
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 생성모델
- ddpm
- BERT
- WBP
- 디퓨전모델
- deep learning
- Stat110
- UE5
- userwidget
- 폰트생성
- Unreal Engine
- ue5.4
- animation retargeting
- Diffusion
- 딥러닝
- RNN
- dl
- 언리얼엔진
- GAN
- Generative Model
- NLP
- 오블완
- multimodal
- Font Generation
- 모션매칭
- motion matching
- cv
- WinAPI
- Few-shot generation
- CNN
Archives
- Today
- Total
Deeper Learning
CoAtNet: Marrying Convolution and Attention for All Data Sizes 본문
AI/Deep Learning
CoAtNet: Marrying Convolution and Attention for All Data Sizes
Dlaiml 2022. 1. 1. 00:51Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan Google Research, Brain Team (2021.06)
Abstract
- Transformer 아직 vision task에서 SOTA convolutional network보다 성능이 떨어짐
- Transformer는 더 큰 capacity를 가지지만 inductive bias의 부족으로 일반화 성능이 convolutional network에 비해 떨어짐
- 두 아키텍처의 장점을 결합하기 위해 hybrid model인 CoAtNets를 제시
- CoAtNet의 key insights
- depthwise Convolution, Self-Attention은 간단한 relative attention을 통해 결합 가능
- 수직으로 convolution, attention layers를 stacking 하면 일반화, capacity, efficiency에서 성능 개선
- 여러 dataset에서 SOTA 달성, JFT-300M에서 학습한 ViT-Huge보다 23배 적은 데이터를 사용하여도 비슷한 성능을 보임
- JFT-3B에서 학습하여 ImageNet SOTA
Introduction
- CNN 기반 아키텍처가 dominant 하였으나 최근 Transformer를 vision에 적용하려는 시도가 많았음
- ViT의 경우 large-scale dataset에서 학습하면 SOTA ConvNets와 견줄만한 성능을 보임
- 하지만 작은 dataset에서 학습하면 ViT는 ConvNet보다 성능이 떨어짐
- ViT의 후속 연구들은 regularization, augmentation을 통해 ViT의 성능을 향상했지만 convolution models을 ImageNet classification에서 같은 양의 data와 계산량으로 뛰어넘을 수 없었음
- vanilla Transformer layer는 ConvNet보다 inductive bias가 부족하고 그러므로 많은 데이터와 계산량을 요구한다고 해석 가능하다.
- 많은 최근 연구도 ConvNet의 inductive bias를 Transformer 모델에 주입하는 방향으로 이루어졌다
- attention layer의 receptive fields를 local로 제한하거나 convolutional concept의 연산을 attention, FFN layer에 결합하는 것은 오직 특정 property만 주입하는 한정적인 방법들이며 convolution, attention의 결합에서 각각의 systematic understanding이 부족하다.
- ML의 fundamental 한 관점인 Generalization, Model capacticy 측면으로 convolution, attention의 결합을 연구
- convolutional layer는 강한 inductive bias로 일반화 성능이 좋으며 수렴이 빠르고 attention layer는 high capacity로 larger dataset에서 이점
- key challenge는 accuracy와 efficiency의 좋은 trade-offs를 위한 attention, convolution의 효율적인 결합 방법 고안
- key insight
- depthwise Convolution, Self-Attention은 간단한 relative attention을 통해 결합 가능
- 수직으로 convolution, attention layers를 stacking 하면 일반화, capacity, efficiency에서 성능 개선
- ConvNet과 Transformer의 장점을 취합
- 오직 ImageNet-1K를 사용하여도 기존 SOTA와 비슷한 좋은 일반화 성능을 가졌으며 JFT-3B와 같은 large dataset에서 학습하면 ViT-Huge를 뛰어넘는 SOTA를 달성
Model
convolution과 transformer를 조합하는 최고의 방법을 찾기 위한 질문 2개에 집중
- How to combine the convolution and self-attention within one basic computational block?
- How to vertically stack different types of computational blocks together to form a complete network?
