
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- UE5
- 언리얼엔진
- ddpm
- ue5.4
- GAN
- Few-shot generation
- animation retargeting
- motion matching
- userwidget
- multimodal
- WinAPI
- dl
- Generative Model
- CNN
- Unreal Engine
- Font Generation
- deep learning
- 디퓨전모델
- BERT
- Stat110
- cv
- Diffusion
- 오블완
- RNN
- 딥러닝
- 폰트생성
- 모션매칭
- NLP
- WBP
- 생성모델
Archives
- Today
- Total
Deeper Learning
MLP-Mixer: An all-MLP Architecture for Vision 본문
Ilya Tolstikhin, Neil Houlsby, Alexander Kolesnikov, Lucas Beyer, Xiaohua Zhai, Thomas Unterthiner, Jessica Yung, Andreas Steiner, Daniel Keysers, Jakob Uszkoreit, Mario Lucic, Alexey Dosovitskiy. Google Research, Brain Team. (2021.05)
Abstract
- CNN은 vision task에서 널리 사용되었음, 최근에는 ViT와 같이 attention-based networks도 사용
- convolution과 attention는 좋은 성능을 내기 위한 필수조건이 아님
- 오직 multi-layer perceptrons을 사용한 MLP-Mixer를 제시
- MLP-Mixer는 2가지 타입의 layers를 포함
- patches에 independent 하게 적용되는 MLP (per-location features mixing)
- patches를 가로지르며 적용되는 MLP (spatial information mixing)
- large dataset에서 학습하고 여러 regularization method를 적용하면 MLP-Mixer은 classification task에서 같은 cost 기준 SOTA 모델과 견줄만한 성능을 보임
- 이 논문이 확립된 CNN과 Transformer를 넘어서는 후속 연구들을 활성화시키기를 바람
Introduction
- larget dataset과 하드웨어 성능 향상은 computer vision의 패러다임을 바꾼다
- CNN이 사실상 vision에서 정석이었으나 최근 self-attention layer를 base로 하는 ViT는 SOTA를 달성
- ViT는 인간이 설계한 visual feature, inductive bias 제거하는 long-lasting 트렌드를 이어갔으며 raw data에서의 학습에 더 의존하였음
- 기술적으로 간단하나 성능이 좋은 convolution과 self-attention을 사용하지 않는 MLP-Mixer를 제시
- Mixer는 MLPs로 구성되어있으며 spatial location 또는 feature channel axis로 반복적으로 MLP 연산을 함
- Mixer는 기본적인 matrix multiplication 연산의 반복과 data layout change(reshape, transpose), scalar nonlinearities만 사용

- (patches x channels) shape의 linear projected image pathces(table)를 input으로 받음
- Mixer Layer는 token-mixing MLP와 channel-mixing MLP로 구성되어 있으며 각 MLP는 2개의 fc layer와 GELU 활성화 함수로 구성되어 있음
- Channel mixing MLP
