
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 오블완
- Diffusion
- motion matching
- Generative Model
- RNN
- Stat110
- 디퓨전모델
- ddpm
- UE5
- GAN
- BERT
- 딥러닝
- 생성모델
- ue5.4
- userwidget
- CNN
- 폰트생성
- animation retargeting
- Unreal Engine
- Font Generation
- 모션매칭
- dl
- deep learning
- cv
- 언리얼엔진
- WinAPI
- NLP
- WBP
- Few-shot generation
- multimodal
Archives
- Today
- Total
Deeper Learning
StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN 본문
AI/Deep Learning
StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN
Dlaiml 2022. 2. 7. 10:30Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila
NVIDIA. (2019.12)
Abstract
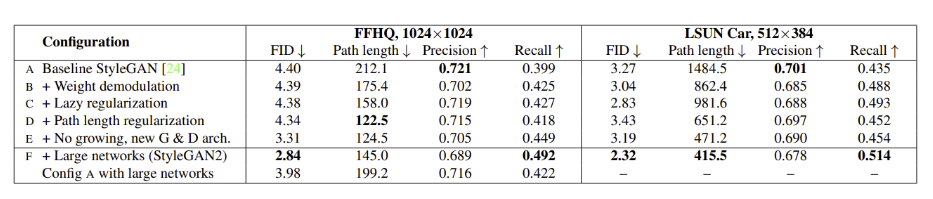
- StyleGAN은 unconditional data-driven 이미지 생성 SOTA 달성 모델
- StyleGAN의 특징적인 아티팩트를 분석하고 이를 해결하기 위한 아키텍처와 학습방법을 제안
- generator의 normalization을 새로 디자인, progressive growing을 재고(resolution을 증가시키며 학습하는 것), generator regularization을 통해 latent code에서 image로의 매핑을 개선
- path length regularizer는 이미지 퀄리티를 개선할 뿐 아니라 generator가 쉽게 invert 되도록 한다
- generator의 output resolution 활용을 시각화하여 capacity 문제가 있다는 것을 확인하고 이를 해결하기 위해 더 큰 모델에서 학습하여 추가적인 퀄리티 개선을 이룸
- 제시한 향상된 모델은 unconditional 이미지 모델링에서 분포 퀄리티 metrics, perceived image quality metrics 에서 SOTA를 달성
1. Introduction
- GAN이 생성한 이미지의 해상도와 퀄리티는 빠르게 좋아지고 있다
- StyleGAN이 다양한 dataset에서 현재 고화질 이미지 생성에서 SOTA
- 저자는 StyleGAN의 특징적인 아티팩트를 개선하여 결과 퀄리티를 향상시키는데 집중하였다
- StyleGAN의 특징은 특별한 generator 아키텍처에 있는데 latent code Z 가 input layer를 바로 통과하지 않고 mapping network를 사용하여 얻은 intermediate latent code W 를 사용
- W 가 Affine transform을 거쳐나온 style은 synthesis network의 layer를 AdaIN을 통해 컨트롤, stochastic variation은 random noise를 사용하여 컨트롤
- 이러한 StyleGAN의 아키텍처 디자인은 latent space을 disentangle
- 이 논문에서는 오직 W에 대해서만 분석
