

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- userwidget
- 모션매칭
- motion matching
- 오블완
- Font Generation
- BERT
- RNN
- GAN
- NLP
- CNN
- Diffusion
- 딥러닝
- ue5.4
- WinAPI
- Unreal Engine
- Generative Model
- deep learning
- dl
- UE5
- cv
- 폰트생성
- 언리얼엔진
- animation retargeting
- WBP
- Few-shot generation
- Stat110
- 생성모델
- ddpm
- 디퓨전모델
- multimodal
Archives
- Today
- Total
Deeper Learning
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows 본문
AI/Deep Learning
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Dlaiml 2021. 12. 31. 21:45Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo Microsoft Research Asia (2021.03)
Abstract
- CV task를 위한 범용적인 Backbone 모델로 새로운 vision Transformer인 Swin Transformer를 제시
- vision에 Transformer를 사용하기에는 visual entities의 scale 변동, high resolution pixels 등의 어려움이 있음
- 이를 해결하기 위해 Shifted windows를 사용하는 hierarchical Transformer를 제시
- shifted windowing은 겹치지 않는 local window 한정으로 self-attention computation을 제한하면서 cross-window connection을 추가하여 효율적
- 계층적 아키텍처는 모델이 다양한 scale을 다룰 수 있으며 이미지 resolution에 대해 선형적인 computational complexity를 가지게 함
- Swin Transformer는 image classification, object detection, semantic segmentation에 모두 적용 가능
- COCO, ADE20K에서 SOTA, 계층적 모델 구조는 MLP 아키텍처에도 이점을 가짐
Introduction
- CV에서 CNN이 주류였으며, NLP에서는 long-range dependencies를 관리할 수 있는 Transformer가 압도적 성능
- CV에 Transformer를 적용한 ViT, image classification과 joint vision-language model에서 좋은 성능을 보임
- Transformer를 cv의 general-purpose backbone으로 확장
