
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Diffusion
- motion matching
- 디퓨전모델
- Few-shot generation
- 딥러닝
- animation retargeting
- dl
- Stat110
- BERT
- WBP
- GAN
- ddpm
- 폰트생성
- RNN
- 모션매칭
- WinAPI
- cv
- deep learning
- CNN
- Font Generation
- UE5
- ue5.4
- Generative Model
- 생성모델
- NLP
- 언리얼엔진
- Unreal Engine
- multimodal
- 오블완
- userwidget
- Today
- Total
목록cv (15)
Deeper Learning
 LDM: High-Resolution Image Synthesis with Latent Diffusion Models
LDM: High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, (2021.12) [Ludwig Maximilian University of Munich & IWR, Heidelberg University, Runway ML] (이전 Diffusion Models paper review(DDPM, DDIM, Improved-DDPM 등)에서 다루었던 중복된 내용은 자세하게 적지 않았음) Abstract Diffusion model은 이미지 생성에서 좋은 성능을 보였고 재학습 없이 guidance를 주어 이미지 생성 프로세스를 조정할 수 있는 능력 또한 갖추고 있다 하지만 pixel level에서의 연산이 이루어지기 때문에 수백일의..
 Few-Shot Unsupervised Image-to-Image Translation
Few-Shot Unsupervised Image-to-Image Translation
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, Jan Kautz, [NVIDIA, Cornell University, Aalto University] (2019.05) Abstract Unsupervised image-to-image(i2i)는 여러 class 간 매핑을 학습하는 방법 최근 방법론들은 좋은 성과를 보였으나 학습과정에서 많은 수의 소스, 타깃 이미지를 필요로 하는 문제가 존재 인간은 매우 적은 수의 이미지로도 object를 잘 파악하는데에서 영감을 받아 few-shot 연구를 진행 저자는 새로운 모델 아키텍처, adversarial 학습 scheme을 함께 사용하여 few-shot generatio..
 ConvNeXt: A ConvNet for the 2020s
ConvNeXt: A ConvNet for the 2020s
[convnext] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, Facebook AI Research (FAIR), UC Berkeley (2022.01.02) Abstract 2020년도에 ViT는 이미지 분류 SOTA 모델로 CNN을 대체 하지만 vanilla ViT는 object detection 또는 semantic segmentation과 같은 general computer vision task에 적용하는데 어려움을 겪음 Swin Transformer와 같은 계층적 Transformer는 여러 vision task에서 좋은 성능을 냄 하지만 이러한 hybrid 접근의 유효성은 c..
 DeiT: Training data-efficient image transformers & distillation through attention
DeiT: Training data-efficient image transformers & distillation through attention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Herve Jegou. Facebook AI. Sorbonne University. (2020.12) Abstract Image task에 pure attention 기반 모델이 활용되지만 large dataset에서 pre-training이 필수적이며 이는 활용에 한계를 가져옴 single computer에서 3일 동안 ImageNet dataset만 학습하여 top-1 acc 83.1%를 달성 attention을 통해 학습하는 distillation token을 도입한 transformer를 위한 teacher-student strategy를 제시 ..
 CoAtNet: Marrying Convolution and Attention for All Data Sizes
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan Google Research, Brain Team (2021.06) Abstract Transformer 아직 vision task에서 SOTA convolutional network보다 성능이 떨어짐 Transformer는 더 큰 capacity를 가지지만 inductive bias의 부족으로 일반화 성능이 convolutional network에 비해 떨어짐 두 아키텍처의 장점을 결합하기 위해 hybrid model인 CoAtNets를 제시 CoAtNet의 key insights depthwise Convolution, Self-Attention은 간단한 relative attention을 통해 결합 가능 수직으..
 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo Microsoft Research Asia (2021.03) Abstract CV task를 위한 범용적인 Backbone 모델로 새로운 vision Transformer인 Swin Transformer를 제시 vision에 Transformer를 사용하기에는 visual entities의 scale 변동, high resolution pixels 등의 어려움이 있음 이를 해결하기 위해 Shifted windows를 사용하는 hierarchical Transformer를 제시 shifted windowing은 겹치지 않는 local window 한정으..
 MobileNetV2: Inverted Residuals and Linear Bottlenecks
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen Google Inc. CVPR Abstract 다양한 task, model size에서 mobile model SOTA를 달성한 MobileNetV2를 제시 SSDLite를 사용한 object detection, DeepLabv3 기반 semantic segmentation에서 MobileNetV2를 사용 thin bottle neck layers 간 shortcut connection에서 inverted residual structure를 사용 intermediate expansion layer는 lightweight depthwise convolution을 사용 narr..
 ArcFace: Additive Angular Margin Loss for Deep Face Recognition
ArcFace: Additive Angular Margin Loss for Deep Face Recognition
2018, Stefanos Zafeiriou Imperial College London Jiankang Deng et al. Abstract Deep Convolutional Neural Networks를 사용하여 large-scale face recognition에서 feature learning을 할 때 challenge는 discriminative power를 향상시키기 위한 loss function 설계 Centre loss는 deep features와 해당 class의 centre 사이의 Euclidean space에서 distance에 penalty를 주어 intra-class compactness를 달성 Sphere Face는 last fc layer의 linear transformation..