- 방울모양의 아티팩트가 생기는 원인에 대해 분석하여 generator가 구조적 결함을 피하기 위해 아티팩트를 생성한다는 것을 찾고 normalization을 수정하여 아티팩트를 제거
- 아티팩트가 high-resolution GAN의 학습을 안정화시키는 progressive growing과 관련이 있다는 것을 파악
- 학습 도중 네트워크의 topology를 바꾸지 않고 초기 학습에는 low-resolution에 집중, 후기 학습은 high-resolution에 집중하도록 하는 디자인을 제시
- 새 디자인으로 인해 적절한 생성 이미지의 resolution에 대해 추론할 수 있게 되었으며 이는 기존 아키텍처에 capacity가 부족하다는 것을 밝힘
- 생성 모델의 정량적인 퀄리티 측정은 어려움
- Inception V3의 feature map에서 difference를 측정하는 FID
- 생성된 이미지의 training data와 비슷한 비율, training data에서 생성 가능한 이미지의 비율을 측정하는 Precision & Recall(P&R)
- 위 두 metric 모두 classifier network 기반이며 최근(2019) classifier network가 shape가 아닌 texture에 집중한다는 것이 밝혀졌으며 두 metric은 이미지의 퀄리티를 정확하게 측정하지는 못함
- shape의 consistency, stability와 관련있는 latent space의 퀄리티를 추정하는 Perceptual Path Length(PPL)를 사용하여 synthesis network를 regularize하여 생성 이미지의 퀄리티를 향상시킴
- image를 latent space W로 projection하는 것도 StyleGAN보다 path-length regularization이 추가된 StyleGAN2에서 더 잘 작동
2. Removing normalization artifacts

- StyleGAN이 생성한 이미지에서 물방울 모양의 아티팩트가 다수 등장
- 최종 결과에 아티팩트가 없더라도 feature map에서 문제가 생기는 것을 관찰, 주로 64x64 resolution에서 아티팩트가 발생하고 점점 higher resolution에서 아티팩트가 커지는 문제 존재
- DIscriminator가 충분히 아티팩트를 감지할 수 있을 것임에도 불구하고 계속 아티팩트가 생기는 문제
- StyleGAN은 각 feature map의 mean과 variance를 normalize하는 AdaIN을 사용하는데 이는 서로 관련된 feature의 크기에서 얻을 수 있는 정보가 파괴할 가능성이 있다
- 저자는 물방울 아티팩트는 generator가 신호 강도 정보를 IN을 통과하여 전달하기 위하여 통계량을 압도하는 국소적이고 강한 spike를 생성한다는 가설을 세웠으며 이는 normalization step을 제거할 때 아티팩트가 사라지는 것으로 뒷받침됨
2.1. Generator architecture revisited
- 기존 (b)StyleGAN은 Noise를 적용하는 B가 Style Block 내에 위치하여 현재 style의 크기에 그 영향이 반비례하는 문제가 있음 (feature map의 scale이 클 경우 항상 같은 범위 내에 위치하는 Noise를 더하였을 때 Noise의 영향이 더 작음)
- 따라서 (c) 처럼 구조를 변경하였고 그 후 mean에 대한 modulation을 제거하였는데도 성능이 비슷함
