
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- dl
- Few-shot generation
- WinAPI
- Unreal Engine
- motion matching
- cv
- 언리얼엔진
- UE5
- ddpm
- Diffusion
- ue5.4
- 디퓨전모델
- 모션매칭
- NLP
- RNN
- deep learning
- Stat110
- 생성모델
- animation retargeting
- multimodal
- 오블완
- userwidget
- BERT
- Generative Model
- 폰트생성
- 딥러닝
- CNN
- WBP
- Font Generation
- GAN
Archives
- Today
- Total
Deeper Learning
MobileNetV2: Inverted Residuals and Linear Bottlenecks 본문
Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen Google Inc. CVPR
Abstract
- 다양한 task, model size에서 mobile model SOTA를 달성한 MobileNetV2를 제시
- SSDLite를 사용한 object detection, DeepLabv3 기반 semantic segmentation에서 MobileNetV2를 사용
- thin bottle neck layers 간 shortcut connection에서 inverted residual structure를 사용
- intermediate expansion layer는 lightweight depthwise convolution을 사용
- narrow layers에서 representation power를 유지하기 위해 non-linearities를 제거하는 것이 성능 향상
1. Introduction
- modern 아키텍쳐는 많은 cost를 요구, computational cost와 accuracy는 trade-off 관계
- mobile 또는 제약이 있는 환경을 위한 아키텍쳐를 제시
- 성능을 유지하면서 연산량과 메모리를 효과적으로 줄인 SOTA mobile model
- main contribution module: the inverted residual with linear bottleneck
