
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- dl
- Stat110
- ue5.4
- GAN
- BERT
- RNN
- WinAPI
- Generative Model
- Few-shot generation
- NLP
- 디퓨전모델
- ddpm
- Unreal Engine
- WBP
- userwidget
- cv
- multimodal
- UE5
- deep learning
- animation retargeting
- CNN
- 언리얼엔진
- Diffusion
- 생성모델
- Font Generation
- 모션매칭
- 폰트생성
- motion matching
- 딥러닝
- inductive bias
- Today
- Total
Deeper Learning
DeiT: Training data-efficient image transformers & distillation through attention 본문
DeiT: Training data-efficient image transformers & distillation through attention
Dlaiml 2022. 1. 5. 09:09Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Herve Jegou. Facebook AI. Sorbonne University. (2020.12)
Abstract
- Image task에 pure attention 기반 모델이 활용되지만 large dataset에서 pre-training이 필수적이며 이는 활용에 한계를 가져옴
- single computer에서 3일 동안 ImageNet dataset만 학습하여 top-1 acc 83.1%를 달성
- attention을 통해 학습하는 distillation token을 도입한 transformer를 위한 teacher-student strategy를 제시
- convnet을 teacher로 설정하였을 때 ImageNet과 다른 task에 transferring 성능 또한 convnet에 필적
Introduction
- vision task에 Transformer 또는 Transformer & Convnet의 결합 기반 모델에 대한 연구가 많았음
- ViT는 NLP의 Transformer를 그대로 사용하여 좋은 성능을 냈지만 private large dataset인 JFT-300M에서 pre-training
- ViT에서는 Transformer를 다음과 같이 결론 내림
- “Do not generalize well when trained on insufficient amounts of data”

ImageNet-1K만 사용하여 학습한 Throughput, accuracy graph
