
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 모션매칭
- 언리얼엔진
- Few-shot generation
- BERT
- multimodal
- 디퓨전모델
- dl
- ddpm
- 폰트생성
- userwidget
- deep learning
- RNN
- motion matching
- Font Generation
- WBP
- ue5.4
- Stat110
- Diffusion
- Generative Model
- NLP
- WinAPI
- cv
- 생성모델
- Unreal Engine
- 딥러닝
- UE5
- 오블완
- CNN
- GAN
- animation retargeting
Archives
- Today
- Total
Deeper Learning
AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer 본문
AI/Deep Learning
AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer
Dlaiml 2022. 2. 15. 16:16Prashanth Chandran, Gaspard Zoss, Paulo Gotardo, Markus Gross, Derek Bradley. DisneyResearch, Department of Computer Sceince ETH Zurich. (2021). CVPR
Abstract
- Style Transformer는 content image의 content를 유지하며 style image의 style을 입히는 CNN의 artistic 적용
- SOTA neural style transfer는 style image의 통계적 특성을 content image에 옮기는 AdaIN
- AdaIN은 global operation으로 local geometric structure를 무시하고 transfer 시키지 못하는 문제가 존재
- statistical, structural style을 동시에 real-time으로 transfer가 가능한 Adaptive Convolutions(AdaConv)를 제시
- Style transfer뿐 아니라 style-based image generation(ex.StyleGAN)에서도 AdaConv를 사용하는 등 같이 AdaIN을 대체할 수 있다.
Introduction
- Image에 style을 적용시키는 연구가 최근 많았음
- 전체적인 색상, brush stroke의 local structure, pose, expression 등이 style로 취급되었음
- Gatys의 nerual style transfer 이후 연구가 활발해졌으며 random vector input으로 style이 정의되는 GAN 또한 비슷한 컨셉
- AdaIN의 단점은 통계적 계산이 global operation이라는 것, style image의 localized spatial structure는 효과적으로 capture, transfer 되지 않음
- 아래 그림을 보면 style image가 흰색, 검은색의 원과 같은 distinct features를 가지고 있다고 하여도 AdaIN은 통계량을 transfer 하기 때문에 style image의 structure를 무시하는 것을 볼 수 있음

- AdaConv는 kernel, bias 값을 style image에서 추출하여 만든 convolution layer에 content image를 통과시킴
- kernel이 localized spatial structure를 capture 하여 좋은 결과
- AdaIN을 대체할 수 있는 generic style transfer block
Related Work
- AdaIN, StyleGAN(2)의 stylization method
- SPADE, SEAN의 per-pixel transformation
