
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- NLP
- Generative Model
- multimodal
- Unreal Engine
- BERT
- UE5
- CNN
- WBP
- Font Generation
- Few-shot generation
- animation retargeting
- 폰트생성
- Diffusion
- 딥러닝
- 모션매칭
- 오블완
- motion matching
- RNN
- deep learning
- Stat110
- 디퓨전모델
- ddpm
- WinAPI
- cv
- dl
- 생성모델
- GAN
- userwidget
- ue5.4
- 언리얼엔진
Archives
- Today
- Total
Deeper Learning
Few-shot Font Style Transfer between Different Languages 본문
Chenhao Li, Yuta Taniguchi, Min Lu, Shin’ichi Konomi HDI Lab, Kyushu University. (2021)
Abstract
- 적은 샘플로 언어 간 font style을 transfer 할 수 있는 FTransGAN을 제시
- 언어 간 font style transfer는 많이 연구되지 않았음
- multi-level attention을 통해 local, global style을 capture
- English, Chinese를 모두 가진 847개의 font dataset을 사용
Introduction
- 폰트를 만드는 것은 매우 노동집약적, 대부분 하나의 언어에 대한 폰트만 만듦
- 폰트의 subset만 보고 나머지를 생성하는 것은 neural net으로 가능해졌으며 관련 연구들이 있음
- 2개의 단점이 존재
- 학습 과정이 2 stage로 large dataset에서 pretrain 하고 fine-tune
- fine-tuning 할 때 수백개의 samples이 필요
- Real world에서 디자이너는 하나의 언어에 대한 폰트만 디자인하며 다른 언어로의 확장은 시간이 매우 많이 드는 작업
- 예시로 영화 포스터의 경우 폰트는 여러 언어에 대해 같은 style로 디자인 되어야 함
- artistic style transfer는 global style만 고려하는 경우가 많으나 font는 local style (decoration, stroke, thickness) + global style(shape, effect)로 이루어져 있는 경우가 많음
- 다른 언어의 적은 샘플로 고품질의 글자 생성이 가능한 FTransGAN(Font Translator GAN)을 제시
- fine-tuning에 의존하는 기존 method와 달리 forward pass만으로 생성하여 real-time이 가능
- content와 style representation을 추출하는 2개의 Encoder를 사용
- content와 style의 matching을 확인하는 2개의 Discriminator를 사용
- style encoder는 Context-aware Attention Network, Layer Attention Network 모듈로 구성
- main contributions
- first end-to-end solution to cross-language font style transfer
- Context-aware Attention Network, Layer Attention Network로 local, global style features를 동시에 capture 하는 방식 제시
- 임의의 개수의 style images를 input으로 넣을 수 있음
- 52 English, 1000 Chinese characters를 담고있는 847개 font로 이루어진 multi-language glyph image dataset을 구축
Font Generation
- MC-GAN에서 최초로 end-to-end solution으로 인공 폰트를 생성, 하지만 input & output images의 개수가 고정되어 Chinese 같은 large font library에서 사용이 불가능
- AGIS-Net과 EMD는 style, content images를 condition으로 받는다는 차이점
- DM-Font는 compositionality를 활용하여 성능 향상
Method Description

- 2개의 conditions을 만족하는 glyph images 생성이 목표
- glyph 생성을 조건부 확률 $p(x|s,c)$ 을 solving 하는 것으로 정의 (x는 target image, c는 standard style의 content image, s는 style images set)
- content image의 역할은 문자의 category를 indexing하는 정도로 이전 연구에서 content images의 style은 결과에 큰 영향이 없다는 것이 증명됨
- 사람도 style을 파악하기 위해서는 여러 glyph이 필요하지만 content를 파악하는 데는 하나의 glyph으로 충분함
- 2개의 Discriminator는 PatchGAN을 사용하여 patch를 locally check

