
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- multimodal
- CNN
- 오블완
- motion matching
- 모션매칭
- cv
- UE5
- 언리얼엔진
- 폰트생성
- Generative Model
- dl
- WinAPI
- Font Generation
- 생성모델
- 디퓨전모델
- 딥러닝
- WBP
- Diffusion
- ue5.4
- BERT
- Few-shot generation
- Unreal Engine
- ddpm
- animation retargeting
- NLP
- Stat110
- userwidget
- RNN
- GAN
- deep learning
Archives
- Today
- Total
Deeper Learning
[Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale 본문
AI/Deep Learning
[Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale
Dlaiml 2021. 12. 17. 15:17Alexey Dosovitskiy et al., (2020), Google Research, Brain Team
Abstract
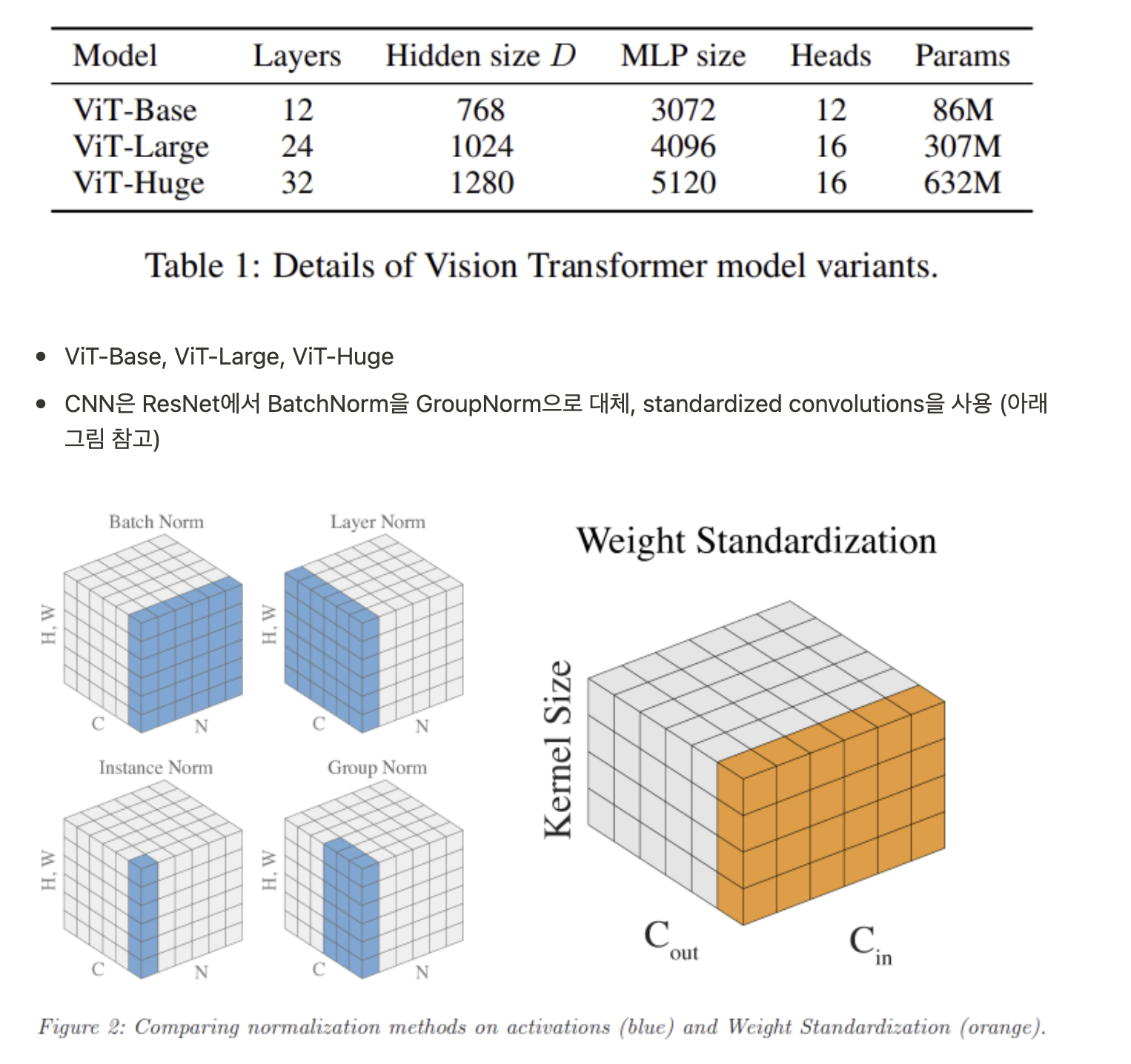