Merging Convolution and Self-Attention
- depthwise convolution을 사용하는 MobileNetV2의 MBConv block에 집중
- Transformer의 FFN 모듈과 MBConv는 공통으로 inverted bottleneck based design (input의 channel C → 4C → C + residual)
- inverted bottleneck 구조의 유사성 말고도 depthwise convolution과 self-attention은 pre-defined receptive field에서 per-dimension weighted sum으로 표현 가능하다는 공통점이 있음

depthwise convolution과 self-attention 비교
- depthwise convolution kernel wi−j 는 input에 독립적인 static value
- attention weight Aij 는 input의 representation에 따라 dynamic
- 따라서 self-attention이 더 쉽게 복잡한 spatial positions 간 상호관계를 포착함, 하지만 한정적인 데이터에서 overfitting의 risk가 큼
- convolution weight는 상대적인 shift만 고려(i-j)하여 translation equivariance 성질을 가지며 이로 인해 한정된 dataset에서 좋은 일반화 성능
- ViT의 경우 absolute positional embedding을 사용하였기 때문에 translation equivariant 성질이 부족
- receptive field의 size가 중요한 차이점. larger receptive field는 더 contextual information을 제공하여 model의 capacity에 도움이 됨
- global receptive field는 vision self-attention에서 중요한 역할을 하지만 spatial size에 대해 quadratic 한 계산량 증가의 문제가 있음
이상적인 모델은 위에서 언급한 장점 (Translation Equivariance, Input-adaptive Weighting, Global Receptive Field)을 모두 가지고 있어야 한다.
Attention layer의 softmax normalize 이전 또는 이후에 global static convolution kernel을 더하는 간단한 아이디어
- 간단해 보이지만 pre-normalization version은 relative self-attention이며 attention weight Ai,j 는 wi−j (translation equivariance)와 input-adaptive xTixj 에 의해 결정되기 때문에 양쪽의 장점을 모두 가짐
- parameters 수를 크게 늘리지 않으면서 global convolution kernel을 사용하기 위해 논문에서는 wi−j를 scalar로 지정
- 모든 i,j에 대한 wi−j 를 사용할 때 연산은 결국 attention layer의 dot product 연산에 포함되기 때문에 scalar값을 사용하여도 무방
- 이러한 이점으로 pre-normalization relative attention variant를 Transformer block에 사용
Vertical Layout Design
convolution과 attention의 결합 방법을 찾았으며 이제 효율적인 layer stacking에 대해 고려
