
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 언리얼엔진
- cv
- Few-shot generation
- deep learning
- Stat110
- animation retargeting
- 딥러닝
- userwidget
- NLP
- WinAPI
- Font Generation
- 오블완
- multimodal
- WBP
- CNN
- Unreal Engine
- ue5.4
- RNN
- GAN
- ddpm
- dl
- 디퓨전모델
- 폰트생성
- 모션매칭
- 생성모델
- Generative Model
- BERT
- Diffusion
- motion matching
- UE5
Archives
- Today
- Total
Deeper Learning
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks 본문
AI/Deep Learning
StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks
Dlaiml 2022. 1. 31. 20:32Tero Karras, Samuli Laine, Timo Aila. NVIDIA. (2019.03)
Abstract
- style transfer 논문의 아이디어를 차용한 아키텍처를 제시
- 새 아키텍처는 비지도 학습으로 자동으로 학습되며, high-level attributes(pose, identity)와 생성 이미지의 stochastic variation(주근깨, 머리카락)을 separation, 직관적인 scale에 따른 생성 이미지 조정 또한 가능
- 기존 distribution quality metrics에서 SOTA를 달성, 입증 가능한 더 나은 interpolation 성능, variation의 latent factor를 더 잘 disentangle
- interpolation 퀄리티와 disentanglement를 측정하는 모든 generator 아키텍처에 적용 가능한 자동화 method 2개를 제시
- 다양하고 고품질의 사람 얼굴 데이터셋을 소개
1. Introduction
- GAN의 성능은 점점 발전하고 있지만 black box인 generator의 이미지 생성 프로세스에 대한 이해는 여전히 부족한 영역
- latent space의 특성에 대한 이해도 부족하며 일반적으로 사용하는 latent space interpolation은 generator를 정량적으로 비교할 수 없음
- AdaIN에서 영감을 받아 image 생성 프로세스를 조정할 수 있는 새로운 방식으로 generator 아키텍처를 re-design
- StyleGAN의 Generator는 학습된 constant input에서 시작하여 image의 style을 각 convolution layer의 latent code에 기반하여 적용하기 때문에 다양한 scale에서 features의 강도를 조절
- input latent space는 training data의 확률분포를 따라야 했으며 이로 인해 피할 수 없는 entanglement이 발생
- StyleGAN의 intermediate latent space는 이러한 제약에서 자유로워 disentanglement
- 이전에 사용하던 latent space disentanglement 측정 method는 StlyeGAN에 사용이 불가능하여 새로운 2개의 metrics을 제시
- perceptual path length
- linear separability
- 제시한 metrics을 통해 이전 generator 아키텍처보다 StyleGAN의 generator가 더 linear하며 덜 entangle된 representation을 가지고 있음을 측정
- Flickr-Faces-HQ(FFHQ)을 공개
2. Style-based generator

- 보통 latent code는 input layer를 통해 generator로 feed
- input layer를 제거하여 learned constant가 generator의 input
- latent code 는 non-linear mapping network를 통해 w로 매핑됨
- 간단함을 위해 z와 w의 dimension을 512로 설정, mapping network 는 8개의 FC layer로 구성되어있음