- 2개의 Encoder는 각각 style과 content representation을 추출 decoder는 이를 활용하여 target image 생성
- Content encoder는 convolution + BatchNorm + ReLU로 이루어진 convolution block 3개로 구성
- Decoder는 6개의 ResNet Block과 up-convolution + BN + ReLU로 구성된 Block 3개로 구성
- Style encoder는 Context-aware Attention과 Layer Attention Network를 사용하여 local & global style을 잡아낼 수 있음
- 각 style image를 feature vector로 mapping하고 평균을 계산하여 final style feature vector $z_s$ 를 만듦
Context-aware Attention Network

- style encoder는 3개의 context-aware attention block으로 구성
- 각 13x13, 21x21, 37x37의 receptive field를 가져 shallower layer는 local feature만 볼 수 있으며 deeper layer는 전체 image를 볼 수 있음
- context vector는 query의 역할, random initialized
- 모든 region이 같은 기여도를 가지고 있지 않을 것이라고 생각하기에 region에 score를 주는 형식의 attention을 사용

- $h_r$ 은 SA block을 통과한 feature map, $u_c$ 는 context vector
- 3개의 parallel Context-aware Attention Networks를 통해 feature vectors $f_1, f_2, f_3$ 를 얻게 됨
Layer Attention Network
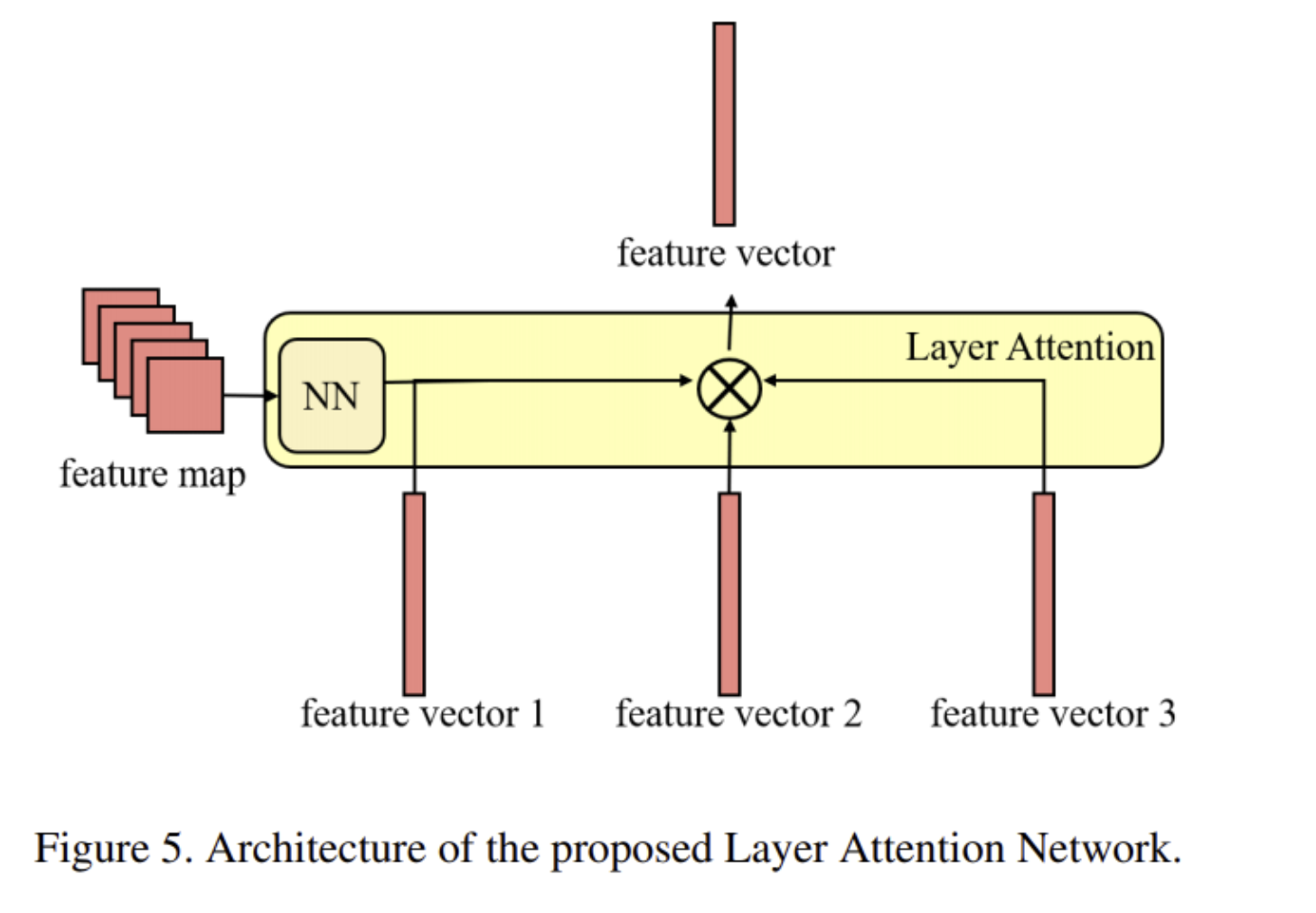
Style image에서 machine은 local feature에 집중하여야 할까? global feature에 집중하여야 할까?
image 자체에 따라 답은 달라진다
- 위 가정을 기반으로 Layer Attention Network를 디자인
- 그림을 보면 4개의 input이 필요, $f_m$ 은 last convolution의 feature map, $f_1, f_2, f_3$ 는 Context-aware Attention Networks의 outputs
- 한 층의 neural network를 사용하여 feature vector에게 score를 부여
- scores는 어느 feature level에 모델이 집중하여야 하는지 명시적으로 나타내는 역할

