
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- animation retargeting
- BERT
- NLP
- GAN
- Generative Model
- WinAPI
- deep learning
- Unreal Engine
- 딥러닝
- ddpm
- CNN
- 생성모델
- UE5
- motion matching
- cv
- 언리얼엔진
- userwidget
- ue5.4
- 모션매칭
- Stat110
- Diffusion
- dl
- 디퓨전모델
- WBP
- 폰트생성
- multimodal
- Few-shot generation
- RNN
- 오블완
- Font Generation
- Today
- Total
Deeper Learning
ConvNeXt: A ConvNet for the 2020s 본문
[convnext] Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell, Saining Xie, Facebook AI Research (FAIR), UC Berkeley (2022.01.02)
Abstract
- 2020년도에 ViT는 이미지 분류 SOTA 모델로 CNN을 대체
- 하지만 vanilla ViT는 object detection 또는 semantic segmentation과 같은 general computer vision task에 적용하는데 어려움을 겪음
- Swin Transformer와 같은 계층적 Transformer는 여러 vision task에서 좋은 성능을 냄
- 하지만 이러한 hybrid 접근의 유효성은 convolution의 inductive bias를 주입하였기 때문이라기보다 Transformer의 내재적 강점에 의한 것
- pure ConvNet의 한계를 연구
- ResNet을 점진적으로 modernize하며 어느 key components가 성능을 향상시키는지 연구하여 pure ConvNet family인 ConvNeXt를 정의
- 기존 ConvNet 모듈로 이루어진 ConvNeXt는 accuracy와 scalability 측면에서 Transformer에 견줄 수 있으며 ImageNet top-1 accuracy 87.8%를 달성하였으며 COCO detection과 ADE20K segmentation에서 Transformer를 넘어섰다
1. Introduction
- 2010년 부터 CNN은 신경망 르네상스를 이끌었으며 visual recognition은 feature engineering에서 model architecture design으로 옮겨갔다
- CNN의 학습은 1980년도에도 가능하였지만 2012년에서야 CNN의 feature learning의 가능성을 알게 됨
- VGGNet, Inceptions, ResNe(X)t, DenseNet, MobileNet, EfficientNet, RegNet은 accuracy, efficiency, scalability를 여러 측면에서 접근하였으며 모두 유명하고 유용한 디자인
- ConvNet의 가장 중요한 inductive bias는 translation equivariance, sliding-window를 사용하여 computations 또한 공유
- 수십 년 동안 CNN은 visual recognition system의 fundamental building block
