
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 딥러닝
- deep learning
- Stat110
- 생성모델
- ue5.4
- multimodal
- UE5
- NLP
- motion matching
- 모션매칭
- Generative Model
- Diffusion
- ddpm
- CNN
- Few-shot generation
- cv
- RNN
- 오블완
- userwidget
- BERT
- Unreal Engine
- animation retargeting
- 폰트생성
- WBP
- dl
- 언리얼엔진
- GAN
- Font Generation
- 디퓨전모델
- WinAPI
Archives
- Today
- Total
Deeper Learning
Residual Attention Network for Image Classification 본문
Fei Wang1, Mengqing Jiang2, Chen Qian1, Shuo Yang3, Cheng Li1,Honggang Zhang4, XiaogangWang3, Xiaoou Tang,
SenseTime Group Limited, Tsinghua University,The Chinese University of Hong Kong, Beijing University of Posts and Telecommunications. (2017)
Abstract
- 당시 SOTA인 attention mechanism을 CNN에 사용한 Residual Attention Network를 제시
- Residual Attention Network(이하 RAN)은 attention-aware feature를 뽑아내는 Attention 모듈을 쌓은 구조
- Attention 모듈은 bottom-up, top-down feed forward 구조를 사용
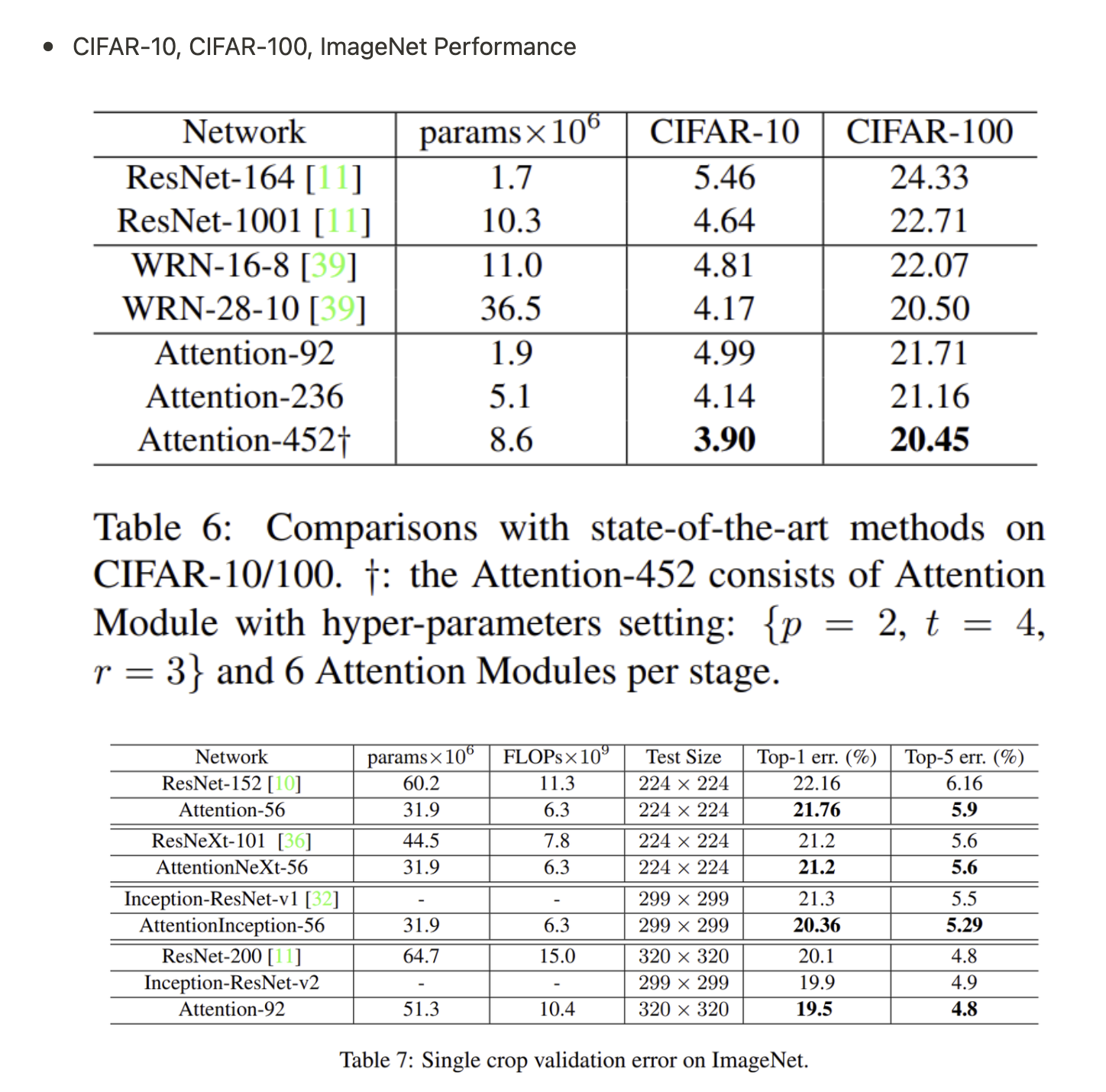
- ResNet에 Attention 모듈을 추가하여 CIFAR-10, CIFAR-100에서 성능 향상
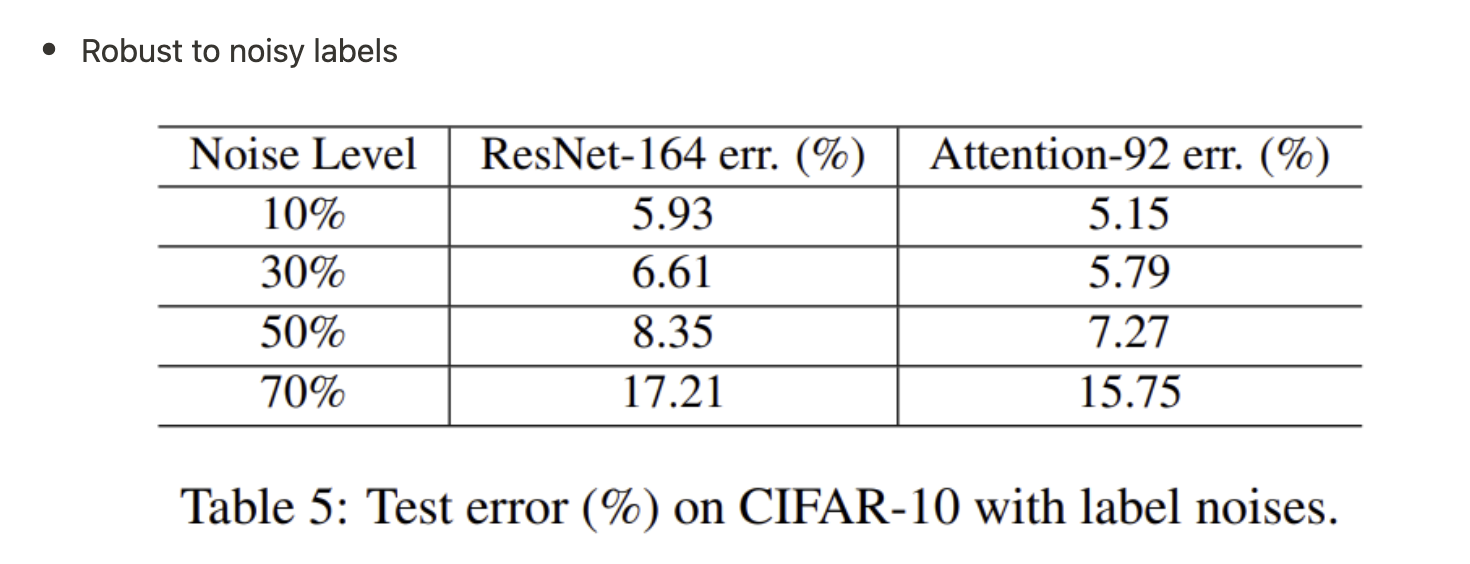
- noisy label에 robust
Introduction