- 학습된 affine transformation에 의해 는 style인 가 되어 synthesis network 의 convolution layer 이후 AdaIN에 사용 ( 의 dimension은 feature map의 2배가 되어야 함)
- AdaIN의 efficiency와 compact representation은 StyleGAN의 목적에 적합하였음
- explicit noise inputs을 사용하여 generator에게 stochastic detail을 생성할 수 있도록 해줌
- single-channel uncorrelated Gaussian noise는 위 구조도에 “B”로 표시된 학습된 per-feature scaling factors를 통해 broadcasting 되고 해당 convolution output에 더해줌
- Synthesis network 는 18개의 layer로 구성되어 있으며 4x4 resolution input를 받아 1024x1024의 output을 생성
2.1. Quality of generated images

- 전체적으로 퀄리티가 좋으며 안경, 모자와 같은 액세서리 또한 성공적으로 생성
- extreme regions에서의 샘플링을 방지하기 위해 에 truncation trick을 사용
2.2. Prior art
- 대부분 GAN 아키텍처에 대한 연구는 discriminator를 개선하는 방향으로 이루어졌음 (multiresolution, self-attention)
- Generator에 대한 연구는 input latent space의 exact distribution에 집중 (Gaussian mixture models, clustering, convexity)
- 최근 conditional generator는 분리된 embedding network를 사용하여 generator의 많은 layer에 class 정보를 전달
- 몇몇 연구는 latent code를 generator의 다수의 layers에 제공하였으며 AdaIN을 활용하여 generator를 self modulate 하는 시도도 있었으나 intermediate latent space와 noise inputs이 StyleGAN의 차이점
3. Properties of the style-based generator
- style을 scale-specific하게 수정할 수 있는 구조
- mapping network와 affine transformation은 학습된 분포에서 style을 각각 가져오는 역할
- synthesis network은 style들을 사용하여 image를 생성하는 역할
- style은 network에서 localized 되었기 때문에 style의 특정 subset을 바꾸는 것은 image의 특정 특징에만 영향을 줌
- AdaIN은 대상 벡터의 channel을 zero mean, unit variance로 normalize하고 scales과 bias는 style에서 가져오기 때문에 style에 의해 바뀐 per-channel 통계량은 다음 conv 연산 전 input의 특징의 상대적 중요도를 바꾸지만 normalization을 하였기 때문에 이전의 original 통계량에 독립적
- AdaIN을 통한 통계량 변화로 어떤 특성이 변하게 되는데 AdaIN을 통과하기 전 input은 AdaIN 연산을 하기 위해 normalize 되었기 때문에 에서 나온 여러 style은 다음 AdaIN에 의해 통계량이 변하기 전 오직 하나의 convolution만 control
- Thus each style controls only one convolution before being overridden by the next AdaIN operation.
3.1. Style mixing
- style을 더 localize시키기 위해 mixing regularization을 사용
- 일정 비율의 이미지는 input image에서 나오는 one latent code가 아닌 2개의 random latent codes를 사용하여 이미지를 생성
- 하나의 latent code를 사용하다가 다른 latent code로 변경하는 style mixing을 사용
- 를 mapping network를 통과시켜 를 얻고 초기 layer에서는 를 사용하고 후기 layer에서는 를 사용하는 방식으로 mixing
- style mixing을 통해 인접한 style이 correlate 되는 것을 방지할 수 있음
- 여러 latent를 test time에 섞으면 FID가 향상