- low-dimensional compressed representation
- expanded to high dimension
- filtered with a lightweight depthwise convolution
- projected back to a low-dimensional representation with a linear convolution
- 모든 modern framework에서 standard operation을 이용하여 쉽게 적용 가능
- memory 사용량을 효과적으로 줄이는 mobile design을 위한 모듈
3. Preliminaries, discussion and intuition
3.1. Depthwise Seperable Convolutions
- MobileNetV1 참고
- MobileNetV2에서는 3x3 depthwise seperable convolutions을 사용하여 연산량을 8~9배 줄임
- Inception, Xception에서 부터 이어져온 가정: “The mapping of cross-channels correlation and spatial correlation can be entirely decoupled”
- input channel을 모두 고려하여 filtering 하지 않아도 괜찮다
- 1x1 conv → output channel을 일정 단위로 잘라 따로 3x3 conv를 수행, channel correlation, spatial correlation을 따로 mapping (Xception)
- 3x3 depth-wise conv → 1x1 point-wise conv (MobileNet)
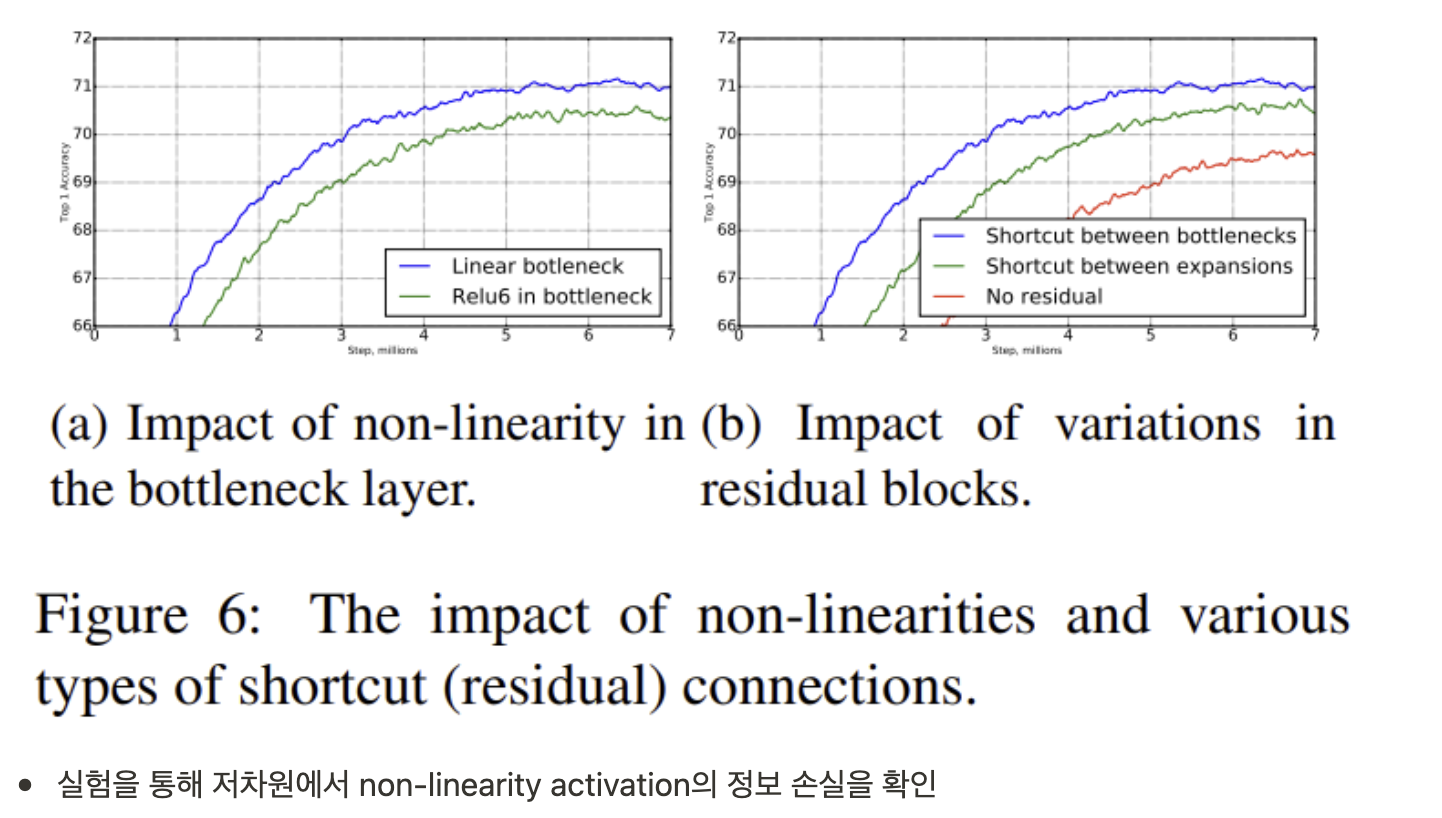
3.2. Linear Bottlenecks
- input image는 set of layer activations에서 “manifold of interest”
- ReLU에서 양수는 값이 그대로 출력되며 결국 양수에 한해서 linear transformation의 형태
- ReLU가 저차원 변환에서 사용될 때 input manifold에 대해 정보 손실

→ manifold of interest가 low-dimensional 이라면 linear bottleneck layer를 convolutional blocks에 추가하여 manifold of interest를 capture 가능