- 같은 시간대에 NLP에서는 Transformer가 RNN을 대체하는 backbone 아키텍처가 되며 CNN과 다른 서사가 쓰이고 있었다
- 2020년에 visual, language 도메인의 모델은 ViT로 통합되는데 ViT는 image를 sequence of patches로 전환하는 첫 layer를 제외하고 CNN의 inductive bias를 사용하지 않고 pure Transformer 구조를 최대한 유지하며 CNN의 성능을 넘어섰다
- 하지만 ViT는 global attention을 적용하다 보니 input size에 대해 quadratic 하게 계산복잡도가 증가하며 ImageNet classification은 가능하나 higher resolution input을 다루기 힘든 문제가 있었음
- Hierarchical Transformer는 이 차이를 줄이기 위한 hybrid approach
- local window 내에서만 attention을 수행하는 sliding window 전략
- Swin Transformer는 처음으로 Transformer가 generic vision backbone으로 적용되며 SOTA를 달성한 모델
- Swin Transformer의 성공에서 convolution의 본질이 중요하다는 것을 알 수 있음
- ConvNet의 성능이 비교적 부족해 보이는 이유는 Transformer의 뛰어난 scalability 때문이다
- ConvNet과 hierarchical vision Transformer는 비슷한 inductive bias를 가지고 있으나 학습 과정과 architecture design에서 크고 작은 차이가 있음
- pre-Vit 시대의 ConvNet과 post-ViT 시대의 ConvNet의 간극을 메우고 pure ConvNet의 한계를 테스트하는 것이 연구의 주제
- “How do design decisions in Transformers impact ConvNet’s performance?”라는 key question의 답을 찾기 위해 ResNet에서 시작하여 점점 아키텍처를 modernize시키며 성능을 관찰
- 성능에 관여하는 key components를 찾아냈으며 ConvNeXt는 accuracy, scalability, robustness 측면에서 주요 벤치마크 성능이 Transformer보다 뛰어났음
- computer vision에서 convolution의 중요성에 대해 사람들이 를보기를 바람
2. Modernizing a ConvNet: a Roadmap
ResNet에서 Transformers와 거의 비슷한 ConvNet으로 가는 과정을 설명하는 section
ResNet과 Transformer의 비교는 FLOPs가 비슷한 ResNet-50/Swin-T, ResNet-200/Swin-B 끼리 비교
ResNet-50/Swin-T의 결과를 앞으로 설명, 더 큰 모델의 결과는 Appendix에 작성

Design decisions을 marco design, ResNeXt, Inverted Bottleneck, Large Kernel, Micro Design으로 나누어 여러 skill을 적용하며 비교
Training Techniques
- 네트워크 디자인과 별개로 학습과정 자체도 성능에 영향을 미친다