- 다른 channel 간 관계를 학습하기 위한 MLP
- 각 token에 independent하게 적용됨 (table의 row가 input)
- Token mixing MLP
- 다른 spatial locations간 관계를 학습
- 각 channel에 independent하게 적용 (table의 column이 input)
- 위 두 타입의 layer가 patch 차원, channel 차원에서의 상호작용을 가능하게 함
- Mixer는 매우 특별한 CNN이라고 볼 수 있음
- channel mixing은 1x1 conv로 볼 수 있음
- 전체 receptive field에서 single channel depth-wise convolution & parameter sharing은 token mixing으로 볼 수 있음
- 역은 성립하지 않음 (Mixer의 special case는 전형적인 CNN과 같을 수 없음)
- 단순한 구조임에도 large datasets에서 pre-training 하면 accuracy/cost trade-off로 SOTA에 근접한 성능을 보임
- ViT와 마찬가지로 작은 dataset에서 pre-training할 경우 CNN 기반 모델 성능을 넘어서지는 못하였음
Mixer Architecture
modern deep vision 아키텍처는 features를 mix하는 layer를 포함하고 있음
(1) given spatial location
(2) between different spatial location
- CNN의 N x N convolutions과 pooling은 (2)의 역할을 함
- 1x1 conv는 (1)의 역할을 하며 large kernel은 (1)과 (2)의 역할을 모두 수행
- ViT에서 self-attention은 (1)과 (2)의 역할, MLP-block은 (1)의 역할을 수행
- Mixer 구조는 (1)과 (2)를 명시적으로 분리, channel-mixing은 (1), token-mixing은 (2)
Mixer Architecture
- S = 겹치지 않는 image patches 수, C = projected hidden dimension
- input table X 는 S×C 의 shape
- input image가 (H,W) resolution을 가지고 patch size가 (P,P) 라면 S=HW/P2
- 모든 patch는 동일한 projection matrix를 사용하여 같은 차원으로 linearly projection
- token-mixing MLP는 X 의 column에 대해 연산하므로 XT 의 row가 하나의 input이 됨
- channel-mixing MLP는 X 의 row에 대해 연산
- LayerNorm과 skip-connection, activation function(σ=GELU)까지 포함하여 수식으로 정리하면

- ViT의 complexity는 quadratic, Mixer의 input table에서 C 는 patch size와 상관없이 독립적인 설정 가능한 값이며 S 는 patches의 수이기 때문에 Mixer에서 계산 복잡도는 CNN과 동일하게 pixel 수(patch 수)에 linear
- channel mixing MLP에서 같은 parameter를 사용하는 것은 positional invariance, prominent feature of convolution의 이점이 있는 일반적인 case
- 하지만 channel간 통합된 parameter를 사용하는 것은 일반적이지 않은 case
- separable convolution은 각 채널에 convolution을 독립적으로 사용하지만 다른 convolution kernel을 사용
- Mixer의 token mixing MLP는 같은 kernel을 모든 채널에 독립적으로 사용