- vision에 적용하기에 어려운 점은 language와 modalities의 차이
- vision element는 word token과 달리 scale이 다양하여 object detection과 같은 task에서 attention을 사용하는데 어려움
- high resolution의 이미지의 경우 pixel level의 prediction이 필요한 semantic segmentation task에서 image size에 따라 quadratic 하게 증가하는 계산복잡도로 인한 어려움
- 위 문제들을 개선하기 위해 계층적 feature maps을 만드며, image resolution에 대해 linear 계산 복잡도를 가지는 general-purpose Transformer backbone인 Swin Transformer를 제시
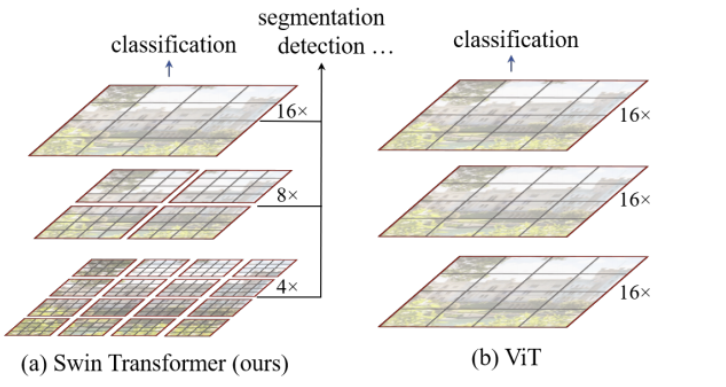
- Swin Transformer에서 layer가 깊어지면서 patch가 merge 되며 계층적 feature maps을 생성, 빨간 선으로 구분된 local window내에서 self-attention이 적용되기 때문에 linear 한 계산복잡도
- ViT는 globally self-attention으로 인해 image resolution에 quadratic 계산복잡도
- small size patches (gray line이 하나의 patch)에서 시작하여 layer가 깊어질수록 인접 patches를 merging
- 계층적 feature map 덕분에 feature pyramid networks(FPN), U-Net을 쉽게 적용 가능
- window의 patch 개수는 고정이므로 image size에 linear 한 계산복잡도
- 계층적 feature maps, linear complexity로 인해 Swin Transformer가 single resolution feature maps, quadratic complexity를 가지는 이전 Transformer based 아키텍처와 비교하였을 때 general-purpose vision backbone에 적합

- Swin Transformer의 key design은 연속적인 self-attention layer 사이의 window partition shift
- shifted window method는 이전 layer의 window와 현재 window를 이어주며 이는 모델링 power를 효과적으로 향상
- 이전의 sliding window self-attention 연구와 다르게 window 내의 모든 query patches에 대해 같은 key patches set을 사용하기 때문에 latency 측면에서 효율적, modeling power는 비슷
- 모든 MLP 아키텍처에서 shifted window 접근법은 효과가 있었음
