아냄
- 이를 channel-wise mul을 통해 recalibrated feature map을 얻는다.
- 기존 CNN은 input에 따라 adaptive하게 작동하지 않지만 SE-Net은 SE-block을 사용하여 뽑아낸 weight를 사용하여 Channel 방향으로 attention을 수행한다.
Reference
[1] https://arxiv.org/pdf/1709.01507.pdf Squeeze-and-Excitation Networks
'AI > Deep Learning' 카테고리의 다른 글
| U-GAT-IT: Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation (0) | 2021.10.27 |
|---|---|
| CBAM: Convolution Block Attention Module (0) | 2021.10.24 |
| Attention is all you need: Transformer (0) | 2021.10.10 |
| ELMo (Embeddings from Language Model) (0) | 2021.10.08 |
| Full Stack Deep Learning - Lecture 1 ~ 3 (0) | 2021.10.07 |
'AI/Deep Learning' Related Articles
more




Comments