 Pixel-Adaptive Convolutional Neural Networks
Pixel-Adaptive Convolutional Neural Networks
Abstract Convolutions은 CNN의 기본 building block spatially shared weights는 CNN이 쓰이는 이유임과 동시에 한계점이다 learnable local pixel features에 따라 변하는 pixel-adaptive convolution(PAC)를 제시 PAC는 자주 쓰이는 filter들의 일반화 버전으로 많은 case에서 그대로 사용이 가능하다. deep join image upsampling에서 SOTA fully-connected CRF를 PAC-CRF로 대체하여 성능, 속도 향상 pre-trained networks에서 PAC drop-in replacement로 성능 향상 1. Introduction standard convolution의 두 ..
 MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
Abstract mobile, embedded vision application을 위한 depth-wise seperable convolutions을 활용한 경량화 모델 MobileNets을 제시 latency와 accuracy의 trade off를 조정하는 2개의 global hyperparameters 제시 MobileNets을 다른 모델과 비교하며 여러 실험을 통해 효율성을 검증하였음 다양한 task에 적용 가능 1. Introduction limited platform에서 빠르게 동작하여야 하는 real-word의 application이 다수 존재 (Robotics, self-driving) 2개의 hyper-parameters를 사용하여 모바일 및 embedded vision applicatio..
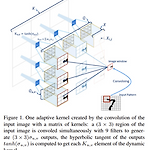 Adaptive Convolutional Kernels
Adaptive Convolutional Kernels
Abstract CV recognition performance을 향상시키기 위해 많은 복잡한 neural network architectures가 연구되었다. high computing resource를 요구하지 않고 온 디바이스로 한정된 resource에서 모델을 동작시키기 위해 adaptive convolutional kernel을 제시 input image가 dynamic하게 kernel을 결정 Adaptive kernels을 사용한 모델은 기존 CNN 보다 2배 이상 수렴이 빨랐으며, LeNet base model에서 MNIST dataset에 대해 99% 이상의 정확도를 달성하는데 66배 적은 parameters만 필요로 하였음 1. Introduction SOTA CV 모델은 대부분 deep..
 CS231n - Lecture 5 ~ 7
CS231n - Lecture 5 ~ 7
전체적인 내용 리뷰가 아닌 그룹 스터디 중 토론 나눴던 주제 중심으로 정리. Lecture 5 ~ 7 Sigmoid의 문제점 Saturated neuron kills gridients Not zero centered exp() is expensive 만약 input으로 모두 양수가 주어지면 w의 gradient는 모두 양수거나 모두 음수가 된다. w1, w2가 x, y축을 이루는 사분면을 생각해보면 만약 4사분면에 최적의 W가 존재할 경우 w1, w2의 grad는 각각 양수, 음수로 주어져야 빠른 수렴이 가능하다. 하지만 위 상황에서 이는 불가능하여 oscillation 형태로 수렴이 느려진다. Tanh zero centered saturated kill Relu no saturated kill comp..
 R-CNN, Fast R-CNN, Faster R-CNN
R-CNN, Fast R-CNN, Faster R-CNN
2-stage detectors 2-stage detector는 객체가 존재할 가능성이 높은 영역(ROI: Region of Interest)을 추출하고 CNN을 통해 class와 boundig box의 위치를 찾는다. R-CNN, Fast R-CNN, Faster R-CNN 등이 2-stage detector에 속하며, YOLO, SSD 등이 1-stage detector에 속한다. 2-stage detectors인 R-CNN, Fast R-CNN, Faster R-CNN에 대해 매우 간략하게 차이점과 발전과정을 중심으로 작성하고자 한다. (자세한 각 알고리즘에 대한 설명은 후에 따로 작성할 예정) R-CNN Region Proposals with CNN(R-CNN)은 object detection을 ..
 Semantic Segmentation
Semantic Segmentation
Semantic segmentation Semantic segmentation은 이미지의 픽셀 별로 label을 부여하는 task로 각 instance 별로 구분은 하지 않는다. Fully Convolutional Network (FCN) FCN은 Semantic Segmentation을 수행 가능한 네트워크 구조 중 하나로 Image Classification을 위한 네트워크의 아키텍처에서 Fully Connected Layer를 Fully Connected Layer로 대체한 형태의 아키텍처를 가지는 모델이다. 1x1 convolution layer를 사용하여 activation map의 차원을 조절하며 마지막에는 class 갯수와 동일한 차원의 activation map이 나오게 된다. width와..
 Knowledge Distillation
Knowledge Distillation
Knowledge Distillation Knowledge distillation은 2014 NIPS 2014 workshop에서 Geoffrey Hinton, Oriol Vinyals, Jeff Dean이 발표한 논문 "Distilling the Knowledge in a Neural Network"에서 소개된 개념이다. Knowledge distillation은 Pre-trained 된 대용량의 Teacher Network의 정보를 비교적 작은 크기의 Student Network로 전이시키는 것이다. Teacher-Student Network Student 모델은 Teacher Model을 더 적은 parameter를 가지고 모방하도록 학습된다. unlabeled data만을 사용하여 student ..