- vision Transformer는 새로운 아키텍처뿐만 아니라 새로운 training techniques(ex.AdamW optimizer)도 함께 사용
- modernizing의 첫 step은 학습 과정의 mordernize, ResNet-50에 최신 학습 skill을 적용하면 크게 성능을 향상시킬 수 있다는 이전 연구 또한 존재
- DeiT, Swin Transformer와 비슷한 학습 skill을 적용
- 90 epochs → 300 epochs
- AdamW optimizer
- Augmentation: Mixup, Cupmix, RandAugment, Random Erasing
- Regularization: Stochastic Depth, Label Smoothing
- ImageNet Top-1 accuracy가 76.1%에서 78.8%로 상승하였으며 이는 ConvNet과 Transformer의 차이의 큰 부분을 training techniques가 차지하고 있었다는 것을 말함
Macro Design
Swin Transformer는 각 stage가 다른 feature map resolution을 가지는 ConvNet의 multi-stage design을 따름
stage compute ratio, “stem cell” structure가 흥미로운 부분
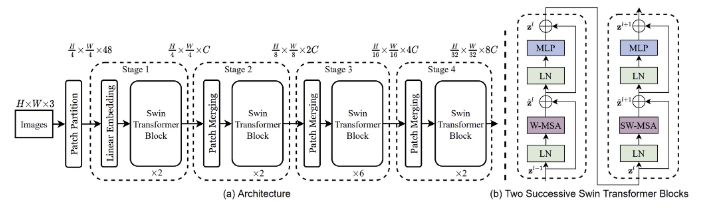
Changing stage compute ratio
- 위 Swin Transformer의 구조를 보면 stage의 계산량 비율이 1:1:3:1 인 것을 볼 수 있다. 더 큰 Swin Transformer는 1:1:9:1의 비율을 채택
- 이를 따라 ResNet-50의 stage의 block의 수를 3:4:6:3에서 3:3:9:3으로 변경
- accuracy가 78.8%에서 79.4%로 크게 상승하였음
Changing stem to “Patchify”
- Stem은 초기 layer를 뜻하며 natural image의 불필요한 pixel의 중복성 때문에 주로 공격적인 downsampling을 사용하여 feature map size를 적절하게 조절(Transformer, ResNet 모두)
- ResNet의 stem cell은 7x7 kernel, stride 2 convolution layer와 max pool을 사용하여 4배의 downsampling을 적용
- vision Transformer에는 더 공격적인 “patchify” strategy가 stem cell에 사용됨 (14 or 16 kernel size, non-overlapping convolution)
- Swin Transformer는 비슷한 patchify layer를 사용하지만 patch size를 4로 고정하여 multi-stage design을 견딜 수 있도록 함
- ResNet의 stem cell을 patchify style인 4x4, stride 4 convolution layer로 대체하여 79.4%에서 79.5%로 성능을 향상시킴 (4x4 non-overlapping convolution)
ResNeXt-ify
- Vanilla ResNet보다 FLOPs/accuracy trade-off가 나은 ResNeXt의 아이디어를 적용
- 주요 구성요소는 grouped convolution