- image classification task에 SOTA를 달성한 attention이 적용된 feedforward 구조는 없었음
- deep neural net에서 Attention을 사용할 수 있는 RAN을 제시
- Attention Module을 추가하면 일관적으로 성능 향상이 있었음
- 여러 타입의 attention을 파악 가능

- SOTA 모델들에 모듈형식으로 붙여 쉽게 사용가능
- CIFAR-10, 100에서 RAN은 SOTA Residual network
- 계산량 또한 감소
기존 연구방식에서 어려움을 해결한 RAN의 특성
- Stacked network structure
- 다수의 Attention Module을 쌓은 구조
- 다양한 type의 attention을 capture
- Attention Residual Learninig
- Attention module을 Stack하는 것은 성능 하락이 빈번
- Residual 구조를 사용
- Bottom-up top-down feedforward attention
- Bottom-up top-down feedforward 구조는 pose estimation, image segmentation에서 성공적으로 사용
- 해당 구조는 Attention module의 일부, feature에 soft weights를 더해주는 역할
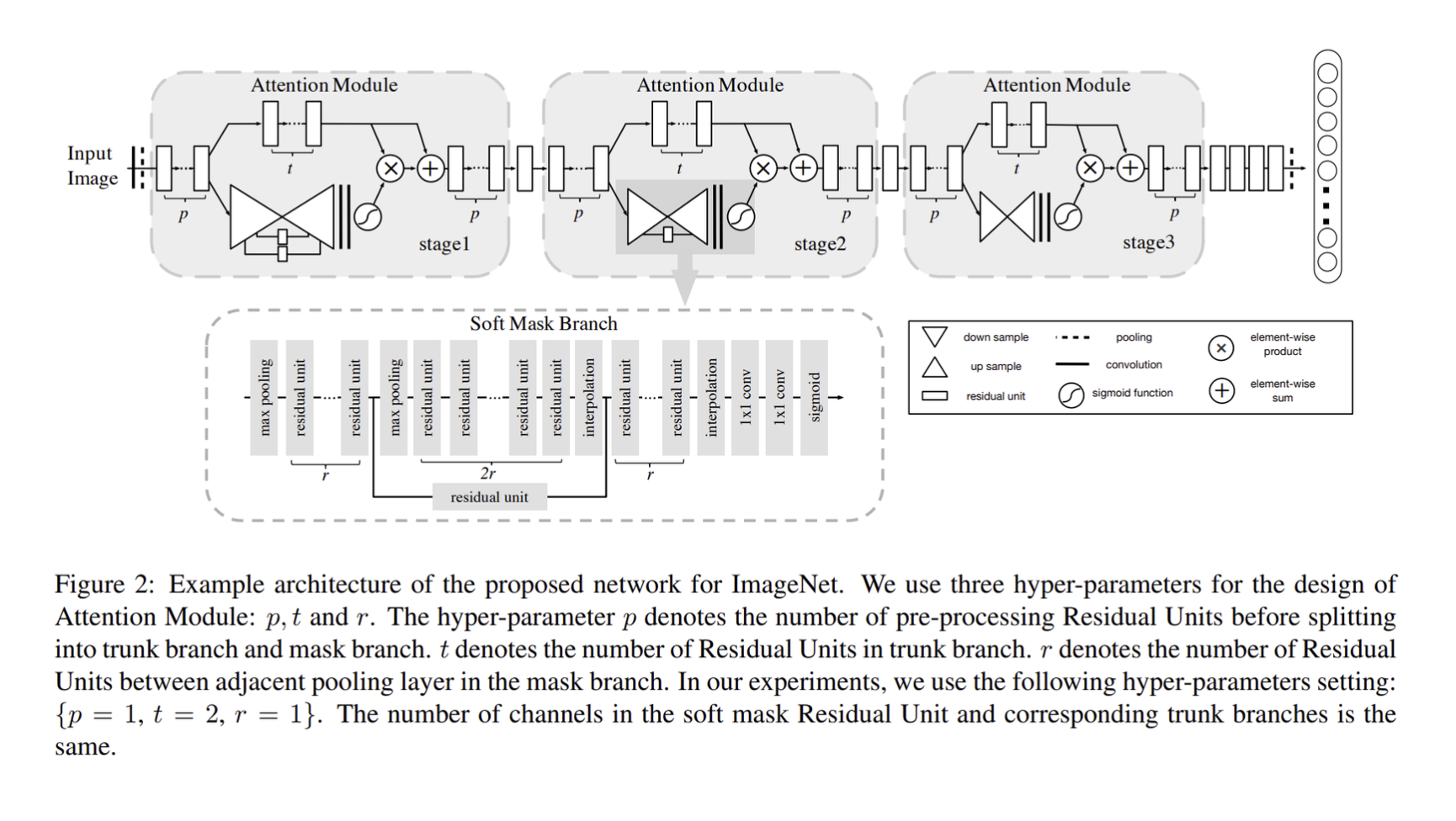
Residual Attention Network
- multiple Attention Module을 stack
- mask branch, trunk branch로 Attention module이 구성
- Trunk branch는 feature processing을 담당하며 어떤 network 구조를 사용해도 무방
- 논문에서는 pre-activation Residual Unit, ResNeXt, Inception을 RAN의 Attention 모듈을 구성하는 basic unit으로 사용
- T(x) 는 input이 x 일 때 trunk branch의 output
- Mask branch는 bottom-up top-down 구조로 output features인 T(x) 에 soft weight를 부여하는 same size mask M(x) 를 학습