- 사실상 Transformer 구조가 NLP task에서 standard가 되었지만 vision task에서는 아직 적용에 한계가 있었음
- Transformer는 CNN을 대체하지 못하고 CNN의 일부 컴포넌트를 대체하는 식으로 결합하여 사용되고 있었음
- 이미지 분류 태스크에서 pure transformer로 좋은 성능을 낼 수 있음
- large datasets에서 pre-trained 한 ViT 모델은 mid-sized or small image recognition(ImageNet, CIFAR-100, VTAB, etc)에서 더 적은 computational cost를 필요로 하면서 기존 CNN base 모델의 성능을 뛰어넘는 SOTA를 달성
1. Introduction
NLP
- Self-attentoin-based 아키텍쳐, 특히 Transformer는 NLP에서 standard
- large text corpus에서 pre-train 후 smaller task-specific dataset에서 fine-tuning 하는 것이 일반적
- Transformer의 계산효율과 확장성으로 인해 100B가 넘는 parameters로 학습이 가능해졌음
- model과 dataset이 커져도 아직도 performance saturating이 관찰되지 않음
Computer Vision
- NLP에서의 성공에 영감을 받아 많은 연구들이 CNN기반 아키텍쳐에 self-attention을 접목
- 몇몇 연구는 CNN 전체를 self-attention 기반 모델로 대체하였으나 특수한 attention 패턴으로 인해 modern 하드웨어 가속을 적용할 수 없어 scale up이 불가능하였음
- large-scale image recognition에서는 여전히 ResNet-like 아키텍쳐가 SOTA
ViT
- standard Transformer를 이미지에 거의 그대로 적용
- Image를 patch들로 나누고 patch들에 linear layers를 통과시킨 임베딩 벡터들을 Transformer의 Input으로 지정
- Image patches는 NLP에서 token과 같은 방식으로 다뤄지며 supervised fashion으로 image 분류를 학습
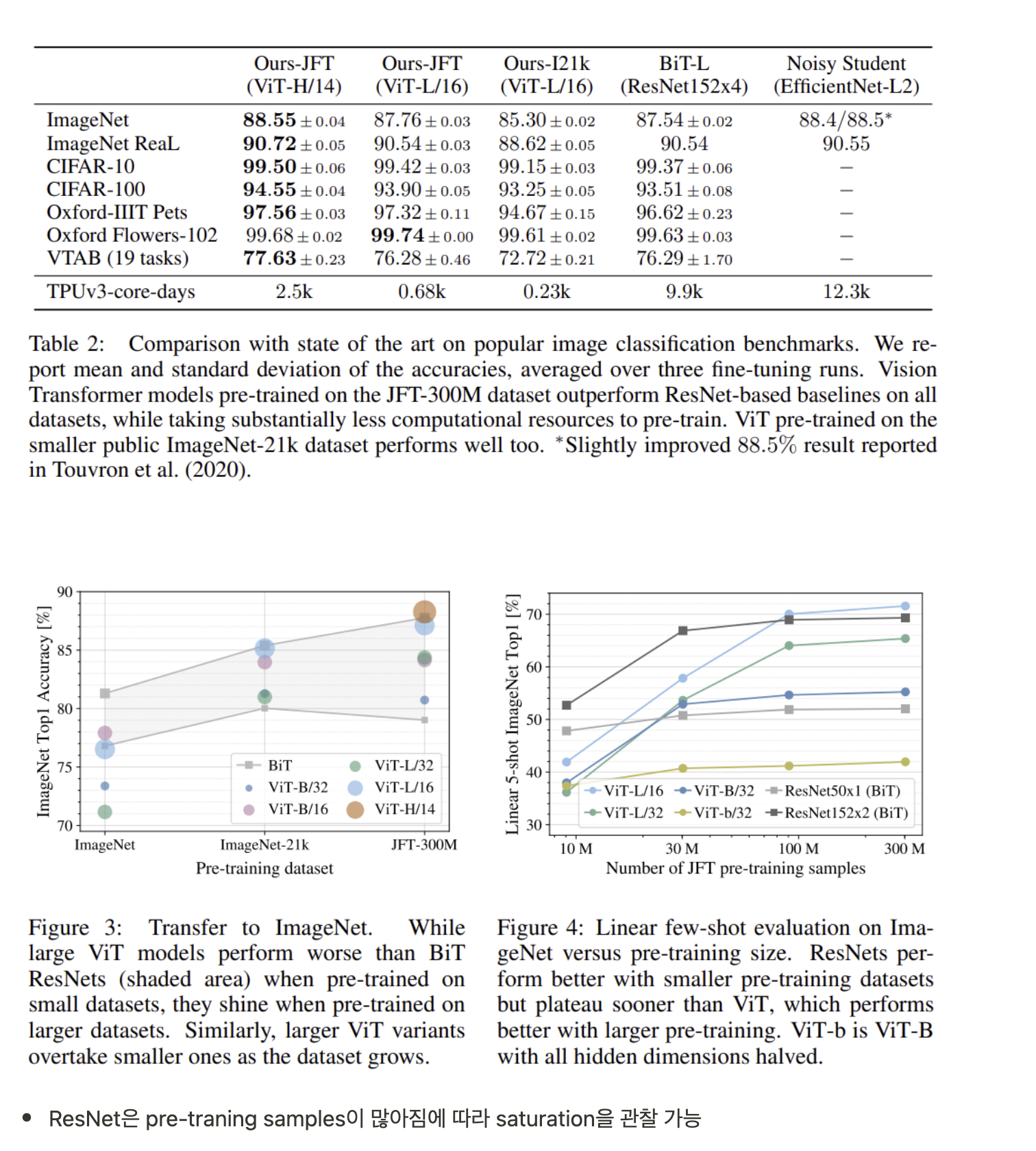
- ImageNet과 같은 mid-size 데이터셋에서 regularization없이 학습하였을 때 비슷한 size의 ResNet 보다 성능이 조금 떨어지는 결과를 보임
- 논문에서는 성능이 ResNet보다 떨어지는 이유를 부족한 Inductive biases라고 서술
- CNN에는 translation equivariance, locality와 같은 indective biases가 있음