- $z$ 는 3개의 feature vectors의 weighted sum이며 $z_s$ 는 K개의 style images에 해당하는 $z$ 의 평균값
- Content Encoder를 통해 얻은 content code는 $C \times H \times W$ 의 shape지만 Style code $z_s$ 의 경우 C-dimensional vector로 repeat을 통해 size를 맞추고 둘을 concat 하여 decoder에게 전달
- decoder는 style code. content code를 바탕으로 image를 생성
End-to-End Training
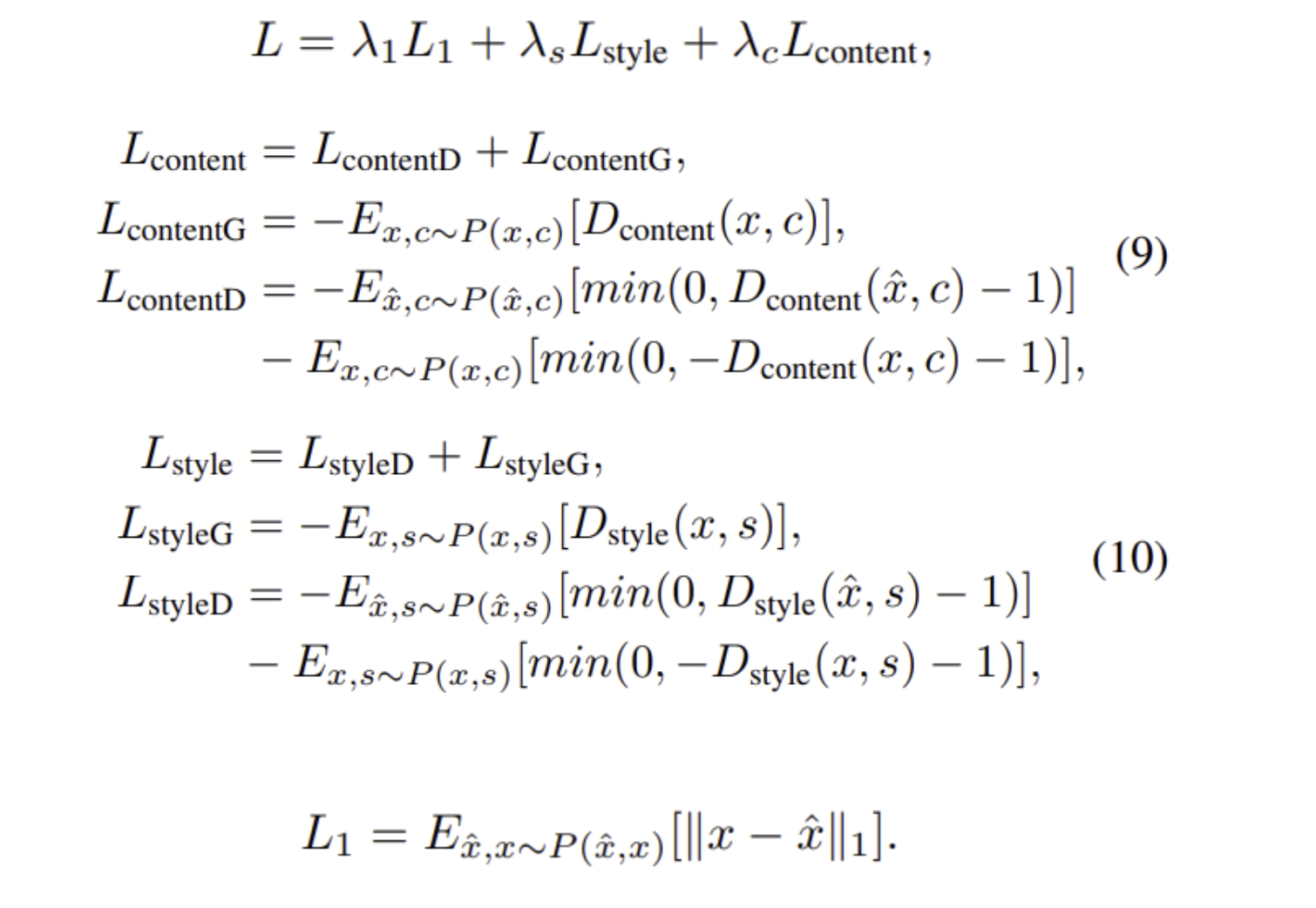
- objective function의 산식은 위와 같음
- Discriminator에 넣는 fake samples과 true samples은 channel-axis concat 후 feed
- 안정적인 학습을 위해 pixel-wise L1 loss를 추가
Experiments
- $\lambda_1 = 100$
- $\lambda_c, \lambda_s = 1$
- lr = 0.0002
- K = 6
- num_epochs = 20