- dynamic kernel prediction
Feature Modulation with AdaConv
Overview
- style 표현을 a,b 로 여길 수 있음, (a = scale, b = bias)
- AdaIN은 normalized input features를 affine transform
- AdaIN은 각 채널을 a,b 에 따라 변화시키므로 x 의 spatial distribution을 고려하지 않음
- AdaConv는 style 표현을, {f,b},f∈\Rkh×kw 으로 확장
- style filter f 를 사용하여 spatially-varying way로 local structure를 고려하며 stylization
- 1x1 filter f , depth-wise AdaConv는 AdaIN으로 표현 가능
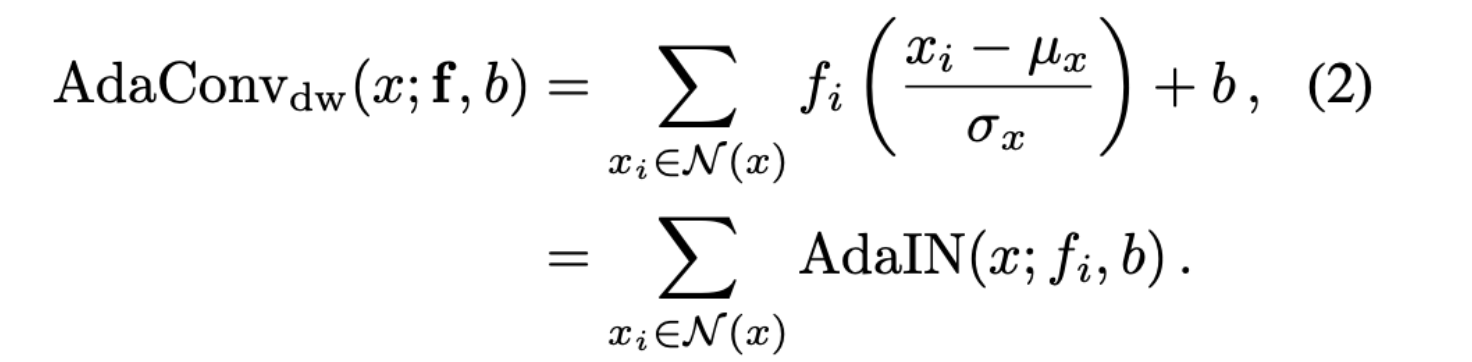
- style parameter에 separable, pointwise convolution tensor p∈\RC 를 추가하여 full AdaConv 구성
- global 통계량, spatial structure 뿐만 아니라 channel 간 correlation도 modulation 가능
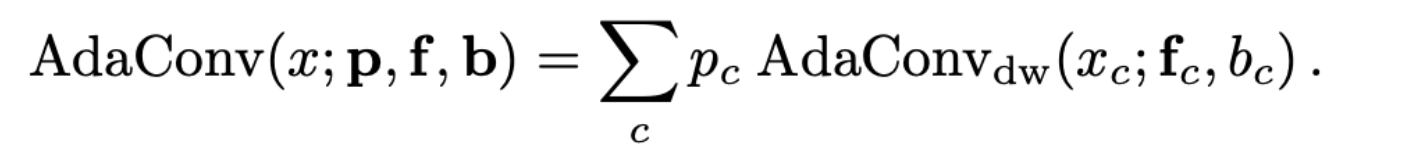
- depthwise-separable convolution layer의 group의 수를 조정하여 kernel parameter의 수 조정
Style Transfer with AdaConv
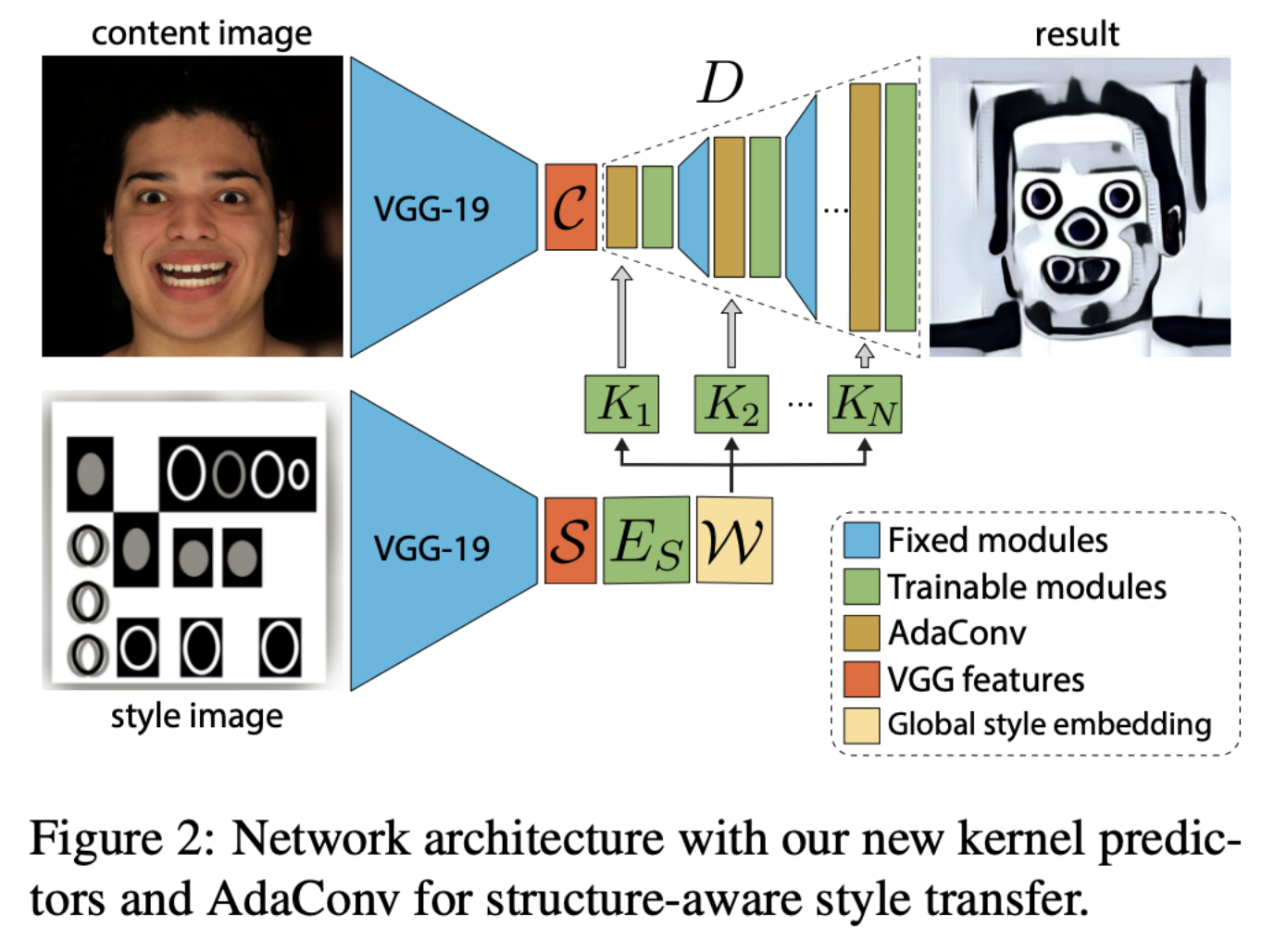
- style image를 VGG-19로 encoding 한 S 는 style encoder Es 에 의해 global style descriptor W
- W 는 kernel prediction network Ki 를 통해 per-channel biases를 가진 depthwise-separable convolution kernel이 됨