- output mask는 Highway Network와 비슷한 형태로 trunk branch의 각 뉴런에게 gate 형식으로 작동
- Attention module H 의 output, i : spatial positions, c : index of channel

- 위 특성으로 Attention module이 noisy label의 잘못된 gradient를 방지하여 robust
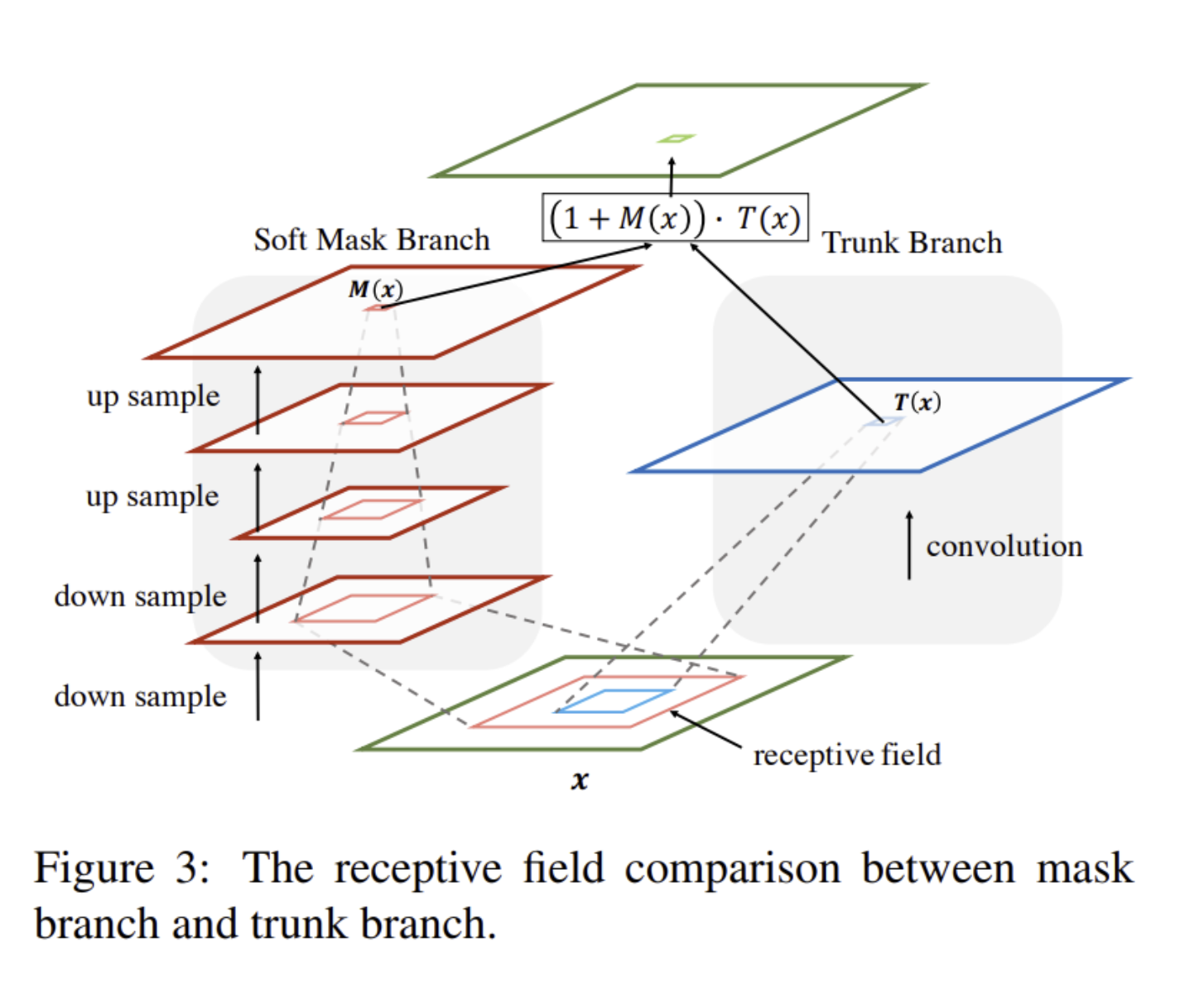
3.1. Attention Residual Learning
- Attention module을 단순하게 쌓으면 0~1 range의 dot product이 trunk branch의 유효한 정보를 손상시켜 성능 하락
- Residual 형태로 문제를 해결
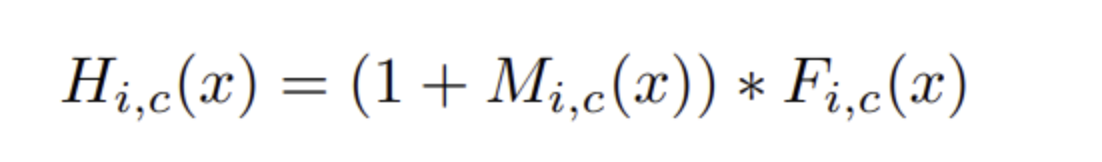
- Identity mapping이라는 cheat sheet을 제공하였기 때문에 Mask를 무시할 수 있지만 Stacked Attention Module을 사용하여 점차 refine