- coarse style은 4x4, 8x8 resolution에서 style, middle style은 16x16, 32x32 resolution, fine style은 64x64 ~ 1024x1024 resolution에서 style
- style의 subsets이 의미있는 특성을 바꾸는 것을 확인할 수 있음
3.2. Stochastic variation
- 사람의 얼굴에서는 stochastic으로 여길 수 있는 hair, stubble, freckles, skin pores의 정확한 위치 등이 있으며 이들은 알맞은 분포 내에서 랜덤 하게 바뀌어도 우리의 인식에 큰 영향을 미치지 않는다
- 기존 generator에서는 stochastic variation을 다루기 위해서는 네트워크의 입력은 input layer를 통과할 수 밖에 없기 때문에 이전 activation에서 spatially-varying 유사 난수를 생성하는 방식이 필요하였음
- 위 방식은 capacity를 소모하며 주기성을 숨기지 못하여 생성 결과에서 반복적인 패턴이 나타나는 문제가 있음
- StyleGAN은 convolution layer 이후 per-pixel noise를 사용하여 이를 해결

- noise가 다르면 (c)에서 볼 수 있듯이 표준편차가 큰 hair, background 등이 바뀌지만 같은 사람으로 인식하게 하는 눈, 코, 입은 변하지 않는 것을 볼 수 있음

- (a): 모든 layer에 noise, (b): No noise, (c): fine layers noise (64x64 ~ 1024x1024), (d): coarse layers noise (4x4 ~ 32x32)
- noise가 없는 경우 세부 특징이 살아있지 않는 그림같은 결과물이 나오며 Coarse noise는 larger back ground, large-scale curling hair에 영향, fine noise는 finer curls of hair, 배경의 디테일에 영향
- 각 layer에서 다른 noise를 사용할 수 있기 때문에 이전 layer의 stochastic 통계량을 사용하지 않아 localized effect
3.3. Separation of global effects from stochasticity
- Style이 생성 이미지의 정체성과 포즈를 바꾸며 noise는 머리카락의 위치나 수염과 같은 것에 영향을 미침
- 이는 style transfer 논문의 설명과 일치하는데 spatially invariant 통계량인 Gram matrix, channel-wise mean, variance 등은 image의 style을 담당하며 spatially varying features는 content를 담당
- style-based generator에서는 style은 전체 feature map이 같은 값에 의해 scaled, biased 되기 때문에 pose, 빛, 배경 style과 같은 global effect를 변경
- noise는 각 pixel에 독립적이라 stochastic variation을 control 하기 적합, 만약 noise로 인해 pose가 바뀔 경우 spatially inconsistent decision으로 discriminator에 의해 penalize
- 따라서 네트워크는 global, local channel을 명시적인 guidance없이도 적절하게 사용
4. Disentanglement studies
- disentanglement에 대한 많은 정의가 있지만 공통적인 목표는 하나의 특성을 조절하는 linear subspace들을 포함하여 latent space를 얻는 것
- 하지만 training data에서 얻은 의 여러 factor에 대한 샘플링 분포는 training data의 density를 따를 수밖에 없음
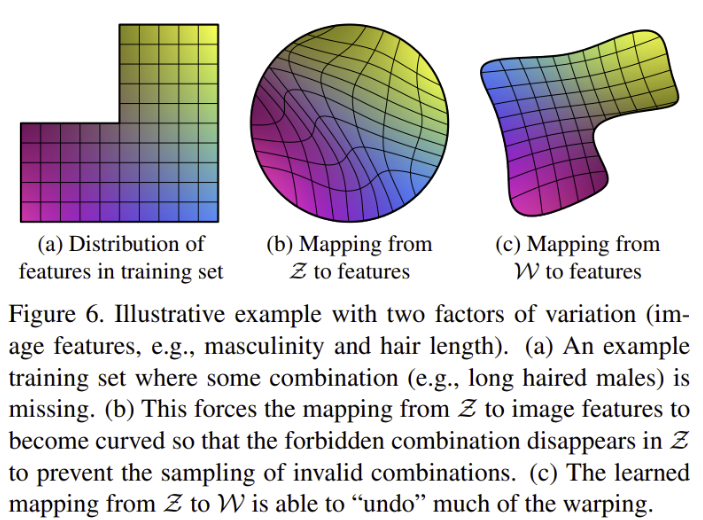
- (a)의 가로축이 여성-남성, 세로축이 수염의 유무라고 하면 좌측 상단인 수염이 있는 여성의 공간은 training set에서 비어있음
- (b)는 (a)에서 얻은 의 분포를 시각화한 것으로 불가능한 조합(수염-여자)이 에서 샘플링 될 수 없다
- StyleGAN은 를 다시 로 매핑하여 (a) → (b)의 warping을 어느정도 다시 돌이키는 효과를 가짐
- 이처럼 StlyeGAN의 generator 아키텍처의 장점은 intermediate latent space 에서의 샘플링이 특정 fixed distribution을 따를 필요가 없다는 것, 의 sampling density는 mapping network 에 의해 유도됨