- AdaConv의 마지막 convolution layer(not adaptive)는 style에 독립적으로 natural image를 reconstruct 하도록 학습됨
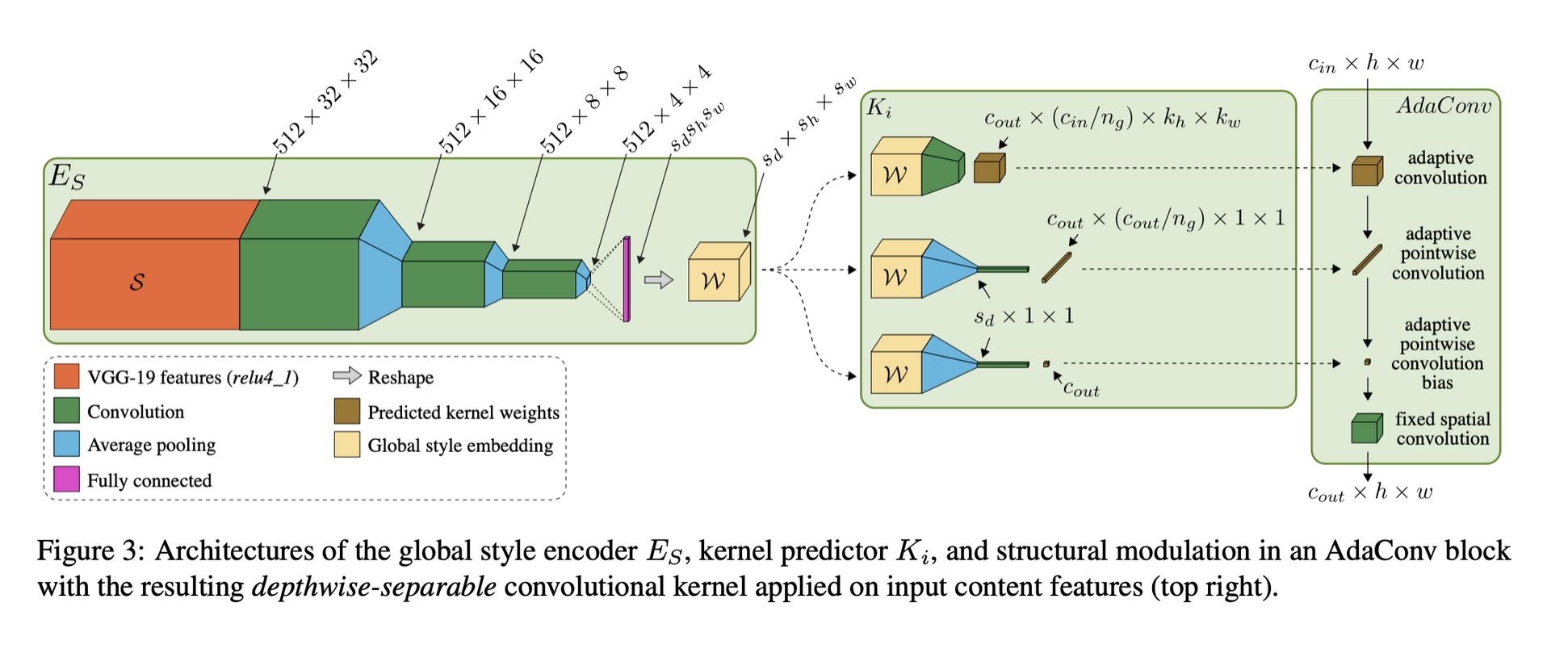
Style Encoder
- 512x32x32 shape의 S 의 receptive field는 전체 style image보다 작기 때문에 Style Encoder를 사용
Predicting Depthwise-Separable Convolutions
- kernel predictor의 효율성, 심플함을 위해 depthwise-separable convolution의 kernel을 predict
- standard convoluton의 경우 (cout,cin,kh,kw)의 parameter, depthwise-separable convolution의 parameter는 group에 따라 더 줄어듦
- decoder에서 4번의 AdaConv를 적용하는데 이때 resolution은 점점 증가, channel은 점점 감소함
- ng= (num of groups)은 resolution이 커짐에 따라 감소

- ng= (num of groups)은 resolution이 커짐에 따라 감소
Results



Conclusion
- structure-aware style transfer가 가능한 AdaConv를 제시
- global 통계량만을 사용하여 stylization을 하던 AdaIN과 달리 spatial-structure 또한 transfer
- AdaIN을 대체할 수 있음
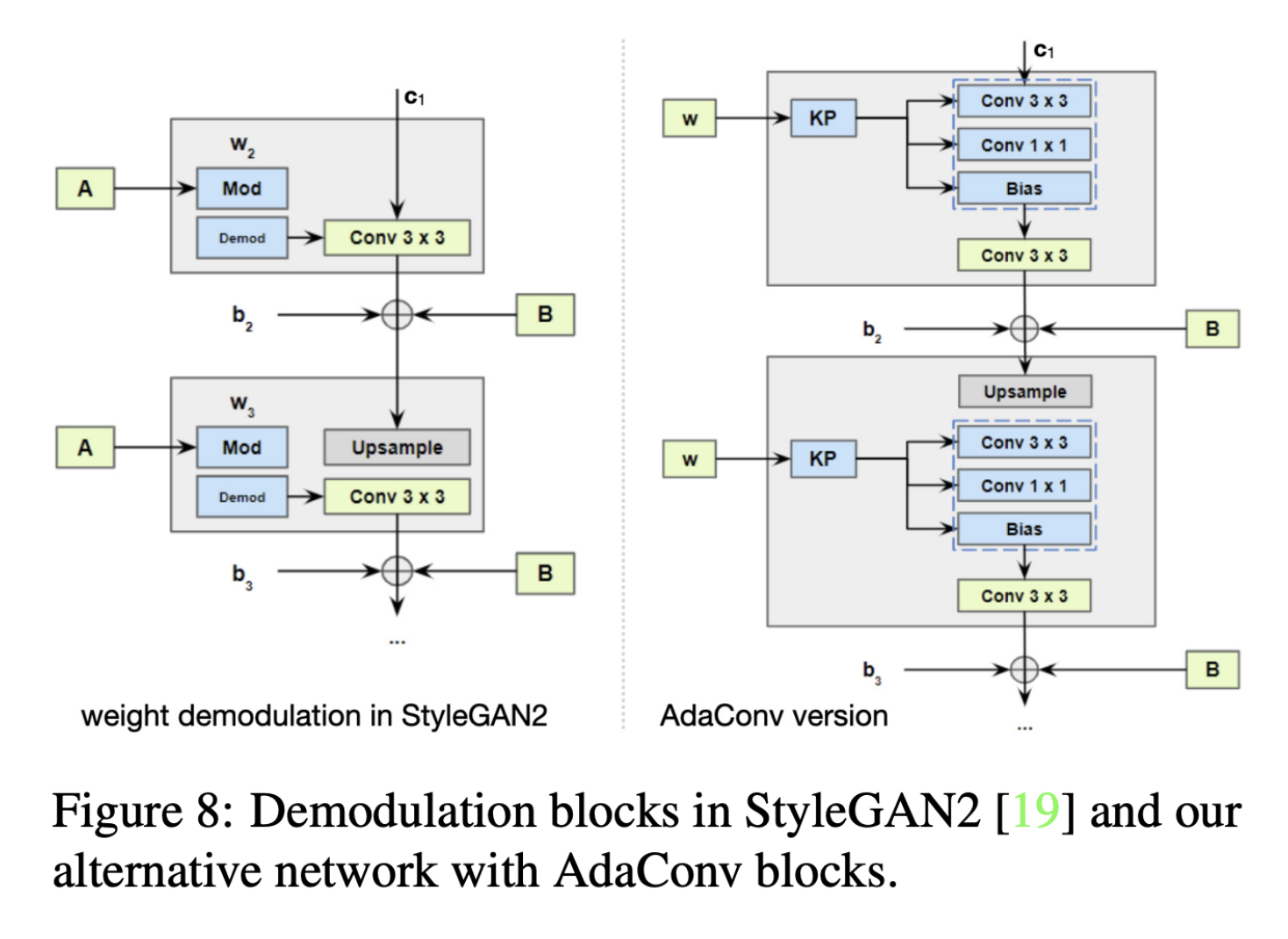
- conditioning input data를 주입하는 CNN-based image 생성, style 조정에 사용 가능
후기 & 정리