- Trnasformer에는 위와 같은 inductive biases의 부재로 인해 충분하지 않은 데이터에서 학습 시 일반화 성능이 떨어짐
- 하지만 14M~ 300M의 larger dataset에서 ViT를 학습하게 되면 large scale training이 inductive bias보다 우위에 섬
- ImageNet-21k 또는 Google의 JFT-300M에서 pre-trained된 ViT는 ImgaeNet, ImageNet-Real, CIFAR-100에서 SOTA를 달성
2. Related Work
- Transformer, BERT
- Cordonnier et al. (2020), 2x2 patches를 사용한 image transformer
- image resolution을 낮추고 GPT로 AR형식의 generative model, iGPT
3. Method
- Original Transformer를 최대한 따르며 모델 디자인
3.1. Vision Transformer (ViT)

- NLP에서 Transformer는 1D의 sequence를 다루나 image는 2D sequence
- H×W×C 의 image를 N×(P2×C) 로 reshape (P = image patch resolution)
- Transformer는 고정된 latent vector size를 사용하기 때문에 patch를 flatten (P2×C) 하고 D dim으로 Linear Projection → Patch Embeddings
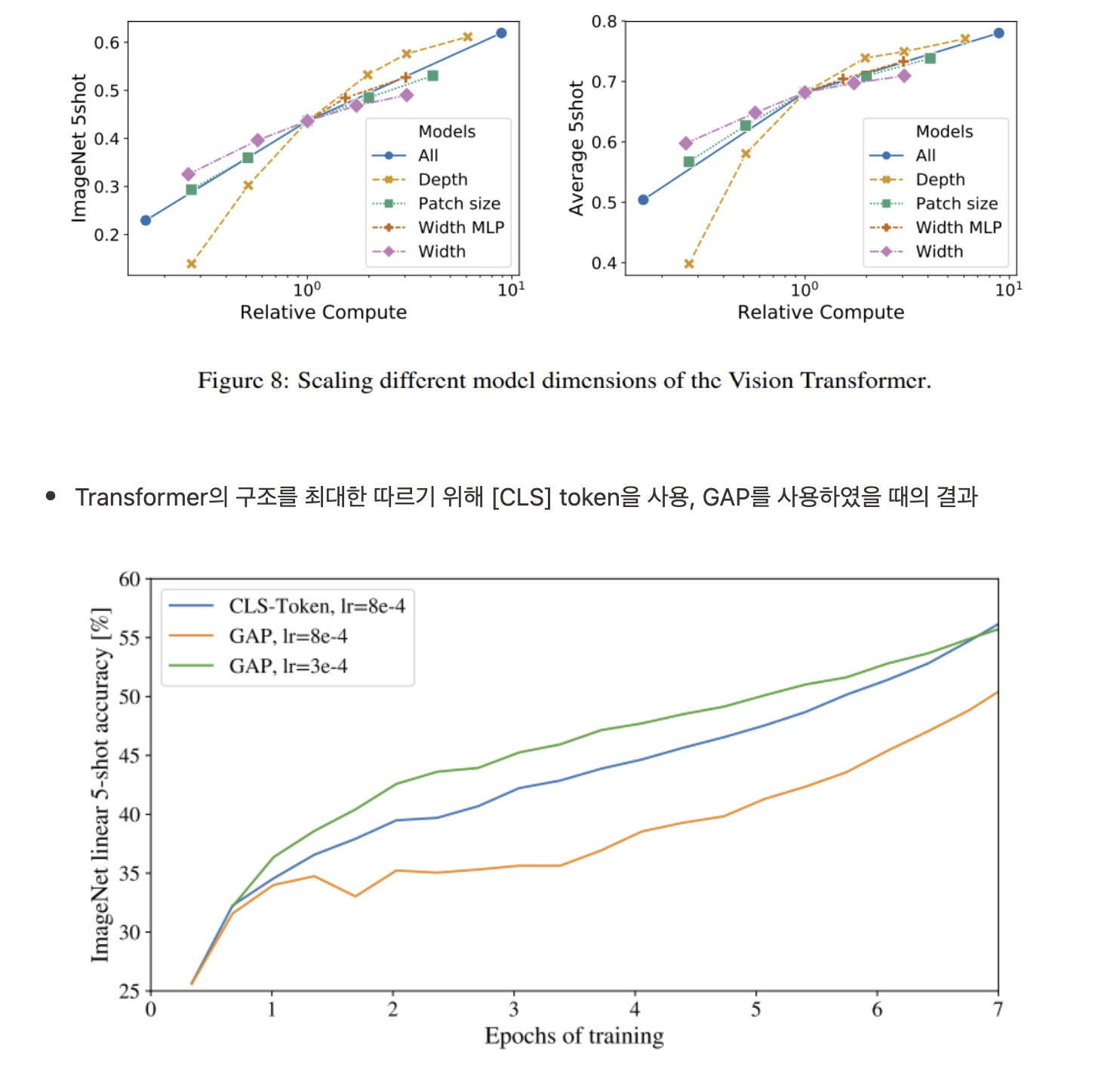
- BERT의 [CLS] token과 같은 역할을 하는 learnable token embedding을 설정(z00=xclass), 해당 token에 상응하는 output인 (z0L) 은 최종 image representation으로 classify를 위해 사용
- pre-training, fine-tuning 단계에서 classification head는 z0L 에 붙음
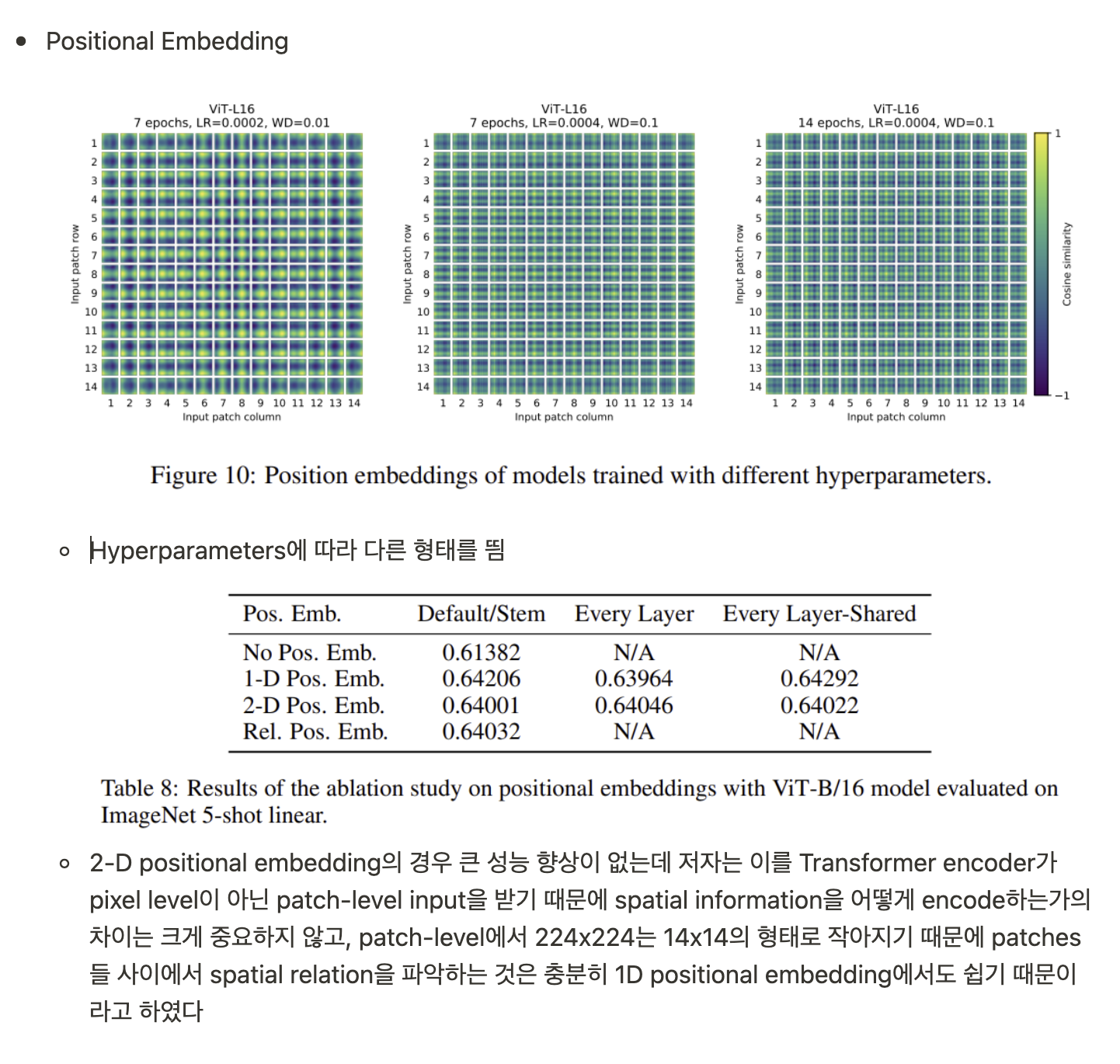
- Position Embeddings은 learnable 1D vectors를 사용, 2D-aware position embeddings을 사용해보았으나 성능 향상이 없었음

- xba 는 a번째 Transformer Encoder, b번째 token의 image patch
- E 는 Linear Projection of Flattened Patches
- MSA = (Multi-headed self-attention)
- LN = (Layer-Norm)
Inductive bias.