- input constant c1 에 bias b1 , Noise, normalization을 적용하는 부분을 제거하여도 성능의 하락이 없었다
2.2. Instance normalization revisited
- StyleGAN의 특징은 style mixing으로 generated image를 control 하는 것
- style modulation은 magnitude에 따라 특정 feature를 증폭시키는데 per-sample basis로 이에 대한 대응을 해주어야 다음 layer가 정상적으로 제 역할을 할 수 있다
- scale-specific control을 포기하면 AdaIN의 normalization을 제거하여 아티팩트를 없앨 수 있으나 controllability를 잃게 됨
- 주어진 feature map의 expected 통계량 기반 normalization으로 아티팩트를 제거하면서 controllability를 유지할 수 있다
- (c)의 modulation 부분을 보면 convolution 전 feature map의 scale을 incoming style에 따라 변경한다
- 위 프로세스는 convolution weight 자체에 대한 scaling으로 대체할 수 있다
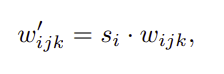
- w′ 는 modulated weights, w 는 original weights, si 는 i th input feature map으로 만든 scaling factor, j,k 는 convolution의 spatial footprint
- Instance normalization의 목적은 s 를 output feature map에서 제거하는 것
- 저자는 이 목적을 더 직접적으로 달성할 방법을 제시,
- input activation이 unit std를 가진 i.i.d 랜덤 변수로 가정하면 output의 activation의 std는 아래 식과 같다 (output의 L2 norm과 동일)
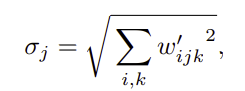
- 이후 normalization의 목표는 outputs을 다시 unit standard deviation으로 되돌리는 것 → output feature map j 를 1/σj 으로 scaling하여 목표 달성 가능
- 위 scaling도 마찬가지로 convolution weights에 적용할 수 있다
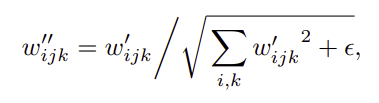
- style block 전체를 하나의 convolution에 담을 수 있음
- demodulate는 통계적 가정에 기반한 변환이기 때문에 instance normalization보다 약함
- 새로운 디자인 (d)는 아티팩트를 제거하였으며 controllability 또한 그대로 유지, FID 또한 개선되었지만 Precision이 감소하고 Recall이 증가하는 문제가 있음
3. Image quality and generator smoothness
- Perceptual Path Length(PPL)을 최소화하는 것은 zero recall을 가지는 degenerate solution으로 generator를 guide
- 이러한 단점이 없으며 smoother generator mapping을 가능하게 하는 새로운 regularization term을 제시
3.1. Lazy regularization
- regularization term에 대한 계산을 매번 하지 않고 일정 주기로 계산하여 computational cost와 memory usage를 개선