- 이러한 parameter tying은 C,S 가 증가할 때 아키텍처가 너무 커지는 문제를 방지해주어 memory를 절약
- 놀랍게도 parameter tying은 성능에 크게 영향을 미치지 않았음
- Mixer의 각 layer는 같은 size의 input을 다루며 이는 Transformer와 비슷한 isotropic 디자인
- 대부분 CNN은 깊은 layer에서 resolution이 작아지며 channel이 증가하는 pyramidal structure
- ViT와 다르게 position embedding을 사용하지 않는데 이는 token-mixing MLPs가 input tokens의 순서를 고려하기 때문
Experiments
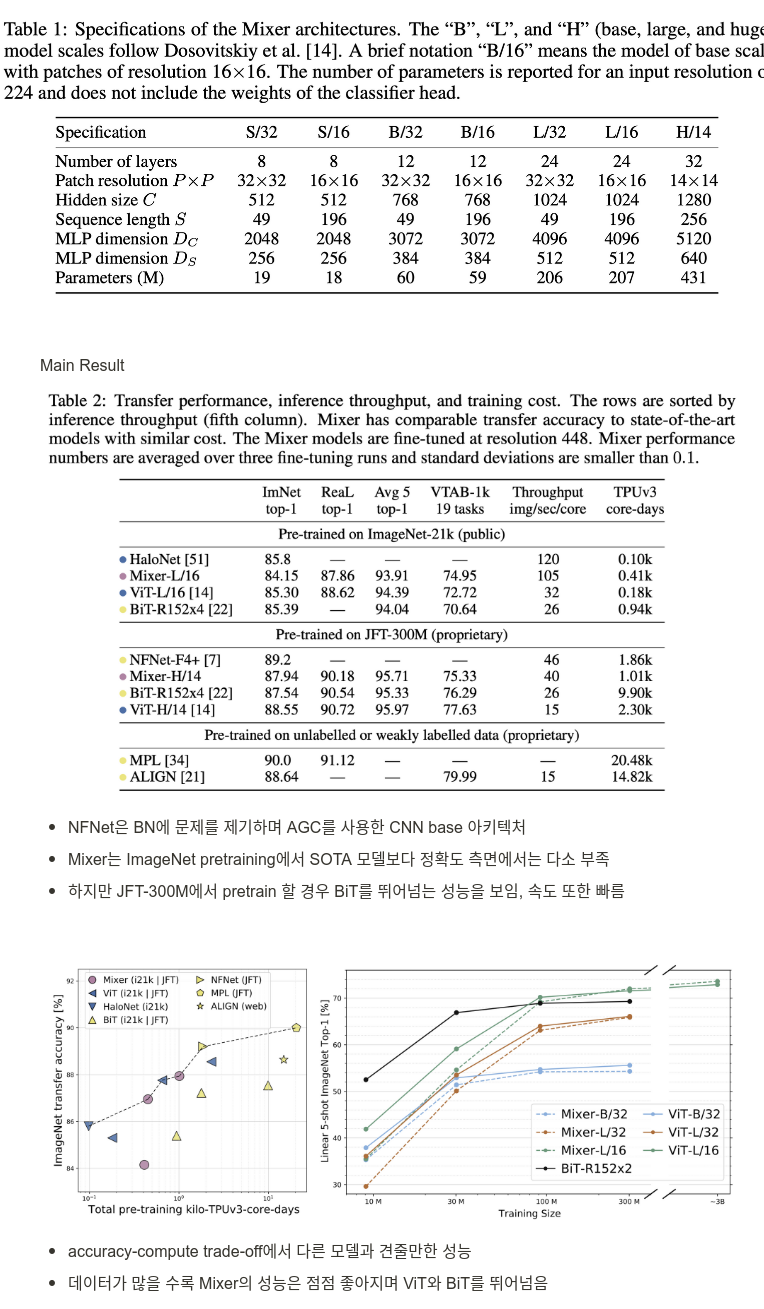
medium ~ large dataset에서 pre-trained하고 small ~ mid-size downstream classification task 성능을 측정
아래 3개에 주목
- downstream task에서 정확도
- pre-training computational cost
- test-time throughput
ViT 논문에서의 명명법에 따라 아키텍처의 이름을 정함
Conclusions
- accuracy-computational cost trade-off에서 SOTA와 비슷한 성능을 가진 vision task를 위한 모델 MLP-Mixer를 제시
- Mixer가 학습한 feature와 CNN, Transformer의 learned features의 주요한 차이점을 비교하고 연구하는 것을 제시
- 다른 도메인에서 적용, convolution or self-attention base를 넘어선 다음 step에 대한 연구를 후속 연구로 제시
후기
- self-attention, convolution을 사용하지 않고 MLPs만 사용한 MLP-Mixer를 제시
- token-mixing, channel-mixing MLP를 사용하여 input table의 spatial, channel 정보의 상호작용을 가능하게 함
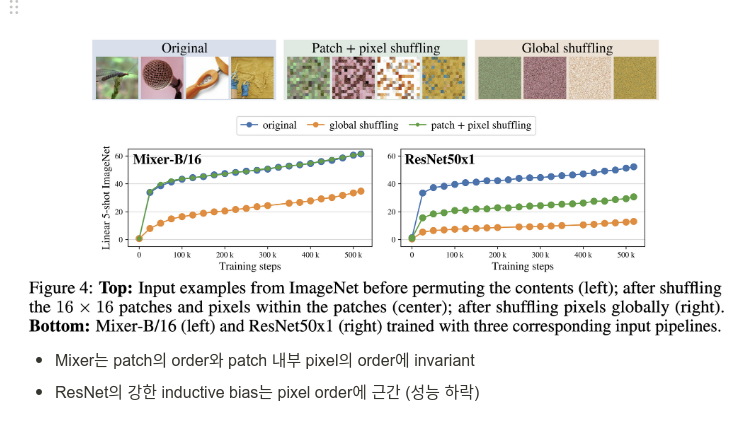
- patch 간 관계를 파악하는 Transformer기반 Self-attention 연산자체도 많은 데이터가 있다면 overkill
- accuracy-computational cost trade-off에서 SOTA에 견줄만한 결과
- 데이터가 많아짐에 따라 점점 inductive bias, hand-crafted feature를 사용하지 않고 raw data 자체에서 좋은 feature를 뽑아내는 방향으로 발전 중
- parameter sharing을 하지않아도 성능이 크게 향상되지 않는 이유가 의문
Reference
[0] IIya Tolstikhin et al. (2021). "MLP-Mixer: An all-MLP Architecture for Vision". https://arxiv.org/abs/2105.01601. CVPR
'AI > Deep Learning' 카테고리의 다른 글
| StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2022.01.31 |
|---|---|
| ConvNeXt: A ConvNet for the 2020s (0) | 2022.01.30 |
| Variational autoencoder (0) | 2022.01.26 |
| Few-shot Font Style Transfer between Different Languages (0) | 2022.01.07 |
| DeiT: Training data-efficient image transformers & distillation through attention (0) | 2022.01.05 |
'AI/Deep Learning' Related Articles
more