- ResNeXt는 bottleneck block에서 3x3 grouped convolution을 사용하고 줄어든 capacity를 보완하기 위해 width를 늘리는 것을 추천
- ConvNeXt는 group size가 1인 grouped convolution인 Depthwise convolution을 사용
- spatial dimension의 정보만 mixing 하는 구조
- depthwise convolution으로 줄어든 FLOPs, accuracy를 채우기 위해 ResNeXt의 추천대로 width를 64에서 96으로 증가시켜 80.5%의 accuracy를 달성, FLOPs 또한 다소 증가
Inverted Bottleneck
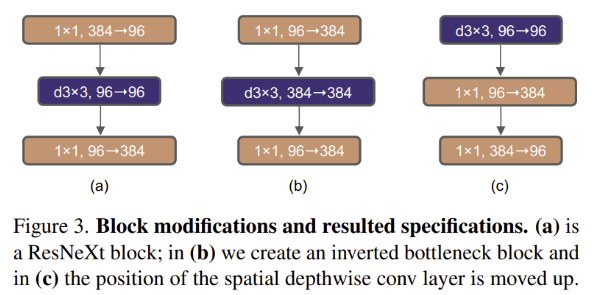
- Transformer block의 중요한 디자인 중 하나는 inverted bottleneck
- MLP block의 hidden dimension은 input dimension보다 4배가 큼
- 이를 CNN에 적용하면 MobileNetV2의 아이디어와 같음
- depthwise convolution의 FLOPs는 증가하였지만 downsampling residual block의 shortcut에 1x1 convolution을 사용하여 전체 FLOPs는 감소
- FLOPs는 감소하면서 80.5%에서 80.6%로 성능 향상(ResNet-200에서는 81.9%에서 82.6%로 성능 향상)
Large Kernel Sizes
- ViT의 non-local self-attention은 각 layer가 global receptive field를 가지도록 해줌
- 과거 ConvNet에서 large kernel이 사용되었지만 효율적으로 GPU를 사용할 수 있는 small kernel을 stack 하는 VGGNet의 방식이 정석이 되었음
- Swin Transformer는 최소 7x7의 window size를 사용하는데 이는 ResNeXt의 3x3 kernel 보다 크다
- large kernel-sized convolutions을 revisit
Moving up depthwise conv layer
- 위 Inverted Bottleneck의 그림에 (c)처럼 depthwise conv layer의 순서를 앞으로 당김
- Transformer는 MSA block이 MLP layer보다 앞서 등장하는데 여기서 착안한 방식
- FLOPs를 줄였으나 성능 또한 79.9%로 하락
Increasing the kernel size
- 3, 5, 7, 9, 11 kernel size로 실험
- FLOPs를 거의 유지한 채로 7x7 kernel을 사용하여 79.9%에서 80.6%로 성능 향상
- 7x7보다 larger kernel의 경우 성능 향상이 거의 없었음
- 7x7 kernel을 사용하기로 결정
여기까지 Macro scale의 아키텍처 개선을 완료
Transformer의 아키텍처 설계의 아이디어를 ConvNet에 적용
Micro Design
Replacing ReLU with GELU
- ReLU가 효율성과 간단함 때문에 널리 사용되었음 (Transformer를 제시한 첫 논문에서도 ReLU사용)
- Gaussian Error Linear Unit는 advanced Transformer인 BERT, GPT-2, ViT에서 사용
- 성능 향상은 없었으나 GELU로 ReLU로 대체할 수 있음
