
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 생성모델
- UE5
- animation retargeting
- 디퓨전모델
- Unreal Engine
- Diffusion
- dl
- 언리얼엔진
- 딥러닝
- WinAPI
- deep learning
- RNN
- ue5.4
- userwidget
- WBP
- Stat110
- NLP
- Font Generation
- GAN
- motion matching
- 오블완
- 모션매칭
- multimodal
- ddpm
- CNN
- BERT
- Few-shot generation
- Generative Model
- 폰트생성
- cv
- Today
- Total
목록inductive bias (2)
Deeper Learning
 MLP-Mixer: An all-MLP Architecture for Vision
MLP-Mixer: An all-MLP Architecture for Vision
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy. Google Research, Brain Team. (2021.05) Abstract CNN은 vision task에서 널리 사용되었음, 최근에는 ViT와 같이 attention-based networks도 사용 convolution과 attention는 좋은 성능을 내기 위한 필수조건이 아님 오직 multi-layer perceptrons을 사용한 MLP-..
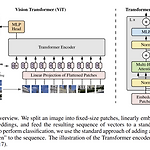 [Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale
[Vision Transformer, ViT] An Image is Worth 16x16 Words: Transformers For Image Recognition At Scale
Alexey Dosovitskiy et al., (2020), Google Research, Brain Team Abstract 사실상 Transformer 구조가 NLP task에서 standard가 되었지만 vision task에서는 아직 적용에 한계가 있었음 Transformer는 CNN을 대체하지 못하고 CNN의 일부 컴포넌트를 대체하는 식으로 결합하여 사용되고 있었음 이미지 분류 태스크에서 pure transformer로 좋은 성능을 낼 수 있음 large datasets에서 pre-trained 한 ViT 모델은 mid-sized or small image recognition(ImageNet, CIFAR-100, VTAB, etc)에서 더 적은 computational cost를 필요로 하면..