- non-linearities로 인한 정보 손상을 방지
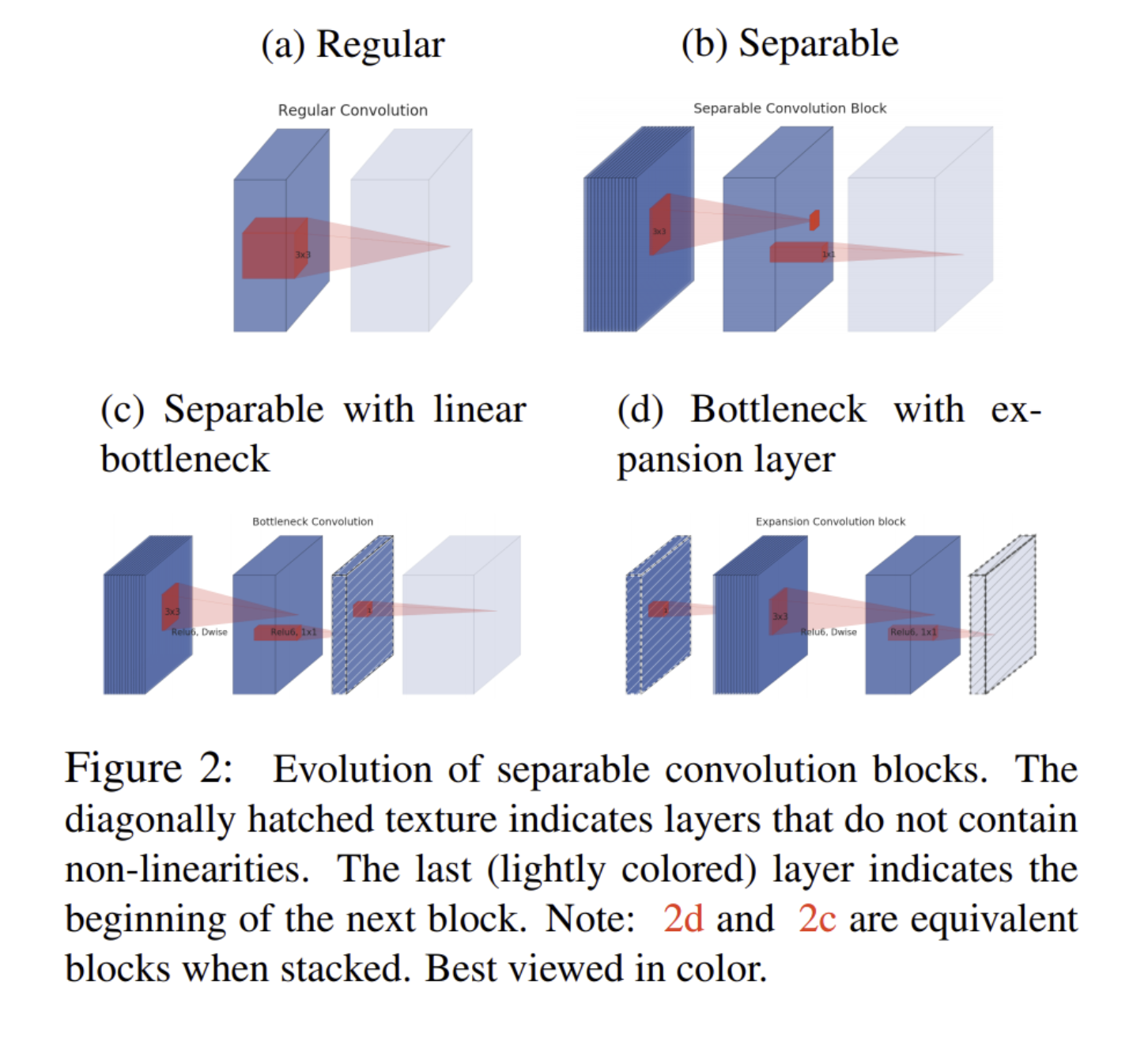
3.3. Inverted residuals
- Bottleneck, expansion layer 구조
- Residual block & Inverted residual block
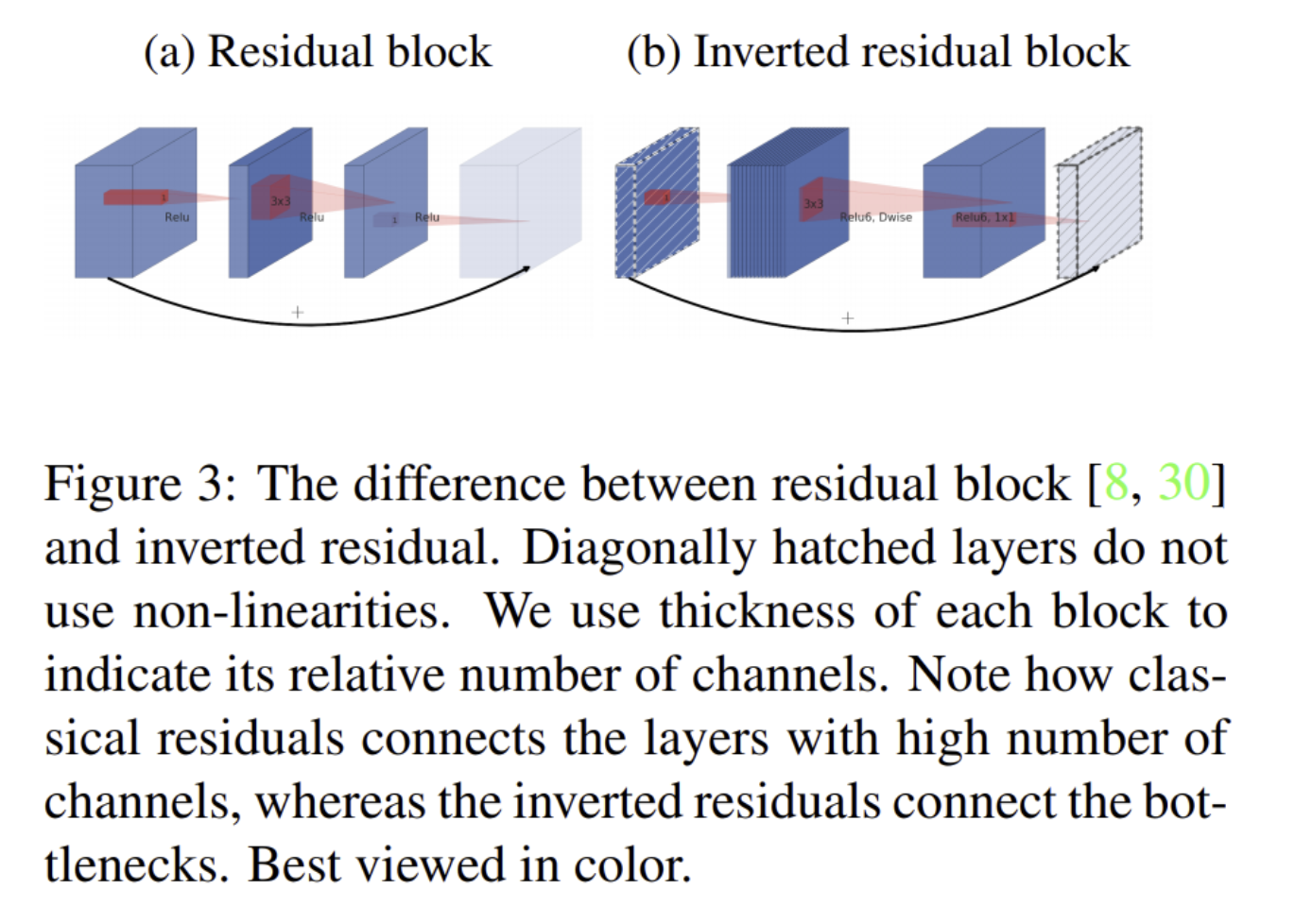
- 저차원의 layer에 정보가 잘 저장되어 있다는 가정하에 사용한 inverted residuals
- narrow layer에서 skip connection을 하기 때문에 효율적인 memory footprint
3.4. Information flow interpretation
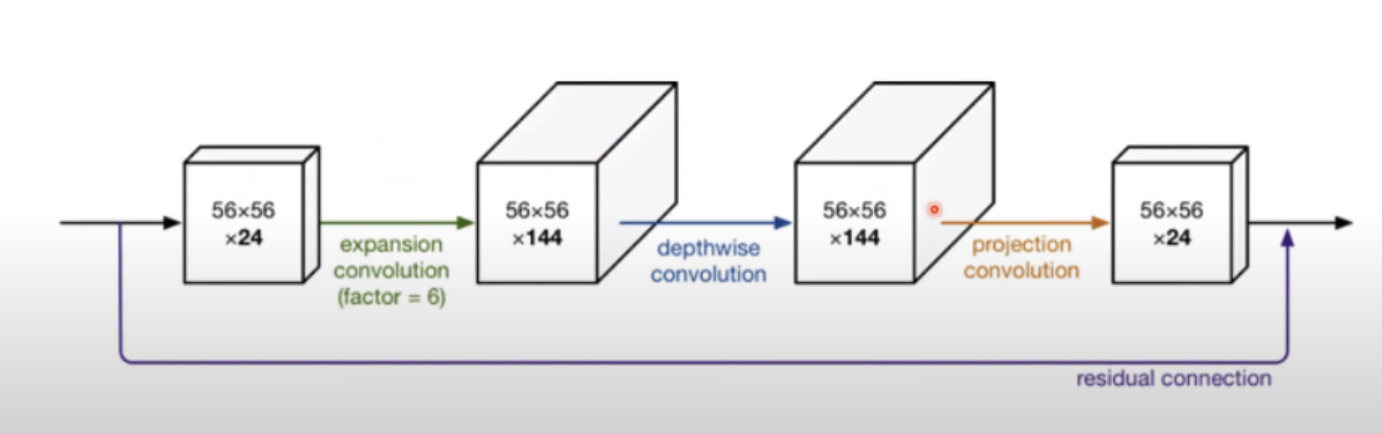
- expansion convolution의 factor가 expressiveness를 조정
- projection convolution으로 capacity를 조정