- 위의 relative attention을 바로 적용할 경우 quadratic complexity로 인해 large pixels image에서 속도가 매우 느릴 것
- 3가지 옵션을 고려
- spatial size를 줄이기 위한 down sampling을 통해 global relative attention을 feature map의 size가 충분히 작아졌을 때 적용
- global receptive field를 local field로 변경 (Swin Transformer, convolution과 비슷)
- quadratic softmax attention을 spatial size에 대해 linear complexity를 가진 linear attention으로 변경
- 실험 결과 (3)은 좋은 성능을 내지 못하였으며 (2)는 본 목적인 global attention 사용을 불가능하게 할 뿐 아니라 model capacity를 낮추며 tensor shape formatting 과정에서 많은 memory access로 속도 또한 좋지 않았다.
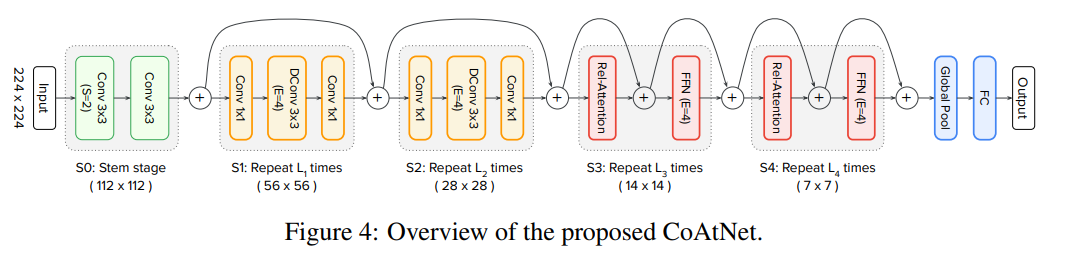
- (1)의 down-sampling은 ViT stem(16x16 stride로 raw image를 patch로 만드는 layer) 또는 CNN의 gradual pooling을 사용할 수 있다
- ViT Stem을 거치고 relative attention을 사용한 L 개의 Transformer block을 이어 쌓은 모델을 ViTREL
- CNN 형식의 down-sampling은 5-stages로 구성 (S0 ~ S4)
- S0은 simple 2-layer convolutional Stem
- S1은 SE-module이 사용된 MBConv blocks
- S2 ~ S4는 MBConv 또는 Transformer block 사용 가능
- Convolution이 초기의 local patterns을 학습하는 데 더 좋기 때문에 convolution stage는 transformer stage보다 항상 먼저 위치해야 함
- 가능한 S1 ~ S4의 조합은 {C-C-C-C}, {C-C-C-T}, {C-C-T-T}, {C-T-T-T} (C=Conv, T=Transformer)
- 두 가지 관점에서 모델 구조를 평가 (generalization, model capacity)
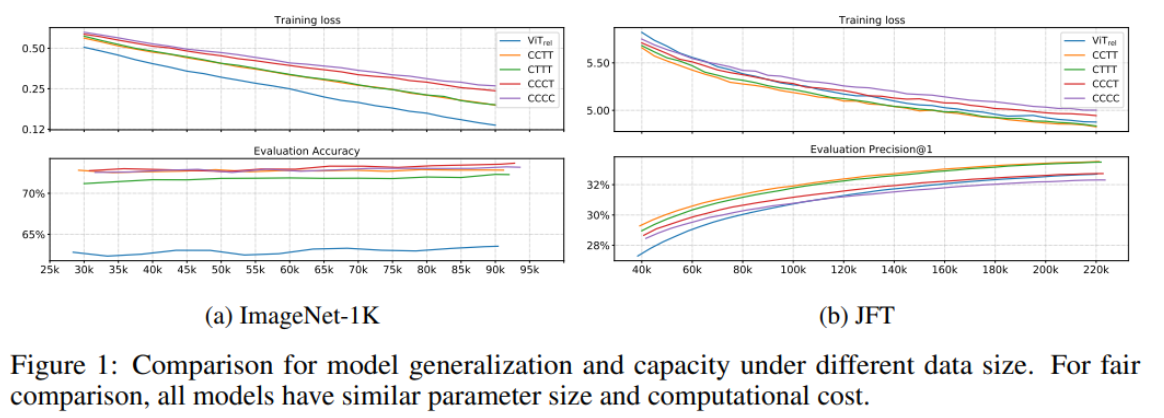
- ImageNet-1K로 generalization 성능 평가
- ViTREL 이 성능이 크게 떨어지는데 이는 ViT stem으로 인해 적절한 low-level information을 얻는데 실패하였기 때문이라고 추측
- 전체적으로 Convolution stage가 많을수록 일반화 성능이 좋음
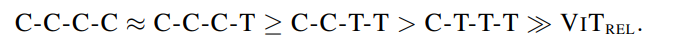
-
- Transformer block의 수가 많다고 성능이 반드시 더 좋은 것은 아님
- CCTT, CTTT의 성능이 ViTREL 보다 좋은데 이는 ViT stem의 aggressive stride로 인한 정보 손실이 model capacity에 제약을 준 것으로 보임
- CCTT, CTTT의 성능이 비슷한 것은 low-level information에 한해서 static local convolution operation, adaptive global attention의 성능이 비슷하다고 해석할 수 있음. (memory, 계산 복잡도 측면에서 convolution operation이 더 우세) large dataset인 JFT로 model capacity 평가