Fewer activation functions
- Transformer는 ResNet block보다 적은 activation functions로 이루어져 있음
- k,q,v linear embedding layer, projection layer, 2 linear layer로 구성된 MLP blcok은 1개의 activation function을 포함하고 있음
- ConvNet에서는 1x1 conv를 포함하여 모든 convolution layer 뒤에 activation function을 보통 사용
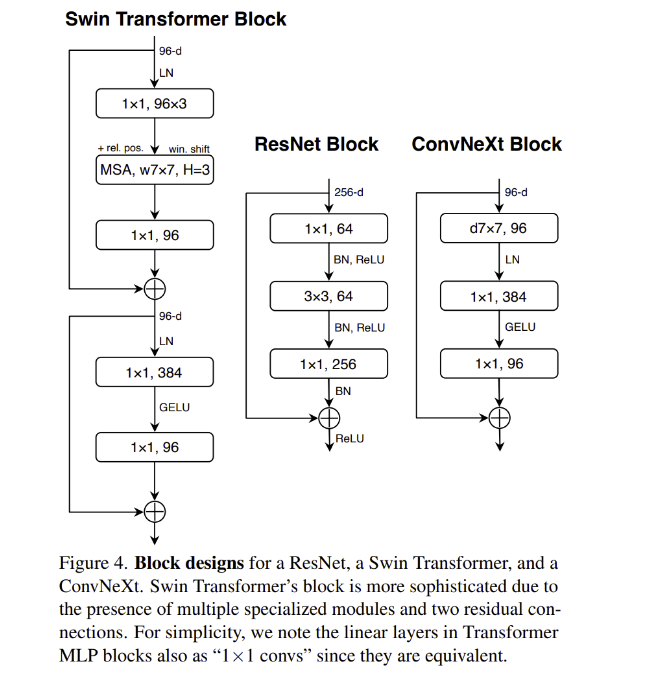
- 위 그림처럼 1x1 conv 사이를 제외하고 GELU layers를 삭제하자 0.7%의 성능 향상이 있었음
Fewer normalization layers
- Transformer Block은 normalization layers가 더 적음
- 1x1 convolution 연산 전 BN을 제외하고 BN을 제거 (Figure 4의 ConvNeXt Block)
- 81.4%의 성능을 달성하며 Swin Transformer의 성능을 넘어섬
- Transformer block 보다 적은 normalization, BN을 Block 시작 지점에 추가해보았으나 성능 향상은 없었음
Substituting BN with LN
- BN은 ConvNet의 수렴과 오버피팅 방지에 효과적이나 모델의 성능에 악영향을 줄 수 있는 복잡성을 가지고 있음 (Yuxin Wu and Justin Johnson. Rethinking "batch" in batchnorm. arXiv:2105.07576, 2021)
- 다른 normalization에 대한 연구가 다수 있었으나 BN이 대부분의 vision task에 널리 사용됨
- 이전 연구에서 original ResNet에서 단순하게 BN을 LN으로 대체하는 것은 성능 하락이 있었음
- ConvNeXt의 ConvNet에서는 BN을 LN으로 대체하였으나 학습에 어려움이 없었으며 81.5%의 정확도로 약간의 성능 향상이 있었음
Separate downsampling layers
- ResNet에서 spatial downsampling은 stage의 시작점에서 residual block의 3x3 kernel, 2 stride conv layer에 의해 이루어짐
- Swin Transformer는 stage 사이에 separate downsampling layer를 사용
- ConvNeXt도 2x2 kernel, stride 2의 conv layer를 사용하여 downsampling을 시도하였지만 수렴에 실패
- 여러 실험을 통해 spatial resolution이 바뀌는 layer에 normalization layer를 추가하는 것이 학습을 안정화하는데 도움이 된다는 것을 파악함
- downsampling layer 이전, stem 이후, 마지막 global average pooling 이후 LN layer를 추가하여 학습하여 82.0%의 정확도 달성(Swin-T 81.3%)
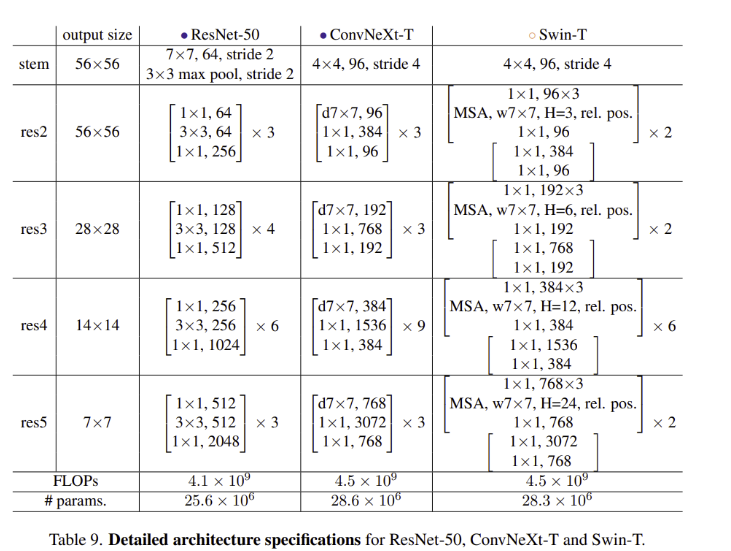
최종 모델은 이렇게 완성되었으며 family를 ConvNeXt로 명명
ConvNeXt는 Swin Trnasformer와 거의 같은 FLOPs, 파라미터 수, throughput, 메모리 사용, but shifted window attention, relative position bias와 같은 특별한 모듈을 사용하지 않고 더 좋은 성능을 보임