⚗(distillation) symbol은 transformer-specific distillation을 사용하였을 때 결과
논문에서 제시하는 3가지 Contributions
- 4 GPU single node에서 3일 만에 학습, convolution layer를 포함하지 않고 추가 데이터 없이 ConvNet SOTA와 비슷한 성능
- distillation token을 사용한 새로운 distillation procedure 제시
- class token과 비슷하지만, teacher가 추정한 label을 예측
- vanilla distillation을 크게 상회하는 성능
- convnet을 teacher로 사용하였을 때 좋은 결과
- ImageNet에서 pretrain한 모델은 fine-grained classification과 같은 downstream task에서도 경쟁력 있는 성능을 보임 (CIFAR-10,100, Oxford-102 flowers, etc.)
Distillation through attention
soft distillation vs hard distillation, classical distillation vs distillation token을 비교
Soft distillation

- teacher와 student 모델 간 softmax의 Kullback-Leibler divergence를 최소화
- $Z_t$ : Logits of Teacher model
- $\lambda$ : KL과 CE balancing coefficient
- $\tau$ : temperature
- $\psi$ : softmax function
Hard-label distillation
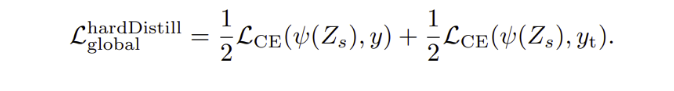
- 특정 data augmentation에 의해 teacher의 true label의 값은 달라질 수 있다
- label smoothing을 사용 $\epsilon$ = 0.1
- teacher prediction이 true label과 비슷한 역할을 하는 간단한 concept과 parameter-free한 hard-label distillation을 사용하기로 선택
Distillation token
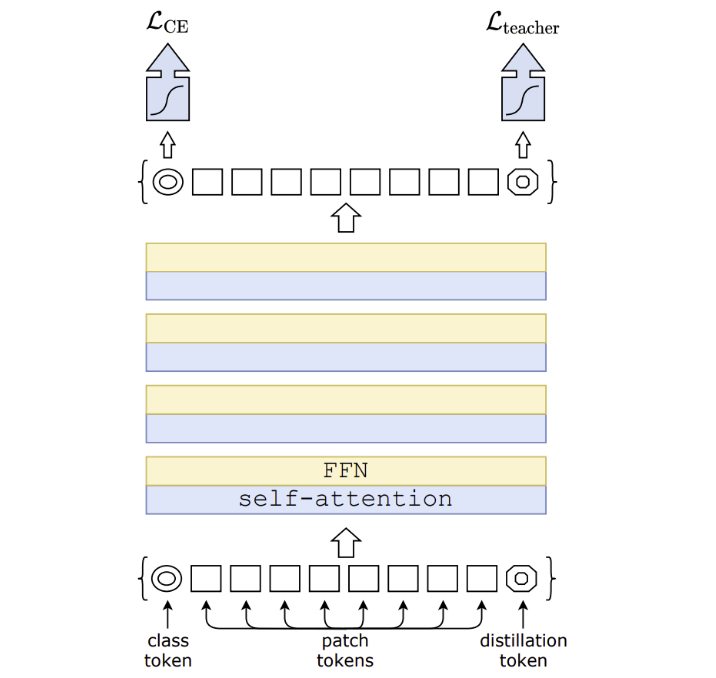
distillation token은 patch tokens, class token과 self-attention에 의해 상호작용 (class token과 동일한 과정), 하지만 teacher prediction의 hard label을 reproduce 하는 것이 목표