- image classification, object detection, semantic segmentation에서 ViT, DeiT, ResNeXT의 성능을 능가하였으며 latency 또한 비슷하였다
- Swin Transformer의 여러 vision task에서 뛰어난 성능이 vision, language unified modeling을 장려
Model
Overall Architecture

- Input (H x W x 3)이 Patch Partition을 통과, patch size는 4x4로 아래 그림과 같이 하나의 patch는 flatten 되어 48차원을 가지며 이러한 patch가 (W / H) x (W / 4) 개 존재, 각 patch는 token으로 취급 (ex. H=128, W=128 일 때 4x4 pixels의 patches가 (32 x 32)개) (32, 32, 48)
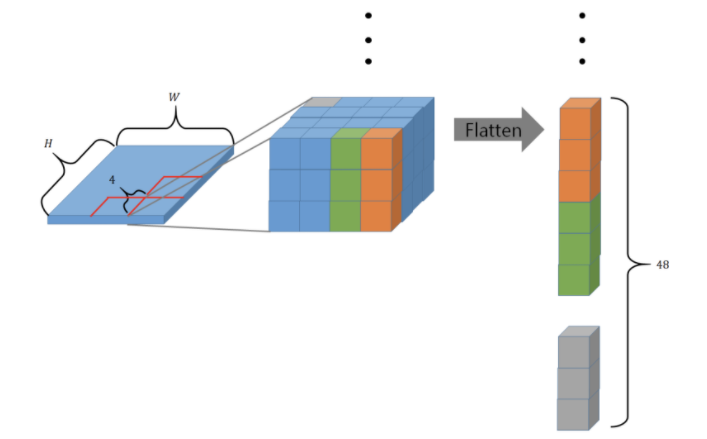
- Linear Embedding layer를 통과하여 임의의 차원 $C$ 로 projection (32, 32, C)
- Swin Transformer Block 통과 (token 개수 유지) (32, 32, C)
- Patch Merging (16, 16, 2C)
- 2x2 인접 patches를 통합
- token(patch)의 수가 4배 줄어듦
- channel axis로 concat 하여 4C로 확장, linear layer를 사용하여 channel 2C로 조정
- Swin Transformer Block 통과 (16, 16, 2C)
- Stage 3, 4 동일
Swin Transformer Block
- MSA를 대체
- 2-layer MLP, GELU 사용
Shifted Window based Self-Attention
- Self-attention을 local window 내에서 수행
- 각 window가 M x M개의 patches로 이루어져 있을 때 계산복잡도, h x w는 patch의 개수
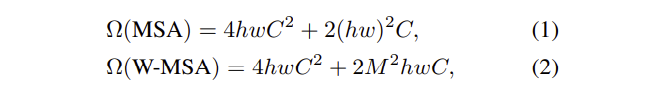
- MSA는 patch 수에 따라 quadratic 하게 증가
- W-MSA는 M이 고정된 상황에서 (논문에서는 7로 고정) patch 수에 따라 linear 하게 증가
- 하지만 W-MSA는 window 간 connection의 부족으로 모델링 파워가 제한적
- 이를 해결하기 위해 shifted window를 사용하여 window 간 정보를 공유 [SW-MSA]
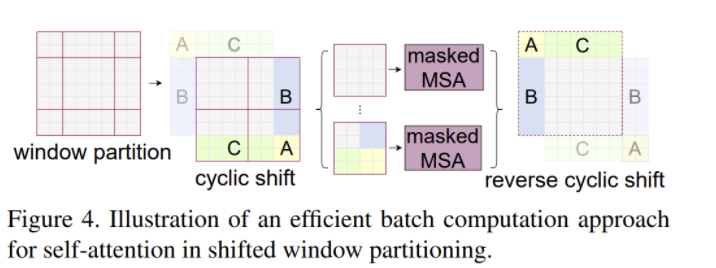
- 2/M pixel씩 window를 이동시켜 새로운 window partition을 만든다
- 이때 window의 크기는 제각각이며 병렬 처리가 어려워지는데 Cyclic shift + masked MSA를 사용하여 이를 해결
- 앞서 말한 3개의 vision task에서 모두 효과적인 shifted window