- CNN의 locality, 2차원 neighborhood structure, translation equivariance
- ViT에서는 MLP layer만이 local, translationally equivariance, self-attention은 global concept
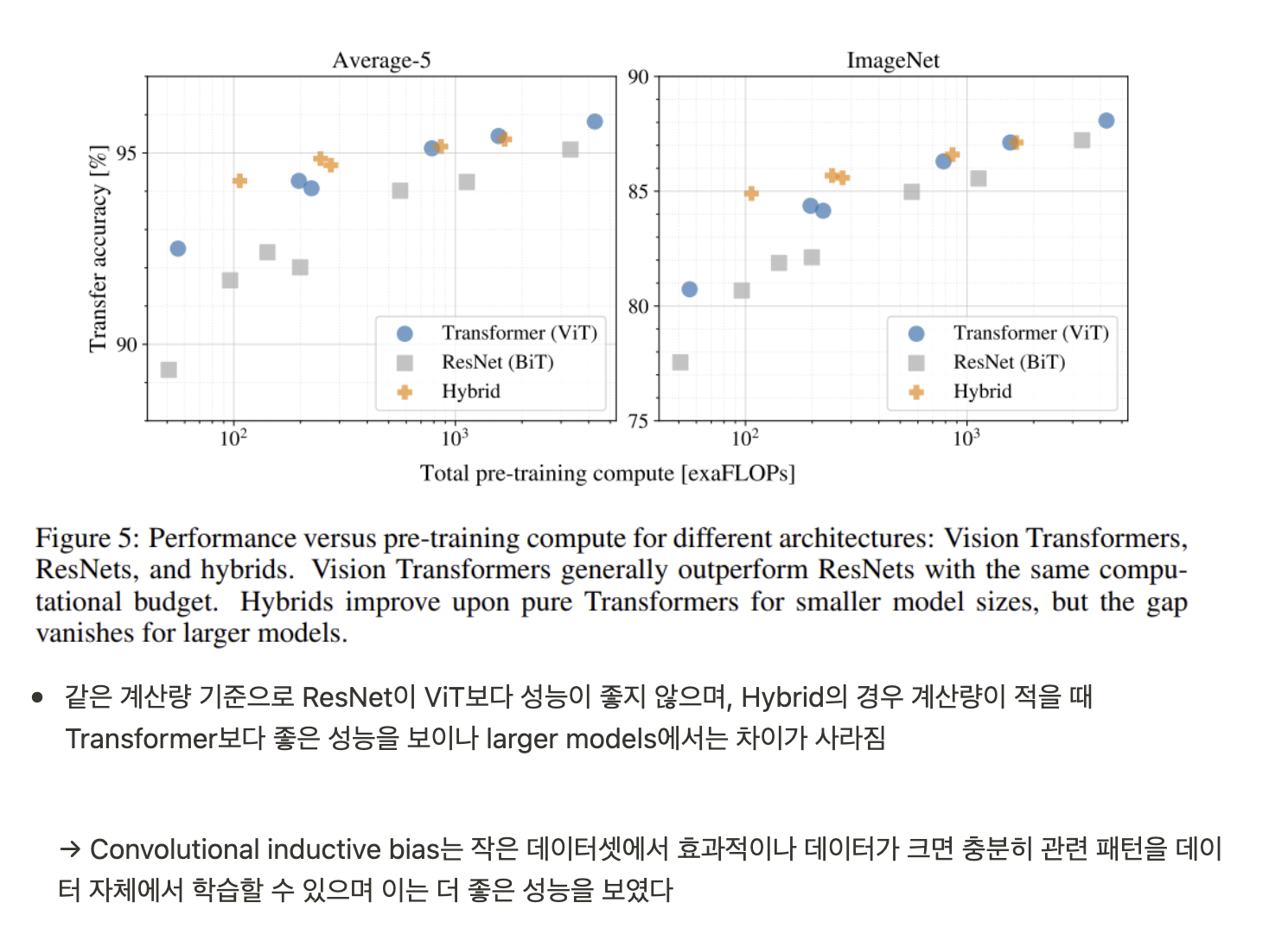
Hybrid Architecture.