- future work도 해당 separation에 대한 exploration을 제시
4. Architecture
- Mobilenet V2 module layer architecture
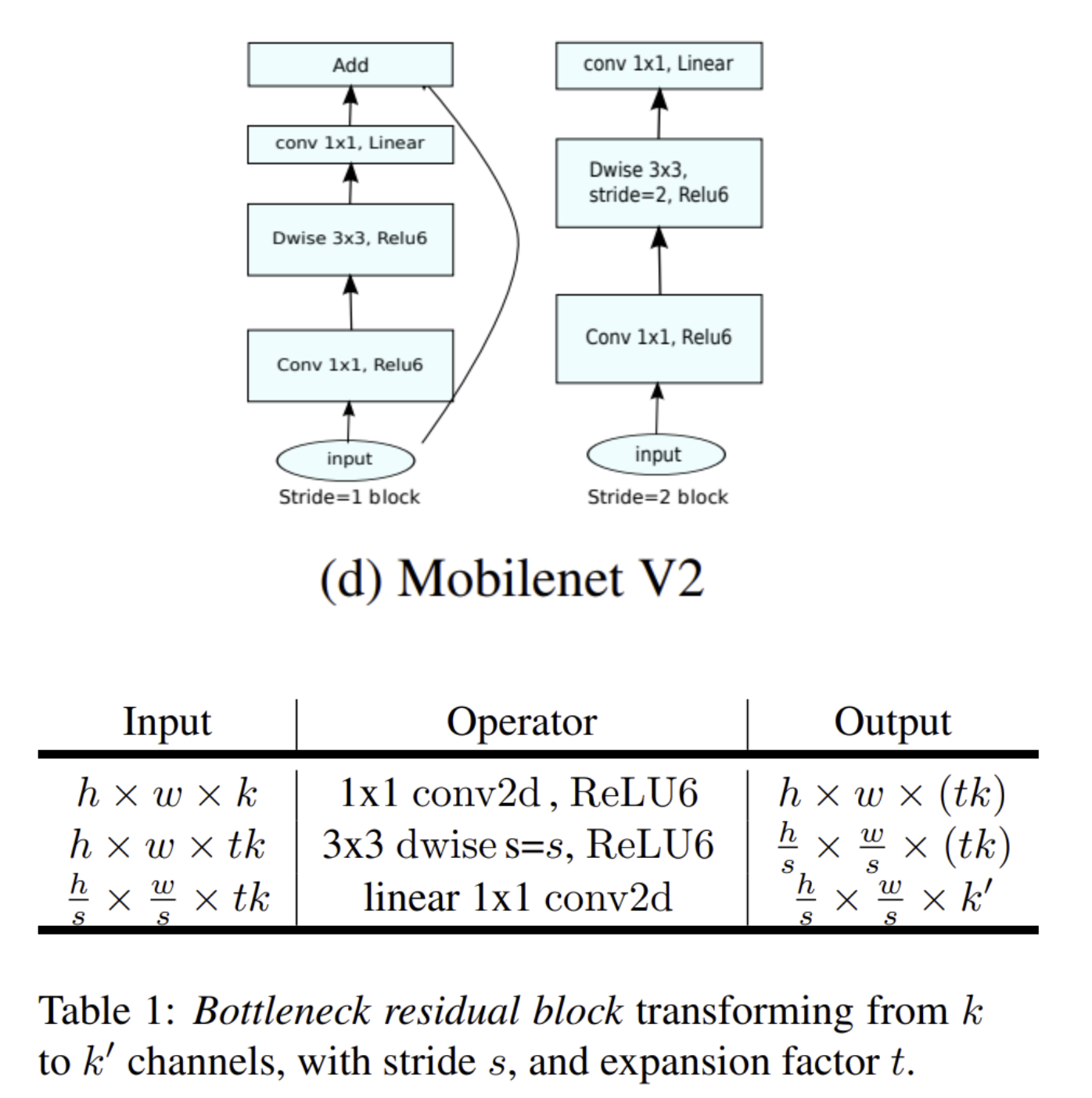
- MobileNetV2 Architecture

- Depthwise Seperable Convolutions 계산량
- di input dim, dj output dim, k kernel size
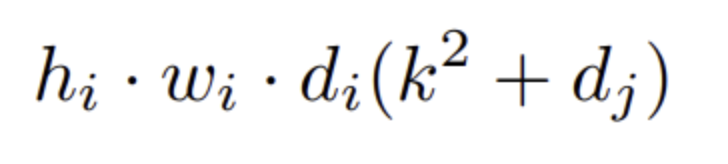
- MobileNetV2의 Bottleneck residual block은 추가로 1x1 conv가 수행되므로
- hwtd′d′+hwtd′kkd′+hwd″
- h * w * d_i * t (d' + k^2+d'') 의 계산량 (t는 expansion parameter)
5. Experiments
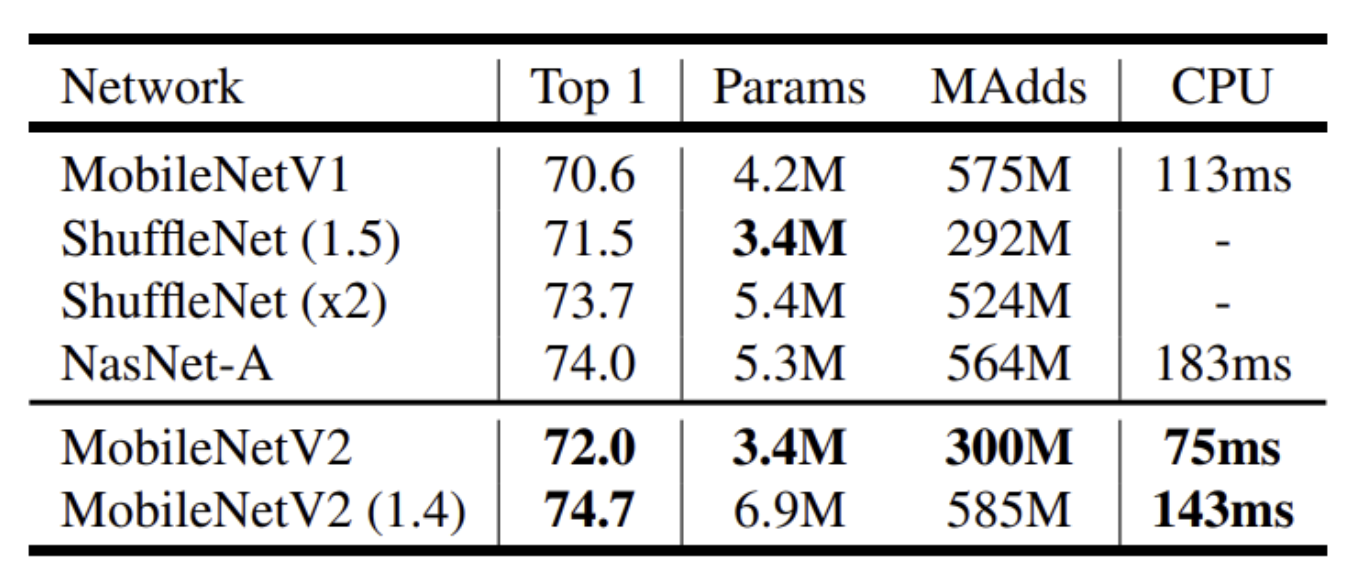
- ImageNet Image Classification
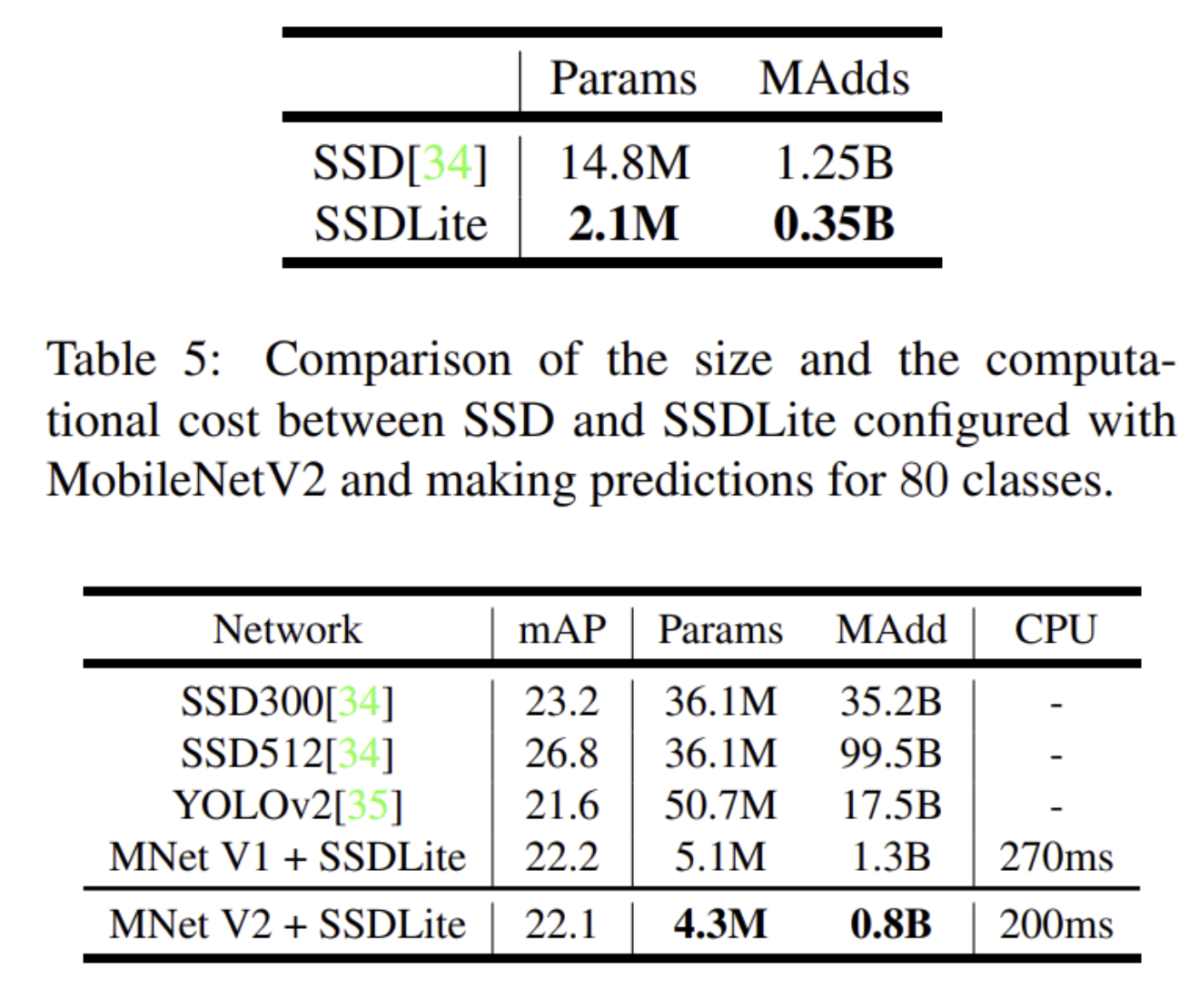