- mapping network 에 의한 매핑은 를 unwarp 시켜 factor를 linear하게 해 줌
- generator가 실제 같은 이미지를 생성하기 위해서는 entangled feature보다 disentangle feature이 적합하기 때문에 generator에게 그러한 압력이 있었을 것이라는 가정
4.1. Perceptual path length
- latent space vectors의 interpolation은 image에 non-linear 변화를 일으킨다
- 예시로 양쪽 endpoint에 없는 features가 linear interpolation 중간에 나타날 수 있음
- 이는 latent space가 entangled 상태이며 variation의 factor가 나누어지지 않았다는 것을 뜻함
- latent space의 변화에 따라 image가 변하는 정도를 측정하는 metric을 제시
- less curved latent space는 highly curved latent space보다 이미지가 사람이 보았을 때 부드럽게 변해야 함
- VGG16 feature map의 차이로 perceptually-based pairwise image distance를 측정하는 방식을 제시
- latent space의 interpolation path를 linear segments로 나누고 이들의 perceptual differences를 더하면 total perceptual length를 구할 수 있음
- perceptual path length를 정확히 구하려면 무한히 작은 부분으로 interpolation path를 나누어야 하지만 구현상 나눈 한 segment의 길이를 로 설정
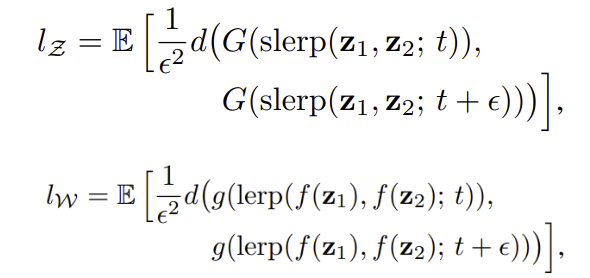
- 는 generator, 는 생성이미지 간 perceptual distance 함수, 은 spherical interpolation (unit sphere 공간에서 보간)
- 는 와 다르게 normalized되지 않은 값이라 이 아닌 를 사용
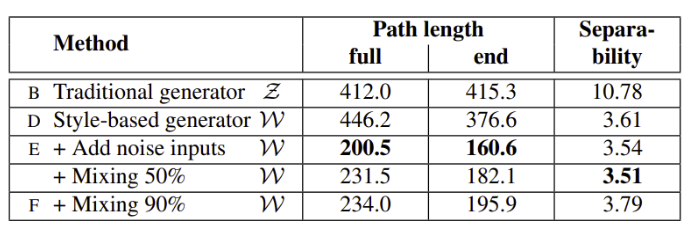
- noise input이 추가된 는 보다 perceptually linear
- 만약 가 실제로 disentangled 되어 있고 의 flattened 매핑이라면 input manifold에 없는 regions도 포함하고 있어야 함
- 그렇다면 path endpoint에서 perceptual path length를 측정하면 는 더 작아져야 하며 는 영향을 받지 않아야 함, 로 실험하였더니 예측과 같은 결과
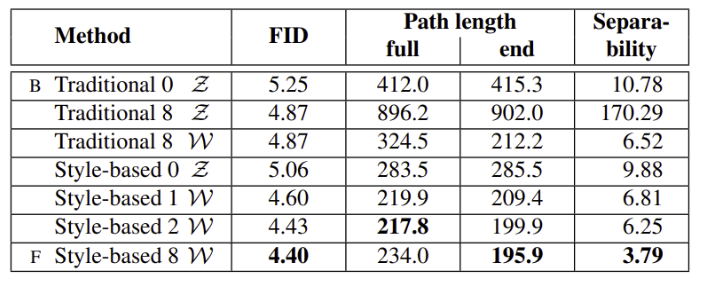
- mapping network의 효과를 traditional generator와 style-based generator에서 확인할 수 있으며 additional depth 또한 생성 퀄리티를 향상시켰음
- 동일하게 8개의 layer를 사용한 Traditional generator에서 와 를 사용함에 따라 결과에 차이가 발생하였는데 이는 저자의 주장인 input latent space가 기존 GAN에서 entangled 되어 있음을 뒷받침한다
4.2. Linear separability
- latent space가 충분히 disentangled 되어 있다면 variation의 한 factor에 일관적으로 해당하는 direction vectors를 찾을 수 있다
- latent-space points가 linear hyperplane에서 이미지의 특정 속성을 담당하는 2개의 구분 가능한 axis로 분리할 수 있는지 정량화하는 metric을 제시
- 생성된 이미지를 labeling 하기 위해 male-female과 같은 binary features를 분류하는 보조 classifier를 만듦
- 에서 총 200,000개의 image를 만들고 보조 classifier의 confidence를 사용하여 confidence가 낮은 이미지를 제외한 100,000개의 labeled image와 해당 latent code를 준비
- latent space point 또는 의 label을 SVM을 사용하여 예측하도록 학습
- 는 SVM이 latent space point로 예측한 class, 는 pre-trained auxiliary classifier가 예측한 True class 일 때 는 true class를 예측하기 위해 추가 정보가 얼마나 필요한지를 뜻한다