- global 통계량만을 사용하여 localized structure를 transfer하지 못하던 AdaIN과 달리 kernel 자체를 convolution layer를 통해 생성하여 stylization 하는 AdaConv를 제시
- 기존 AdaIN을 대체할 수 있으며 condition input을 통해 image를 생성하거나, style을 조정할 때도 사용 가능한 AdaConv
- 간단한 모듈을 제시한 논문이라 AdaConv의 구조와 컨셉만 캐치하고 나머지는 훑으며 마무리
Reference
[0] Prashanth Chandran et al. (2021). "Adaptive Convolutions for Structure-Aware Style Transfer". https://openaccess.thecvf.com/content/CVPR2021/papers/Chandran_Adaptive_Convolutions_for_Structure-Aware_Style_Transfer_CVPR_2021_paper.pdf. CVPR
'AI > Deep Learning' 카테고리의 다른 글
| ConvMixer: Patches Are All You Need? (0) | 2022.02.21 |
|---|---|
| GANet: Glyph-Attention Network for Few-Shot Font Generation (0) | 2022.02.18 |
| CGAN: Conditional Generative Adversarial Nets (0) | 2022.02.09 |
| StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN (0) | 2022.02.07 |
| StyleGAN: A Style-Based Generator Architecture for Generative Adversarial Networks (0) | 2022.01.31 |
'AI/Deep Learning' Related Articles
more




Comments