3.2. Path length regularization
- image space에서 random direction으로 fixed size만큼 이동하였을 때 생기는 w 의 gradient는 모두 비슷해야 한다.
- single w∈W 에서, generator mapping g(w):W→Y 의 local metric scaling properties는 Jacobian matrix로 capture 가능 Jw=∂g(w)/∂w
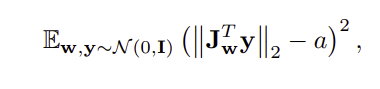
4. Progressive growing revisited
- Progressive growing은 고화질 이미지 생성 학습을 안정화시켜주지만 특유의 “phase” 아티팩트 문제가 존재
- key issue는 강한 location preference가 존재한다는 것
- 눈, 치아와 같은 부분이 이미지가 움직일 때(pose를 따라) 같이 바뀌어야 하지만 그대로 고정되어 있는 문제가 있음
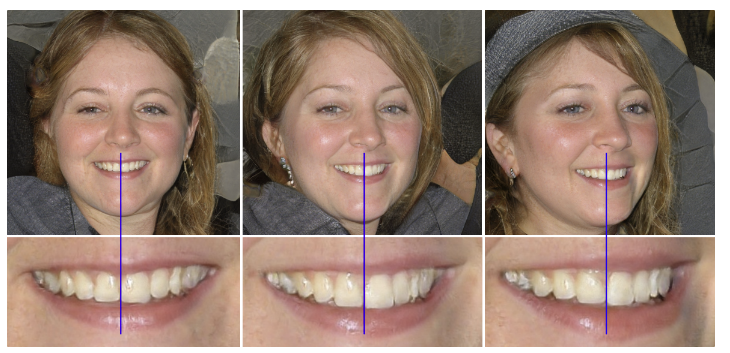
- progressive growing에서 각 resolution이 일정 period 동안 output resolution이 되기 때문에 maximal frequency detail을 생성하도록 학습이 강제되어 생기는 문제
- intermediate layer에서 excessively high frequencies를 요구 → shift invariance
4.1. Alternative network architectures
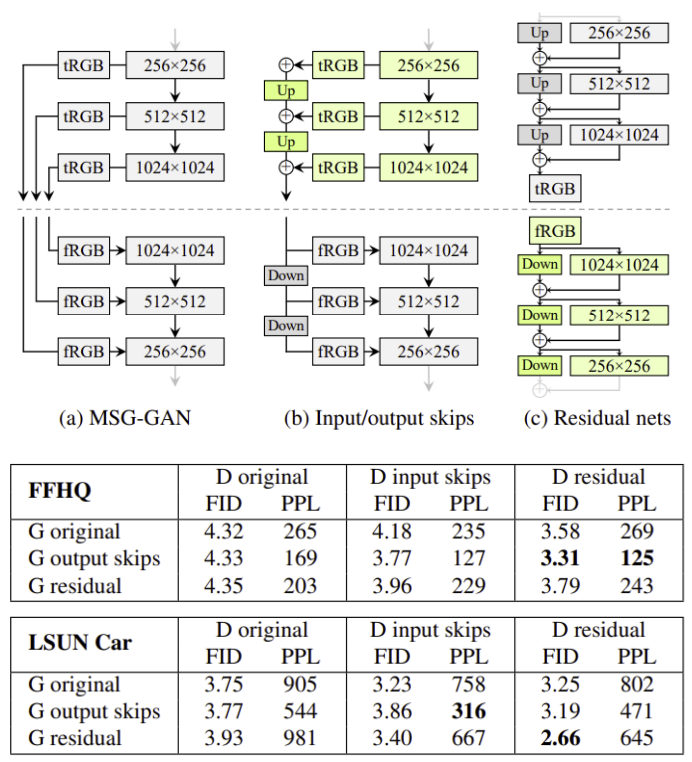
- MSG-GAN의 구조를 변형한 (b) skip generator의 결과가 가장 좋아 (b)를 사용
4.2. Resolution usage
- progressive growing의 먼저 low-resolution feature에 focus 하고 점차 finer detail에 focus 하는 특성은 그대로 가져가야 함
- 하지만 skip generator 구조는 위 특성을 강제하지 않기 때문에 이를 확인하기 위해 각 resolution의 RGB 특성이 final image에 얼마나 영향을 미치는지 확인
- tRGB를 통과한 output의 std를 training time에 확인
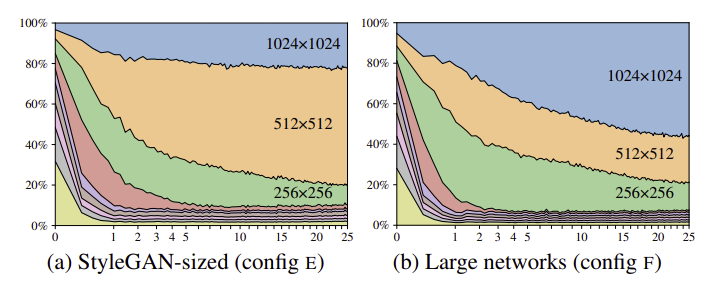
- skip generator가 progressive growing와 비슷하게 초기에 low resolution feature, 후기에 high resolution feature에 주목하는 것을 볼 수 있음
- 추가로 (a)를 보면 target resolution을 생성하는데 generator가 충분하지 않다는 것을 알 수 있음
- 생성 결과에서 pixel-level detail이 부족하며 1024x1024 생성 결과가 512x512의 sharpened version 정도의 디테일만 담고 있음을 확인
- network의 capacity problem을 의심하였고 64x64x ~ 1024x1024 resolution의 feature map의 수를 2배로 늘리자 (b)와 같이 higher-resolution layer의 기여가 증가함을 볼 수 있었음
- FID와 Recall도 큰 폭으로 향상
5. Projection of images to latent space