Relative position bias
- window 내의 patch의 위치에 따라 상대적으로 position bias를 주었으며 이는 absolute position bias보다 Swin Transformer에 적합하며 좋은 성능을 보였다
- $M^2$ 이 window 내 patch의 수 일 때 relative position의 range는 x, y 축 모두 [-M +1 , M -1]
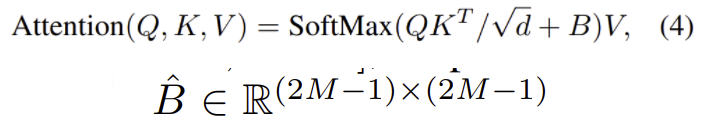
- $\hat B$ 에서 가져온 position bias B를 사용

Experiments
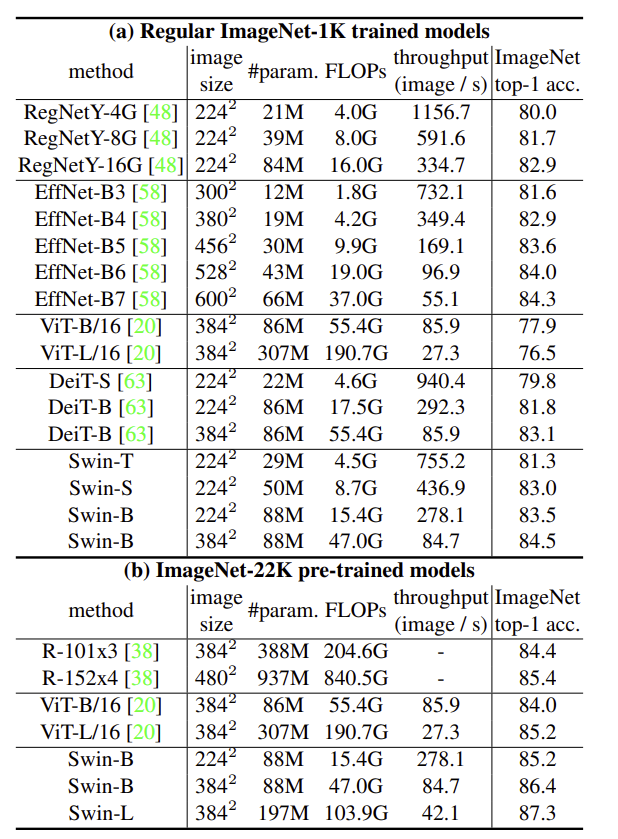
- architecture search를 수행하여 모델을 구성하면 개선의 여지가 있음
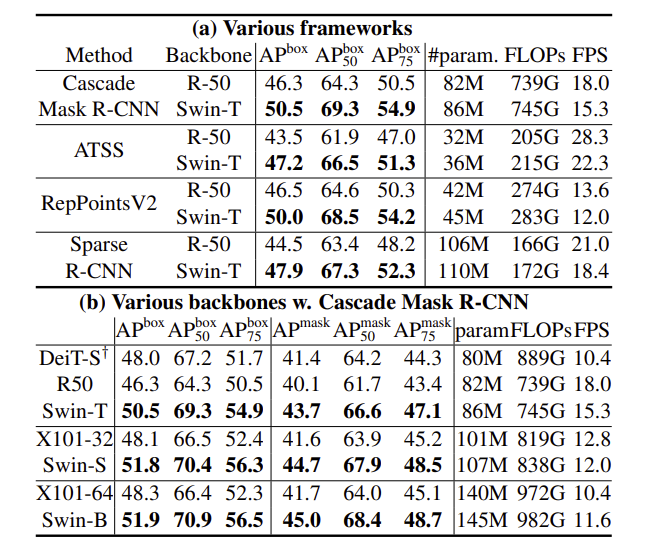
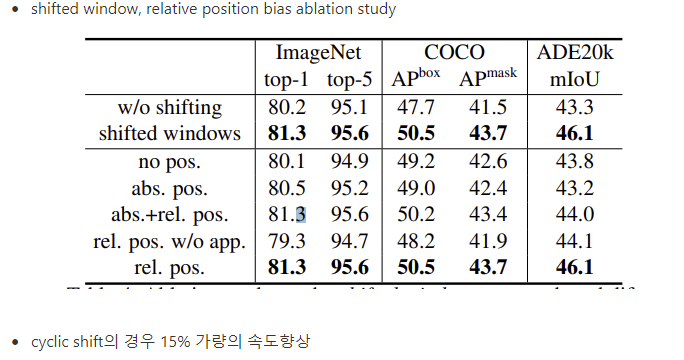
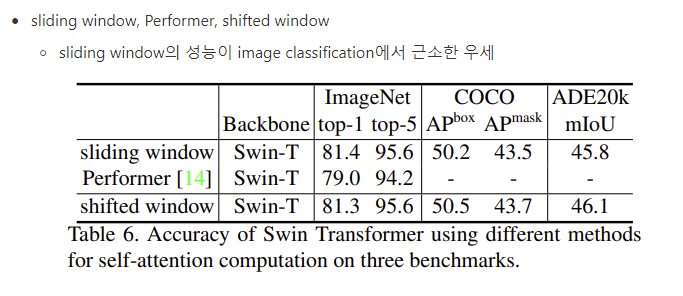
Conclusion
- 계층적 feature representation을 사용하고 image size에 대해 linear 한 계산복잡도를 가지는 vision Transformer Swin Transformer를 제시
- COCO object detection, ADE20K semantic segmentation에서 SOTA
- Swin Transformer의 핵심인 shifted window based self-attention이 vision task에서 효과적으로 작동, nlp에서의 사용도 연구하기를 기대
후기 & 정리
- 범용적인 vision task를 위한 backbone Swin Transformer를 제시
- 계층적인 feature map, lmage size에 linear 한 계산복잡도, shifted window based SA가 핵심
- shifted window, cyclic shift, relative position bias 알고리즘에 대한 이해가 필요하여 읽는데 시간이 오래 걸린 논문
- 후에 직접 구현해보거나 line by line으로 코드를 확인하면 좋을 논문
- shifted window를 수행하는 구체적인 방식이 실험을 통해 얻어낸 것인지 (2/M pixel shift) 아니면 특정한 이유가 있는 것인지 알고 싶으나 논문에서는 언급하지 않음
- 계산량을 크게 줄여 더 큰 resolution의 이미지를 다룰 수 있으며 scale up이 가능하고 object detection, semantic segmentation에서 SOTA
Reference
[0] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. (2021). “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more




Comments