vision Transformer는 scaling이 가장 큰 강점이므로 ConvNeXt를 data와 model 측면에서 scale up 하며 비교
3. Empirical Evaluations on ImageNet

- ImageNet-1K top-1 accruacy를 validation set에서 측정
- ImageNet-22K에서 pre-training하고 ImageNet-1K에서 성능 측정
ImageNet-1K
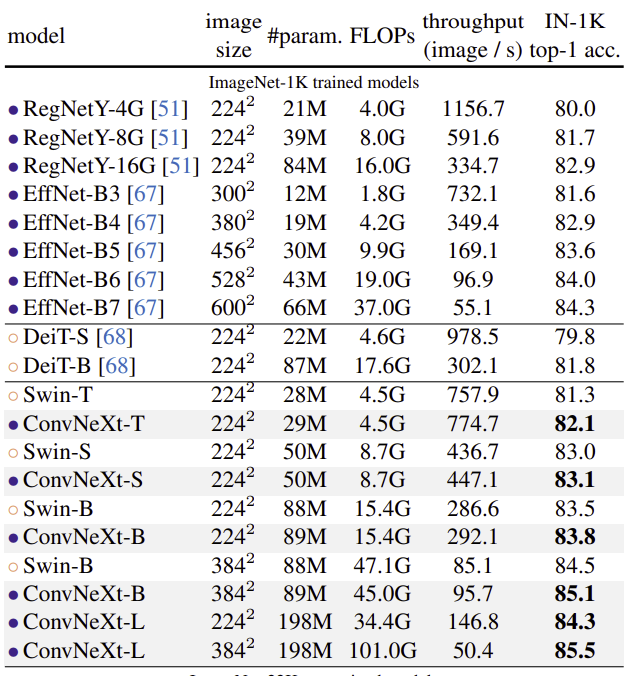
- 정확도-계산량 trade-off에서 SOTA ConvNet인 RegNet과 EfficientNet에 견줄만한 성능
- 여러 model size에서 throughput, 정확도에서 Swin Transformer를 뛰어넘는 성능
- 고해상도 이미지를 사용할 경우 정확도가 더 좋아지는 것을 볼 수 있음
ImageNet-22K
ImageNet-22K에서 pre-train 후 ImageNet-1K top-1 accuracy 측정
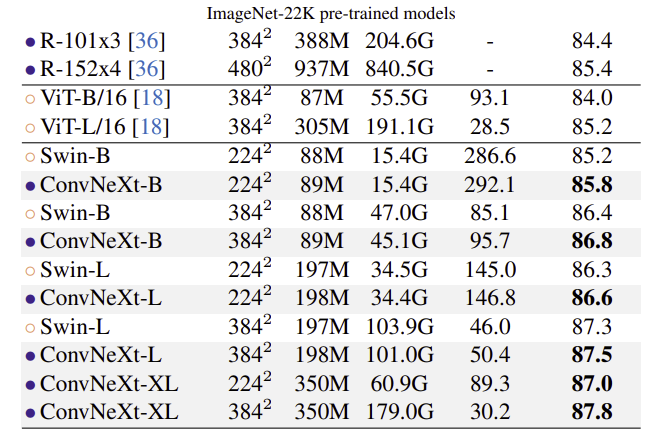
- vision Transformer는 inductive bias가 적어 large scale data를 사용할 경우 성능이 더 좋다는 관점이 많았음
- 실험 결과는 적절하게 디자인된 ConvNet의 경우 larger dataset에서 pretraining 할 때 vision Transformer보다 성능이 나쁘지 않다는 것을 보여줌
- 성능의 포화 또한 관찰되지 않아 ConvNeXt의 scalability 또한 뛰어나다는 것을 보여줌
Isotropic ConvNeXt vs ViT
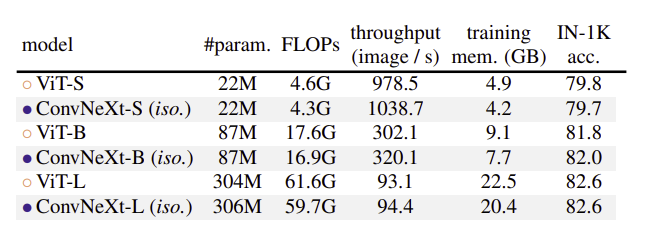
- dowmsampling이 없는 ViT 스타일의 Isotropic 아키텍처로 ConvNeXt를 설계하여도 좋은 성능
4. Empirical Evaluation on Downstream Tasks
Object detection and segmentation on COCO
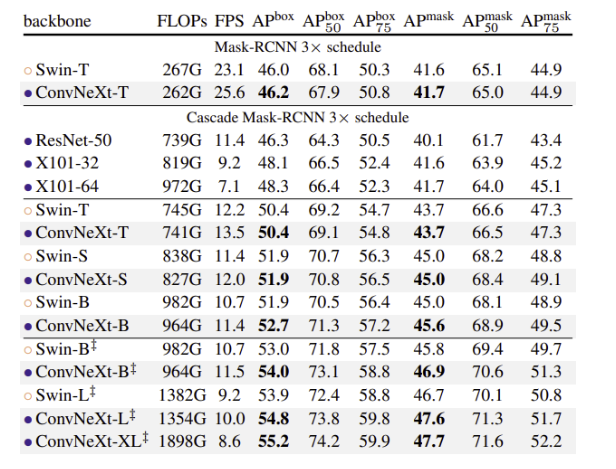
- ConvNeXt 백본으로 COCO dataset을 Mask R-CNN, Cascade Mask R-CNN 파인튜닝
- ‡는 ImageNet-22K pre-trained model
- 모델이 클수록 Swin-Transformer 백본과 box, mask AP차이가 벌어짐
Semantic segmentation on ADE20K
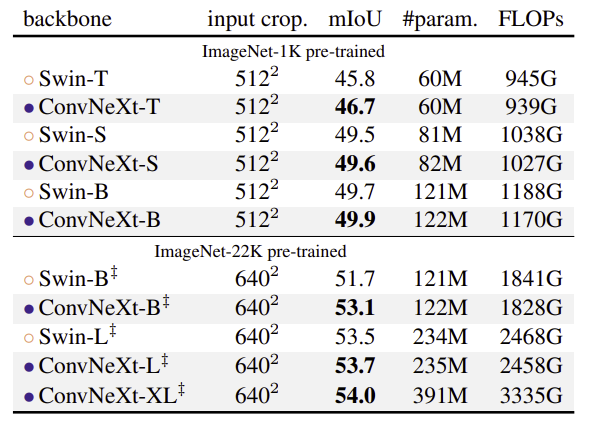
- ConvNeXt와 Swin Transformer를 백본으로 UperNet을 ADE20K에 학습
- ConvNeXt의 성능이 우세
Remarks on model efficiency
- throughput, memory 측면에서 Swin Transformer와 비슷하거나 그 이상
- 중요한 것은 ConvNeXt의 향상된 efficiency가 self-attention 메커니즘과 관련이 없고 ConvNet inductive bias에 의한 것이라는 점
4. Conclusions