- class token과 distillation token의 cosine similarity는 학습이 완료되어도 마지막 layer에서 0.93 정도로 이는 두 token이 비슷하나 같지 않은 target을 producing 한다는 것
- distillation token 대신 two class token을 사용하면 cosine similarity가 0.999에 이르는 거의 같은 벡터가 되도록 학습 되며 모델 성능 개선 또한 없음
- 하지만 teacher의 pseudo-label을 예측하는 distillation token의 경우 상당한 모델 성능 향상
Fine-tuning with distillation
- higher resolution에서 true label과 teacher prediction을 모두 사용
- true label만 사용했을 때보다 좋은 성능
Classification with our approach: joint classifiers\
- test time에서 class embedding, distillation embedding은 모두 linear classifier를 사용하여 image label을 inference 할 수 있다
- two separated heads를 fusion하는 방식에 대해서는 Experiments에서 실험
Experiments
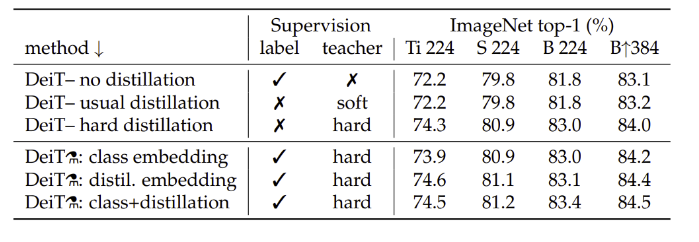
Transformer models
- ViT와 같은 구조, MLP head를 따로 사용하지 않고 학습 방식, distillation token이 차이점

Distillation
- Convnet teacher의 성능이 더 좋은데 이는 inductive bias의 distillation 때문으로 추정
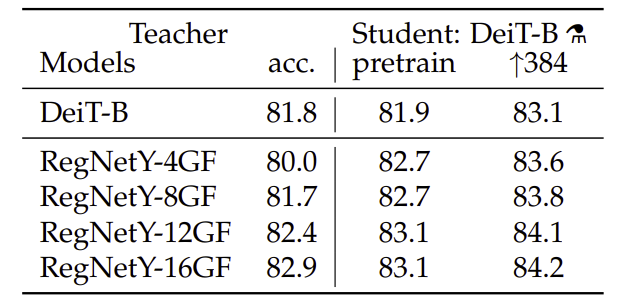
- distillation token을 추가하고 class+distillation embeddings을 모두 사용하였을 때 가장 좋은 결과
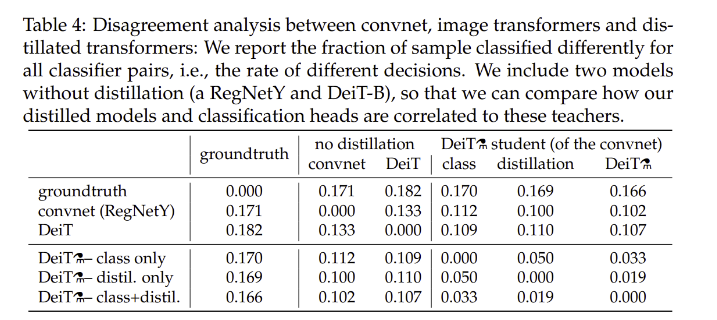
- decision agreement로 모델 간 correlation을 확인
- distilled model은 transformer보다 convnet과 correlate
- class embedding의 classifier는 distillation 없이 학습한 DeiT의 classifier와 비슷
- distillation embedding의 classifier는 convnet의 class embedding과 비슷
- 두 classifier의 joint는 middle ground
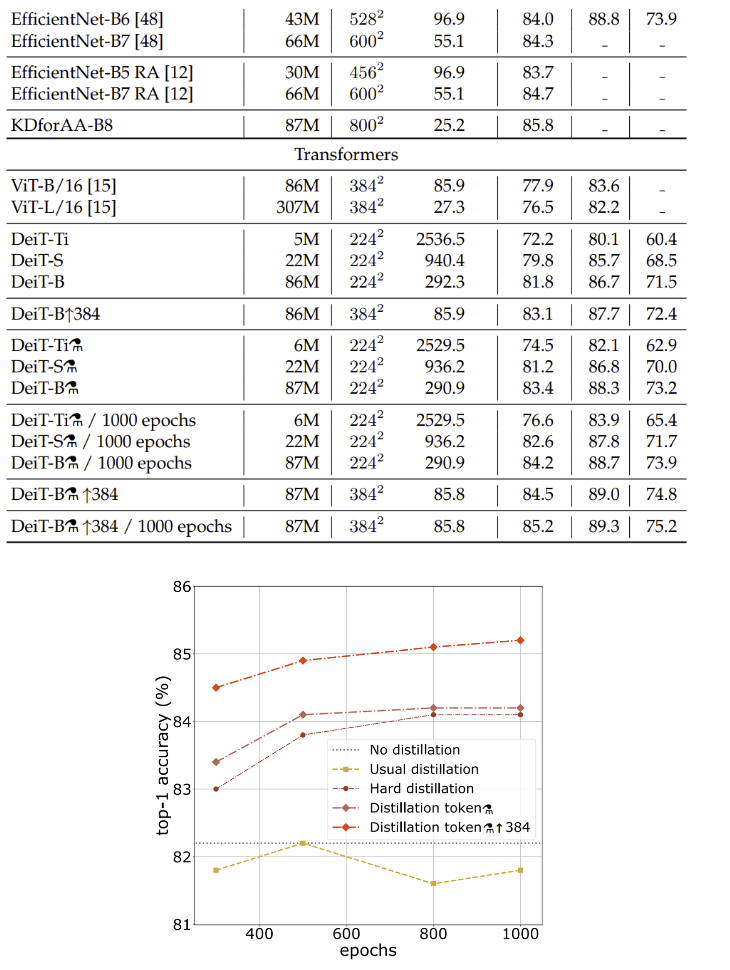
Efficiency vs accuracy
- ImageNet만 사용하였을 때 성능이 ConvNet에 거의 근접, fine-tuning에서 resolution을 높이는 것이 성능을 향상 시킴