3.2. Soft Mask Branch
- MaxPooling과 BilinearUpsampling을 사용
- skip connection을 사용하여 여러 scale의 정보를 취합
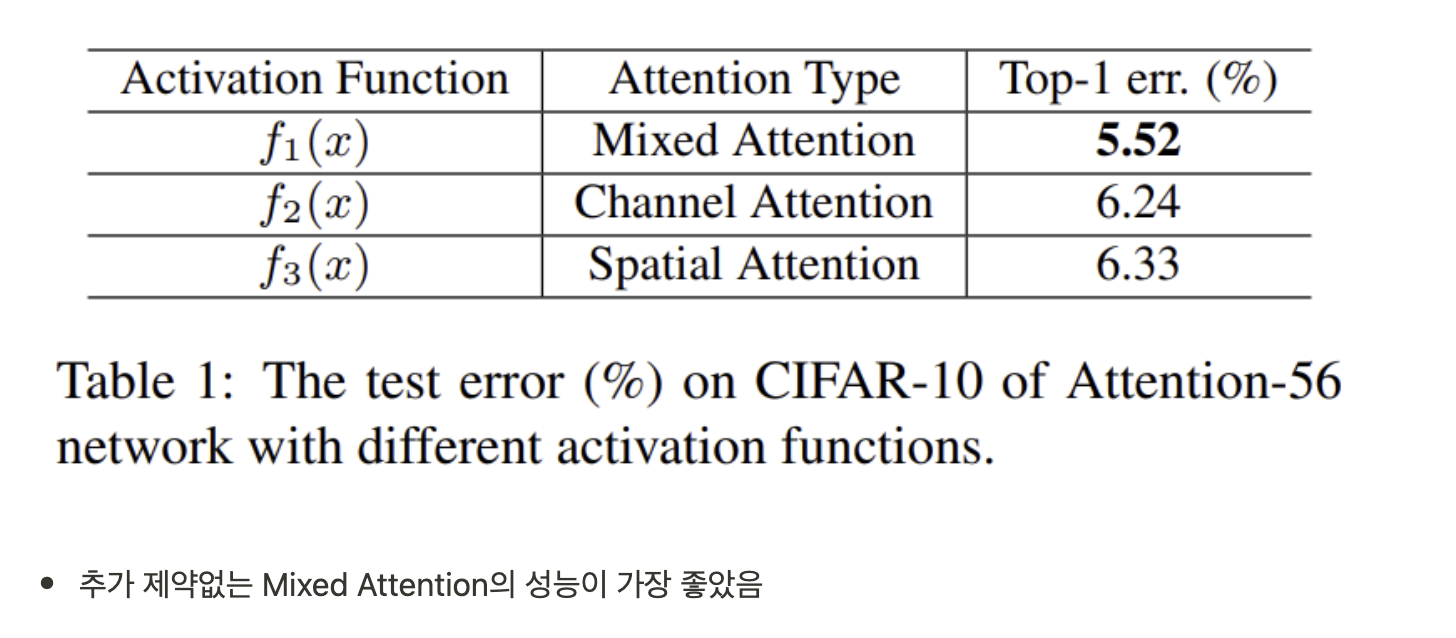
3.3. Spatial Attention and Channel Attention
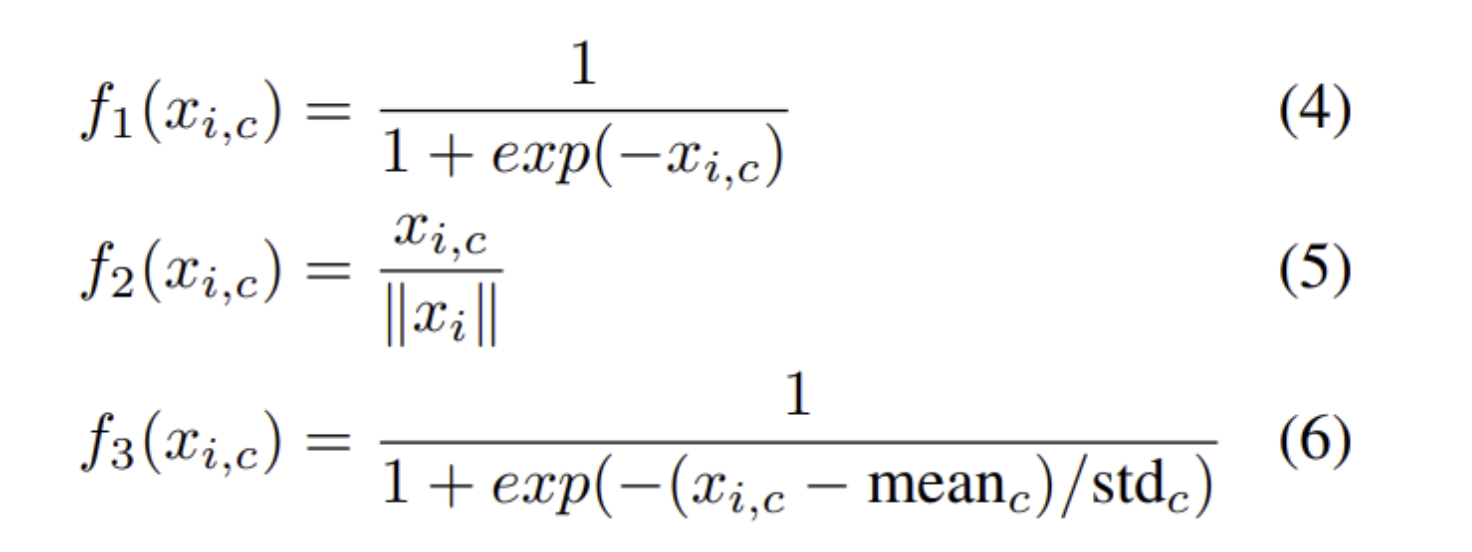
- f1 : channel, spatial에 모두 해당하는 mixed attention
- f2 : channel axis로 L2 normalization을 적용하여 spatial information을 제거한 channel attention
- f3 : feature map의 채널마다 정규화를 수행하여 spatial information을 담고있는 mask를 가지게 한 spatial attention
Experiments
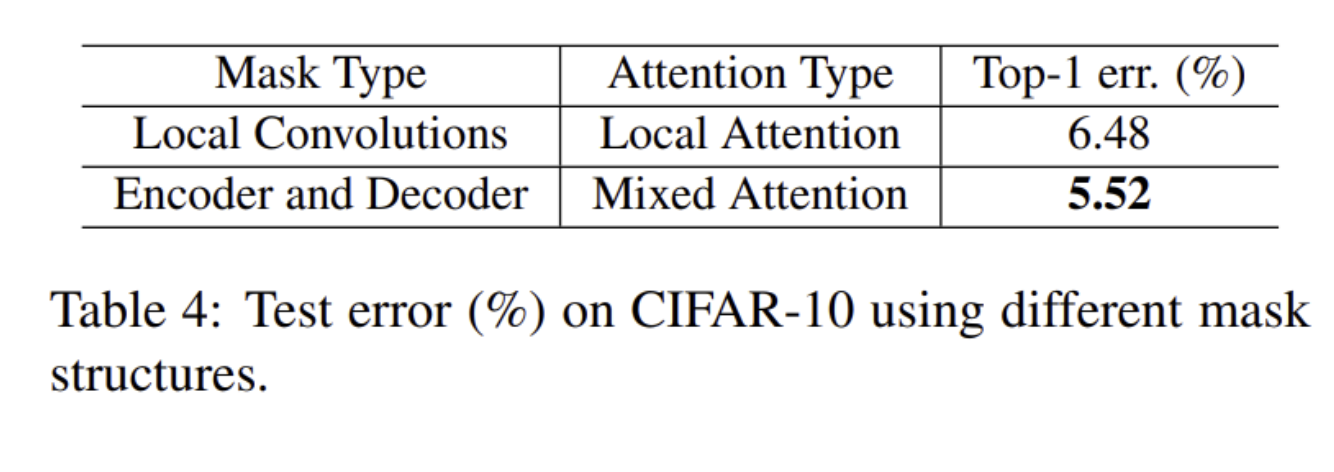
- Attention Residual Learning & Naive Attention Learning (No Residual)

- Encode-Decoder 형식 Mask branch & Local Convolution 형식 Mask branch
5. Discussion
- multiple Attention Module을 쌓은 Residual Attention Network를 제시
- mixed attention을 capture, convolution neural network에 쉽게 적용 가능
- residual attention learning으로 deep neural network에서 사용 가능
- CIFAR-10, CIFAR-100, ImageNet에서 image-classification task SOTA 달성
- 추후 연구로는 detection, segmentation에서도 RAN의 적용
Reference
[0] Fei Wang et al. (2017). "Residual Attention Network for Image Classification"
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more