- 가 작다면 이는 latent space의 direction이 variation의 해당 factor(feature)에 일관적이라는 것을 말함
- latent space에서 해당 feature에 대한 direction vector가 잘 형성되어 있다는 것으로 disentangle, separate 되어 있다는 것을 말함
- 최종 separability score는 식으로 계산되며 는 40개의 attributes, 지수를 사용하여 비교하기 쉽도록 함
- 위 2개의 table에서 확인할 수 있듯이 는 일관적으로 보다 더 separable하며 덜 entangled된 representation을 가짐
- mapping network의 depth를 증가시키는 것은 image quality와 separability를 에서 모두 증가 시킴, synthesis network은 disentangled input representation을 내재적으로 선호한다는 가설을 뒷받침
- mapping network의 추가는 에서 separability를 잃게 만들었지만 에서는 separability, FID를 향상시킴
- traditional generator 아키텍처도 intermediate latent space를 사용할 경우 training data의 distribution을 따르지 않을 수 있기 때문에 더 좋은 성능을 보임
5. Conclusion
- style-based generator는 traditional GAN generator보다 뛰어남
- intermediate latent spaced의 선형성처럼 high-level attributes와 stochastic effects의 separability에 대한 우리의 연구가 GAN의 이해와 조정 가능성을 개선
- average path length는 metric이자 regularizer로 활용할 수 있다
- 학습 도중 intermediate latent space를 직접적으로 형성하는 것을 future work으로 제시
6. Acknowledgements
B. Truncation trick in
- variation의 특정 부분만 사용하지만 더 좋은 평균 이미지 퀄리티를 보이는 truncated에서 latent vectors를 뽑는 방식을 사용

후기 & 정리
- 기존 generator의 가 training 분포를 따르기 때문에 생기는 entanglement 문제를 해결하기 위해 style transfer에서 영감을 얻은 StyleGAN을 제시
- disentanglement, separability를 측정할 수 있는 유용한 metrics을 제시: Perceptual path length, linear separability metric을 제시
- AdaIN의 통계량 변화를 활용하여 noise, style이 localized 되어 해당 scale에서 독립적으로 작동하도록 한 구조
- 오랜만에 생성 모델 논문을 읽었는데 도입한 idea에 따른 생성 결과의 변화가 흥미로웠음
- 생소한 어휘가 있었고 한국어로 적절한 번역이 어려워 읽고 정리하는데 시간이 오래 걸렸음
- 자주 사용되는 데이터셋인 FFHQ를 제시한 논문이 StyleGAN
Reference
[0] Tero Karras, Samuli Laine, Timo Alia. (2019). "A Style-Based Generator Architecture for Generative Adversarial Networks". https://arxiv.org/abs/1812.04948.NE
'AI > Deep Learning' 카테고리의 다른 글
| CGAN: Conditional Generative Adversarial Nets (0) | 2022.02.09 |
|---|---|
| StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN (0) | 2022.02.07 |
| ConvNeXt: A ConvNet for the 2020s (0) | 2022.01.30 |
| MLP-Mixer: An all-MLP Architecture for Vision (0) | 2022.01.28 |
| Variational autoencoder (0) | 2022.01.26 |
'AI/Deep Learning' Related Articles
more




Comments