- CCTT, CTTT에서 최종 모델 구조를 결정하기 위해 transferbility test를 수행
- JFT에서 pretrain 한 모델을 ImageNet-1K에서 fine-tuning 하고 성능 비교
- CCTT 구조를 CoAtNet의 multi-stage layout으로 최종 결정

Experiments
CoAtNet model family
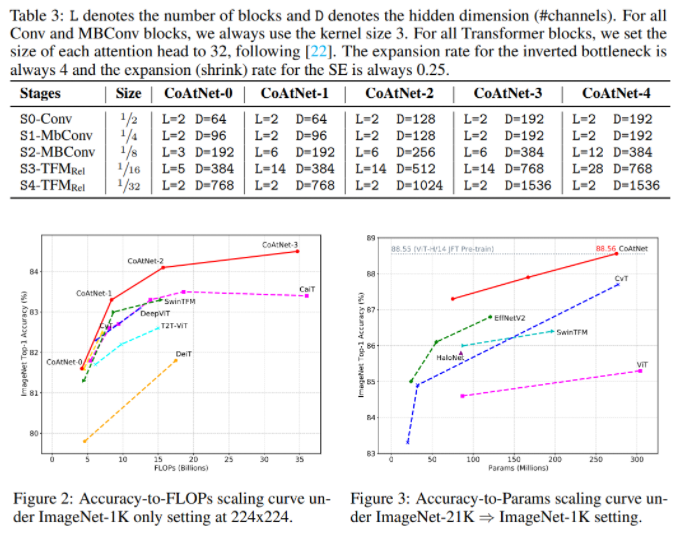
ImageNet-1K & JFT performance
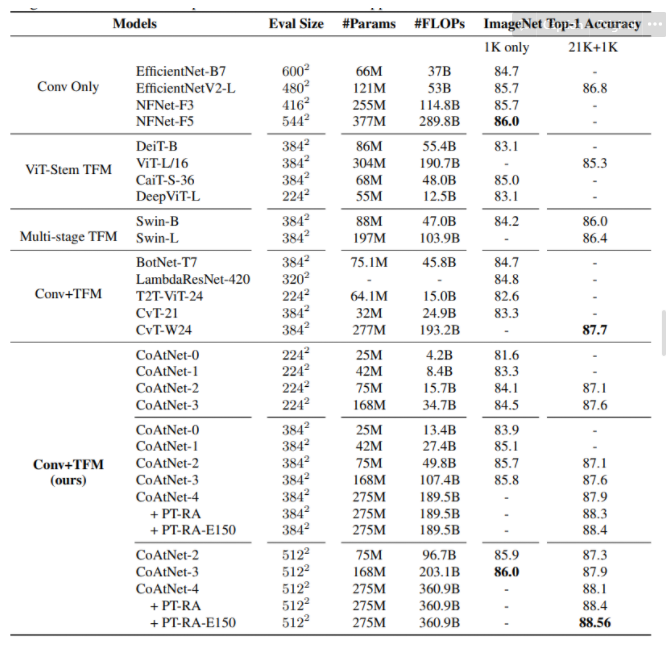

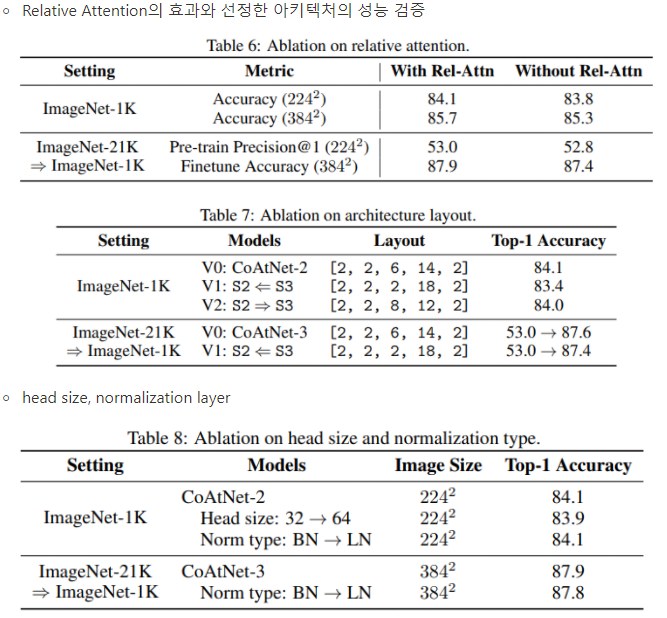
Ablation Study
Conclusion
- Convolution과 Transformer의 속성에 대한 체계적인 연구를 통해 둘을 최적의 방법으로 결합한 CoAtNet을 제시
- ConvNet의 일반화 성능과 Transformer의 model capacity를 모두 갖추어 다양한 Dataset에서 SOTA를 달성한 CoAtNet
- future work으로 object detection, semantic segmentation에서의 적용을 제시
후기 & 정리
- Transformer와 Convolution의 장단점에 대해 깊게 분석하고 두 method의 장점을 모두 갖추려고 시도하였고 성공한 CoAtNet을 제시
- ViT와 Swin Transformer 등 선행 연구의 aggressive 한 가정을 보완
- Pure Transformer의 한계를 느끼며 시작된 연구방향인 Convolution의 inductive bias 주입을 성공적으로 수행한 논문
- 다양한 크기의 데이터셋에서 모두 SOTA를 달성
- 모델 구조를 찾아가는 실험 과정을 논문에 모두 서술하였으며 어떤 관점으로 문제를 바라보았는지 꾸준하게 언급해주어서 쉽게 저자의 사고를 비교적 수월하게 따라갈 수 있었던 논문
Reference
[0] Zihang Dai, Hanxiao Liu, Quoc V. Le, Mingxing Tan Google Research, Brain Team.(2021.06). "CoAtNet: Marrying Convolution and Attention for All Data Sizes". https://arxiv.org/abs/2106.04803 . CVPR
'AI > Deep Learning' 카테고리의 다른 글
| Few-shot Font Style Transfer between Different Languages (0) | 2022.01.07 |
|---|---|
| DeiT: Training data-efficient image transformers & distillation through attention (0) | 2022.01.05 |
| Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2021.12.31 |
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2021.12.24 |
| Residual Attention Network for Image Classification (0) | 2021.12.22 |
'AI/Deep Learning' Related Articles
more