- 2020년대에는 계층구조를 가진 ViT인 Swin Transformer가 ConvNet을 추월하며 generic vision backbone이 되기 시작하였음
- vision Transformer가 ConvNet보다 더 정확하고 효율적이고 확장성 또한 좋다는 것은 널리 퍼진 믿음
- 여러 cv 벤치마크에서 Swin Transformer와 경쟁이 가능한 pure ConvNet 모델인 ConvNeXt를 제시
- 놀라운 것은 ConvNeXt는 새로운 것이 아닌 기존에 존재하는 여러 design choices를 적용한 것
- 이 연구결과로 인해 사람들이 널리 알려진 개념에 도전하고 computer vision에서 convolution의 중요성에 대해 재고해보기를 바람
후기
- pure ConvNet으로 Swin Transformer를 여러 task에서 넘어선 ConvNeXt를 제시
- 모델 구조 자체뿐만 아니라 세부적인 model design, 학습 방법 선택도 성능에 큰 영향이 있음
- pure ResNet-50에서 시작하여 Transformer의 아키텍처 디자인 concept을 하나씩 ConvNet에 적용해가며 성능이 향상하는 것을 보는 재미가 있었던 논문
- novelty가 있는 논문이 아닌 아키텍처 디자인 초이스와 training 설정들에 대해 전체적으로 다룬 논문
- ViT에 augmentation을 적용하면 ConvNeXt와 매우 큰 차이가 나지 않는다는 논문의 Figure에 대한 비판이 있음
Lucas Beyer on Twitter
“The ConvNeXt paper is rightfully getting some attention: it's good work and has beautiful plots. But, Fig1 needs a little correction IMO. They compare heavily aug/reg swin+convnext to plain ViT. We fixed this in https://t.co/Y09n8PfgNE which is what sho
twitter.com
Reference
[0] Zhuang Lui et al. (2022). "A ConvNet for the 2020s". https://arxiv.org/abs/2201.03545. CVPR
[1] Ze Liu et al. (2021). "Swin Transformer : Hierarchical Vision Transformer using Shifted Windows”. CVPR
[2] https://www.youtube.com/watch?v=yVKiMh2vEWQ&ab_channel=YannicKilcher
'AI > Deep Learning' 카테고리의 다른 글
| StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN (0) | 2022.02.07 |
|---|---|
| StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2022.01.31 |
| MLP-Mixer: An all-MLP Architecture for Vision (0) | 2022.01.28 |
| Variational autoencoder (0) | 2022.01.26 |
| Few-shot Font Style Transfer between Different Languages (0) | 2022.01.07 |