- synthesis network g 를 ingert 하는 것은 적용할 곳이 많은 interesting problem
- 기존 projection method와 다른 점
- latent space를 전체적으로 explore하기 위해 ramped-down noise를 latent space에 optimization 도중 추가
- StyleGAN generator의 stochastic noise를 개선
5.1. Attribution of generated images
- 실제 이미지를 latent code로 projection 후 다시 generator를 사용하여 re-synthesis하여 비교
- LPIPS distance를 사용하여 비교
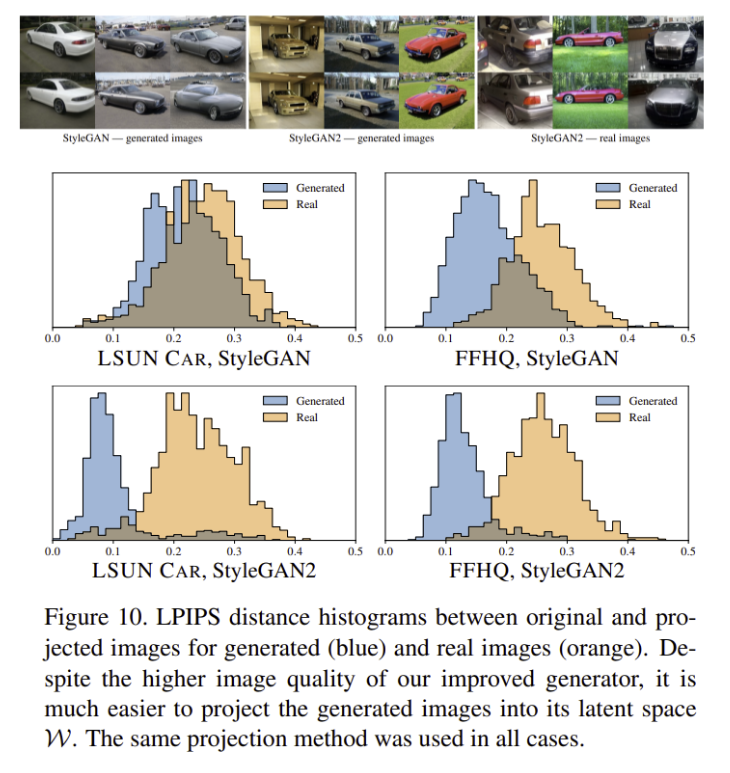
- StyleGAN2가 StyleGAN보다 latent space로 projection이 더 잘되는 것을 볼 수 있음
6. Conclusions and future work
- StyleGAN의 이미지 퀄리티 문제를 분석하고 해결하여 SOTA를 여러 dataset에서 달성
- Training performance 또한 향상, 더 빠른 학습, 더 적은 전력 사용
- future work으로는 path length regularization 개선, 학습 데이터 필요량 줄이기를 제시
후기 & 정리
- StyleGAN의 artifact 문제를 해결하기 위한 방법을 제시한 StyleGAN2
- Droplet artifact의 문제가 normalization에 있다는 것을 지적하며 controllability를 유지하며 이를 해결할 새로운 아키텍처를 제시
- 더 smooth한 latent space 형성을 위한 Path length regularization을 제시
- phase artifact의 발생원인을 progressive growing method의 중간 layer에서 high-frequency output 생성으로 규정하고 low -> high resolution focusing을 유지하면서 이를 대체할 MSG-GAN을 변형한 skip generator를 제시
- StyleGAN의 capacity 부족을 지적하여 channel을 늘려 성능 향상
- 기존 StyleGAN의 concept을 가져가면서 문제를 해결해나가는 과정이 흥미로웠던 논문
Reference
[0] Tero Karras et al. (2019). "Analyzing and Improving the Image Quality of StyleGAN". https://arxiv.org/abs/1912.04958. CVPR
'AI > Deep Learning' 카테고리의 다른 글
| AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer (0) | 2022.02.15 |
|---|---|
| CGAN: Conditional Generative Adversarial Nets (0) | 2022.02.09 |
| StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2022.01.31 |
| ConvNeXt: A ConvNet for the 2020s (0) | 2022.01.30 |
| MLP-Mixer: An all-MLP Architecture for Vision (0) | 2022.01.28 |
'AI/Deep Learning' Related Articles
more




Comments