- $f_1, f_2, f_3$ 에 부여되는 가중치
- Handwriting font는 local style인 13x13 receptive field에 해당하는 feature map에 가중치가 크고 Artistic fonts, printing fonts는 global style이 필요

Conclusion
- 적은 samples로 end-to-end cross language font style transfer가 가능한 FTransGAN을 제시
- Context-aware Attention Network와 Layer Attention Network을 사용하여 좋은 성능을 얻음
- 학습 도중에는 style image의 개수는 모델 구조의 한계로 인해 고정되어야 함
- highly artistic fonts의 경우 생성 성능이 좋지 않음
- future work으로 artistic style transfer와 같은 다른 task에 현 모델의 적용, highly artistic fonts의 style transfer를 제시
후기 & 정리
- Few-shot + cross-language font generation을 성공한 논문
- receptive field를 통해 character의 local style, global style을 모두 고려한다는 idea
- font style에 따라 receptive field를 다르게 하여 추출한 feature map에 대한 가중치가 달라진다는 결과가 흥미로움
- 간단한 module을 추가하였고 fine-tuning을 하지 않았으나 좋은 성능
Reference
[0] Chenhao Li et al. (2021). "Few-shot Font Style Transfer between Different Languages". 2021 IEEE Winter Conference on Applications of Computer Vision (WACV)
'AI > Deep Learning' 카테고리의 다른 글
| MLP-Mixer: An all-MLP Architecture for Vision (0) | 2022.01.28 |
|---|---|
| Variational autoencoder (0) | 2022.01.26 |
| DeiT: Training data-efficient image transformers & distillation through attention (0) | 2022.01.05 |
| CoAtNet: Marrying Convolution and Attention for All Data Sizes (0) | 2022.01.01 |
| Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2021.12.31 |
'AI/Deep Learning' Related Articles
more



Comments