- Object detection
- Semantic Segmentation
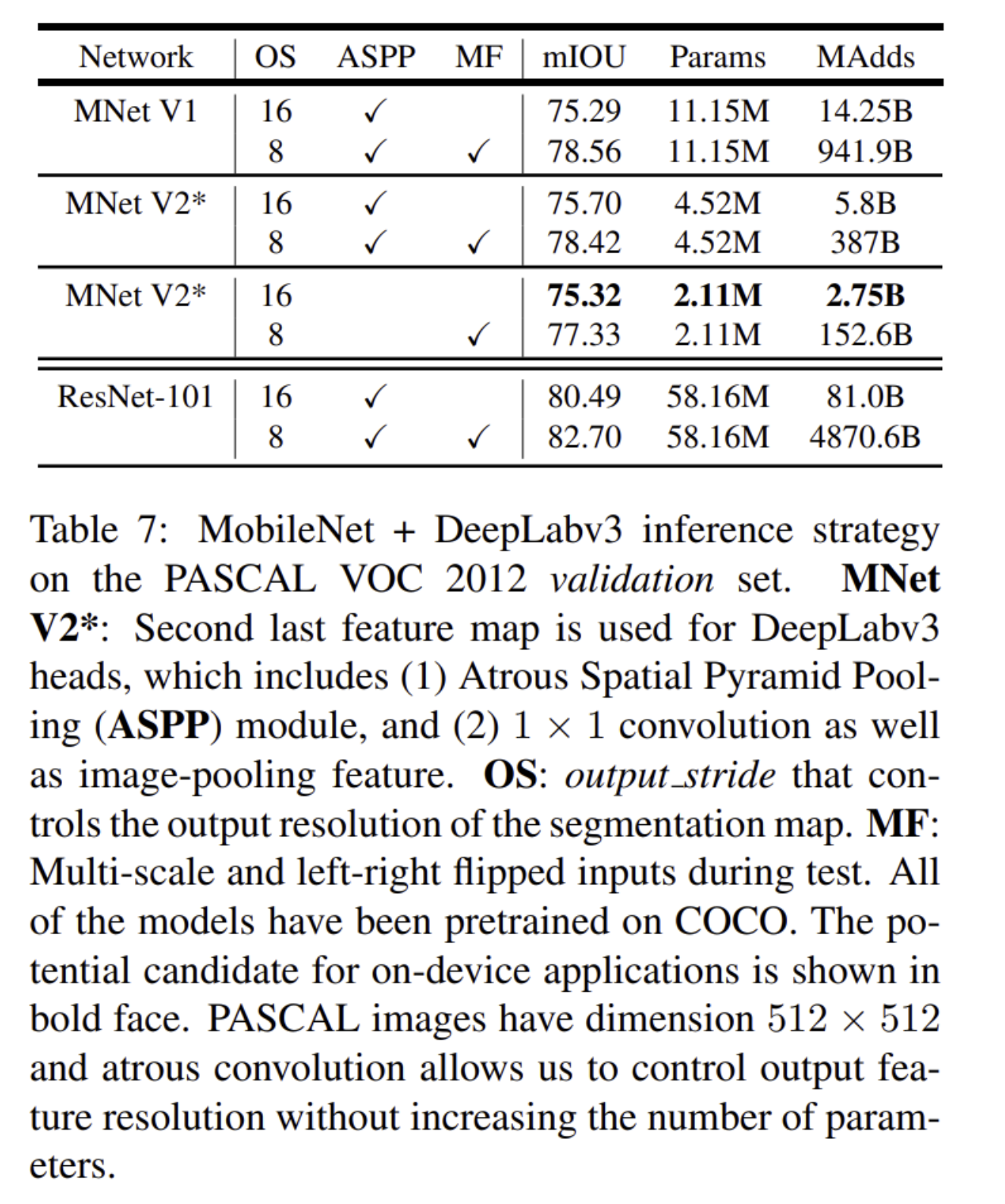
7. Conclusions and future work
- 효율적이고 간단한 network architecture
- memory-efficient inference, 딥러닝 framework의 standard ops로 쉽게 구현 가능
- Image classification, Object detection, Semantic segmentation에 모두 사용
후기 & 정리
- Bottle neck residual block을 추가한 MobileNet V2를 제시
- 기존에 자주 사용하는 연산들로만 구성 가능 한 block으로 쉽게 적용 가능
- 차원 축소와 ReLU를 사용할 때 생기는 문제를 해결하기 위해 channel reduction이 아닌 channel expansion 포함한 Inverted Residual을 사용, Residual Block의 last 1x1 conv에 ReLU를 사용하지 않음
- Xception의 가정인 “The mapping of cross-channels correlation and spatial correlation can be entirely decoupled”에서 나온 Depthwise Separable Convolution, ReLU의 저차원에서의 정보 손실에서 나오게 된 Linear Bottleneck, Inverted Residuals을 사용하여 완성한 Inverted Residuals with Bottleneck
- Xception, Inception까지 함께 복습하며 1x1 conv, 정보 손실 등에 대한 이전 논문들의 가정과 실험들에 대해 다시 정리할 수 있었음.
- 효율적이고 가벼운 모듈, 하지만 성능 하락 또한 크지 않다.
Reference
[0] Mark Sandler Andrew Howard Menglong Zhu Andrey Zhmoginov Liang-Chieh Chen Google Inc. 2018. "MobileNetV2: Inverted Residuals and Linear Bottlenecks" CVPR
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more




Comments