- input이 raw image pathces가 아닌 CNN 구조를 통과한 feature maps
- spatial dimension을 flatten하여 1x1 size의 patches가 input이 될 수 있음
3.2. Fine-tuning and Higher Resolution
- Fine-tuning phase에서 pre-trained prediction head를 제거하고 zero-initialized D×K feedforward layer를 attach, K는 num of downstream classes
- 보통 pre-train resolution보다 high-resolution에서 fine-tune하는 것이 좋은 성능을 보임
- resolution이 커져도 동일한 patch size를 사용하여 효과적이고 긴 sequence length
- ViT는 임의의 sequence lengths를 다룰 수 있으며 pre-trained position embedding의 경우 sequence length가 달라지면 큰 의미를 갖지 않으므로 간단하게 sequence length에 따라 2D interpolation을 적용
- 오직 resolution 조정과 patch extraction이 image의 2D structure에 대해 ViT에 주입된 inductive bias
4. Experiments
- Hybrid 모델은 ResNet의 intermediate feature maps을 1pixel의 patch size로 ViT의 input으로 설정
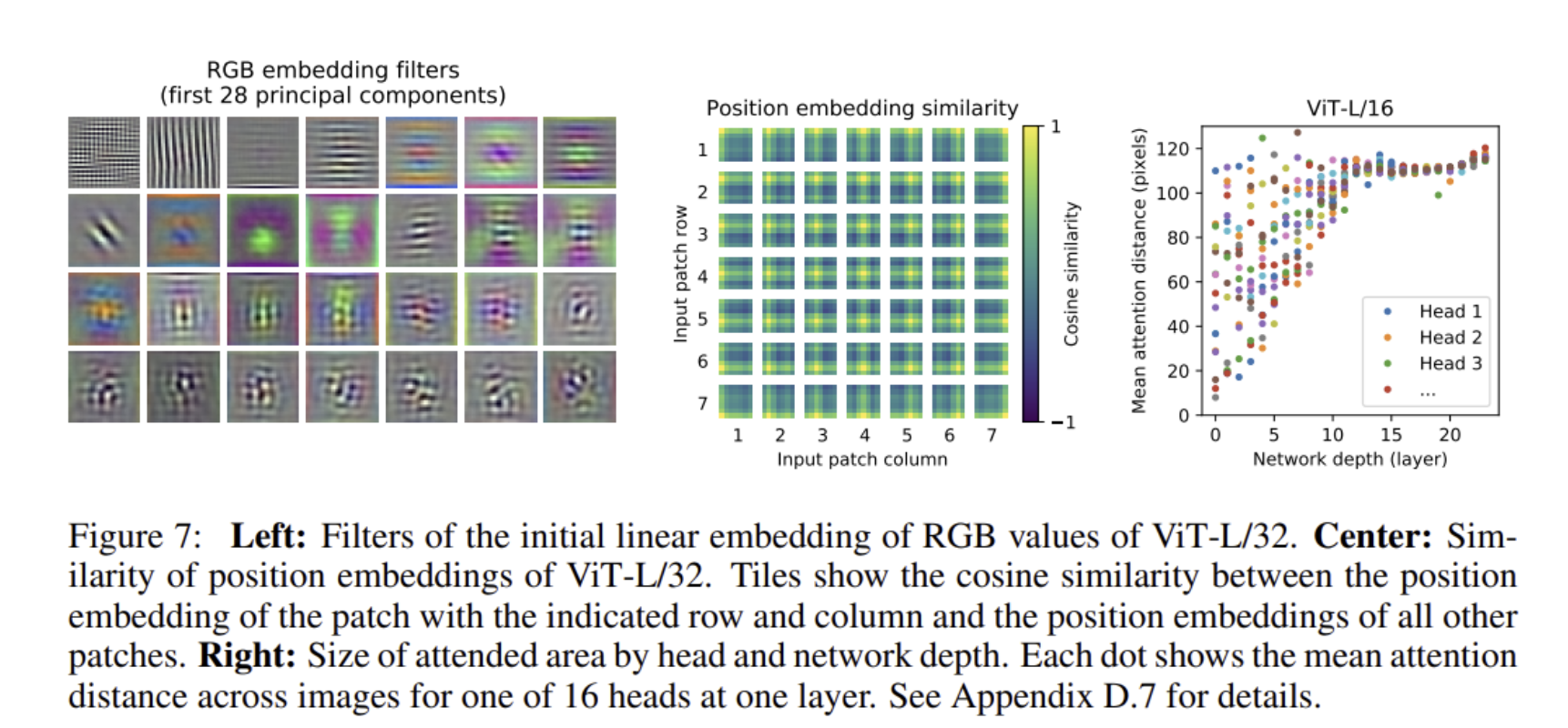
- ViT의 linear embedding을 통해서도 Conv에서 얻을 수 있는 filter visualization과 비슷한 형태의 filter를 얻음
- Position Embedding이 location을 어느정도 학습
Self-Supervision
- BERT와 같이 mask patch prediction을 통해 ViT-B/16이 ImageNet에서 scratch로 학습한 것보다 2% 정도 높은 정확도인 79.9% accuracy를 기록, supervised pre-training에 비해 4% 낮은 수치
- 50%의 patch embedding 중 80%를 [mask]로, 10%를 random patch로, 10%를 그대로 유지
- corrupted patch의 representation에서 3-bit의 mean color를 예측
5. Conclusion
- Transformer를 image recognition에 direct하게 적용
- 이전 연구들과 다르게 초기 patch extraction step을 제외하고 image-specific inductive biases를 아키텍쳐에 주입하지 않음
- 이미지를 patch의 sequence로 해석하고 Transformer Encoder에 NLP에서 사용되는 형식과 동일하게 input을 설정
- larget dataset pre-training할 때 전보다 적은 computation cost로 SOTA 달성
- self-supervised pre-training method에 대한 연구가 남은 과제