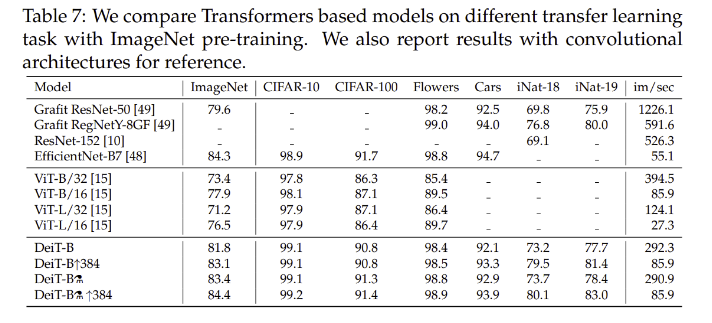
Transfer Learning
- 기존 Convnet 모델과 견줄만한 성능
- 특수한 distillation method의 사용이 성능을 크게 향상시킴
Ablation study
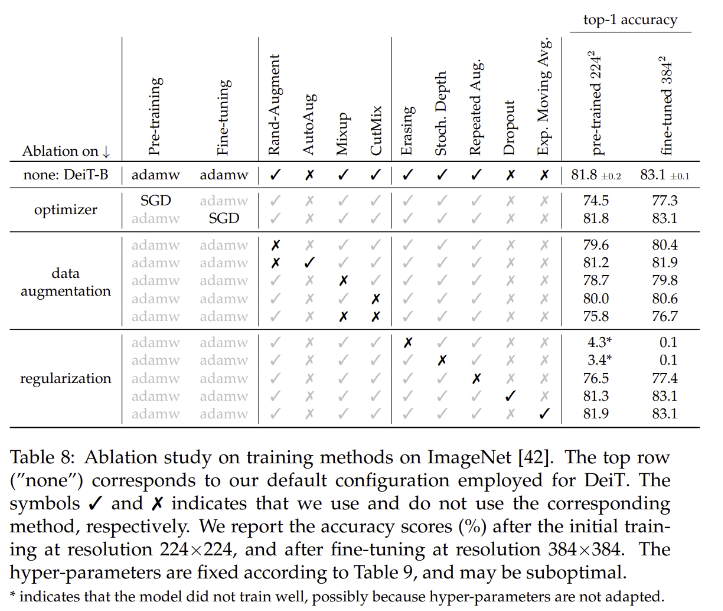
- Transformer를 위한 많은 데이터를 위해 Augmentation을 여럿 실행, 대부분 성능 향상
Conclusion
- improved training과 novel distillation을 통해 very large data에서 pretraining을 필요로 하지 않는 DeiT를 제시
- Convolutional neural network는 아키텍처와 최적화 측면에서 10년 동안 EfficientNet과 같은 아키텍처 search를 포함하여 계속 연구되어왔다.
- Transformer를 위한 data augmentation 방식에 대한 연구를 future work로 제시
- convnets과 성능이 비슷해진 Image Transformer는 accuracy 대비 memory footprint가 낮아 빠르게 method of choice가 될 것
후기&정리
- Distillation token을 활용하여 transformer에 알맞은 distillation method를 특징으로 한 DeiT를 제시
- ViT의 단점인 large dataset에서 pretraning을 극복한 방법론
- 오직 ImageNet을 사용하여 학습하였음에도 ConvNet SOTA와 비슷한 성능을 보여줌
- 많은 Ablation study, Experiments
- Teacher 모델로 Convnet을 사용하였을 때 성능이 더 좋았던 현상을 inductive bias의 distillation을 통한 주입으로 해석
'AI > Deep Learning' 카테고리의 다른 글
| Variational autoencoder (0) | 2022.01.26 |
|---|---|
| Few-shot Font Style Transfer between Different Languages (0) | 2022.01.07 |
| CoAtNet: Marrying Convolution and Attention for All Data Sizes (0) | 2022.01.01 |
| Swin Transformer: Hierarchical Vision Transformer using Shifted Windows (0) | 2021.12.31 |
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2021.12.24 |