Appendix
- Transformer의 Depth를 늘리는 것이 가장 성능 향상에 좋음
- Axial Attention
- 2D shape input을 받아 Transformer block을 two Axial Transformer block으로 대체한 Axial-ViT 모델을 사용
- extra MLP 연산으로 인해 계산량이 늘어났지만 더 좋은 성능을 보임

- Attention map visualization

후기 & 정리
- NLP에서 standard 모델인 Transformer 모델을 Vision에 그대로 적용한 모델
- Vision task에서 CNN을 사용하지 않은 Transformer backbone으로 SOTA를 달성한 논문으로 큰 화제가 됨
- CNN 모델은 translation equivariance, locality 등 inductive bias로 인해 small dataset에서 ViT보다 좋은 성능을 보이고 ViT는 large dataset에서 data 자체에서 충분히 image-specific bias를 학습할 수 있어 더 좋은 성능을 보인다는 저자의 설명
- NLP에서 사용하던 Transformer를 그대로 사용하기 위해 patch-level sequence, 1D-positional embedding, cls token 등을 사용
- 논문을 읽으며 생겼던 positional embedding, patch-level, cls-token 등에 대한 궁금증을 Appendix에서 다양한 실험을 통해 해결
- Vision과 NLP에서 동일한 모델 아키텍쳐 사용

Reference
[0] Alexey Dosovitskiy et al. "An image is worth 16x16 words: Transformers for image recognition at scale".In International Conference on Learning Representations, 2021
[1] Siyuan Qiao, Huiyu Wang, Chenxi Liu, Wei Shen, and Alan Yuille. Weight standardization. arXiv preprint arXiv:1903.10520, 2019.
'AI > Deep Learning' 카테고리의 다른 글
| MobileNetV2: Inverted Residuals and Linear Bottlenecks (0) | 2021.12.24 |
|---|---|
| Residual Attention Network for Image Classification (0) | 2021.12.22 |
| ArcFace: Additive Angular Margin Loss for Deep Face Recognition (0) | 2021.12.13 |
| You Only Look Once: Unified, Real-Time Object Detection (0) | 2021.11.30 |
| Pixel-Adaptive Convolutional Neural Networks (0) | 2021.11.16 |
'AI/Deep Learning' Related Articles
more



