
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- userwidget
- RNN
- ddpm
- 모션매칭
- 생성모델
- GAN
- WBP
- Unreal Engine
- Few-shot generation
- Diffusion
- 디퓨전모델
- 언리얼엔진
- 폰트생성
- 오블완
- cv
- UE5
- multimodal
- CNN
- animation retargeting
- Generative Model
- WinAPI
- Font Generation
- Stat110
- deep learning
- dl
- BERT
- motion matching
- 딥러닝
- ue5.4
- NLP
Archives
- Today
- Total
Deeper Learning
GANet: Glyph-Attention Network for Few-Shot Font Generation 본문
AI/Deep Learning
GANet: Glyph-Attention Network for Few-Shot Font Generation
Dlaiml 2022. 2. 18. 12:23Under review as a conference paper at ICLR 2022
Mingtao Guo, Wei Xiong, Zheng Wang, Yong Tang, Ting Wu. Xian Univ. (2021.09)
Abstract
- Non-local neural network에서 영감을 받아 제시한 GANet
- content encoder와 style encoder는 content glyph과 style glyph에서 key와 value를 추출
- 기존 SOTA few-shot font 생성 모델을 뛰어넘는 결과
Introduction
- 중국 폰트에 대한 인기가 세계적으로 증가하면서 니즈또한 증가하고 있음
- 그러나 폰트 생성은 노동집약적이며 오랜시간이 걸림
- image to image translation과 GAN으로 폰트를 생성하는 시도가 많았으나 finetune에 의존하였음
- 기존 Few-shot 폰트 생성은 style이 약하거나 content가 손상되는 문제가 있었음
- 전체적인 구조를 추출하기 위해 content glyph-attention module, local stroke 특성을 추출하기 위해 style glyph-attention module을 사용
Method

- Style set, Content set, query image를 input으로 사용
- Non-local network의 Attention module의 구조를 사용
Style Glyph Attention
- font domain에서 style은 기존 stylization에서 말하는 그것과 다르게 color와 texture가 아닌 stroke의 집합
- local stroke 정보를 살리기 위한 reshape
- key와 query를 inner product할 때 channel 축이 사라짐
- height, width의 차원은 그대로 살아서 attention score를 계산
Content Glyph Attention
- global content feature를 살리기 위한 reshape
- content glyph set을 구성하는 glyph의 수인 N에 attention score를 부여
multi-task Discriminator
- Projection discriminator 사용
- Content를 판별하는 Content discriminator
- Style을 판별하는 Style discriminator
- Hinge loss 사용
Identity loss
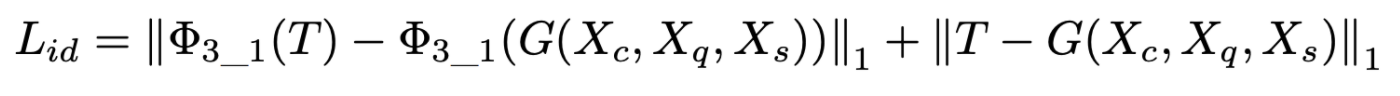
- generated image, true image의 L1 loss와 VGG relu_3_1 feature map에서 L1 loss를 사용
Feature Matching loss
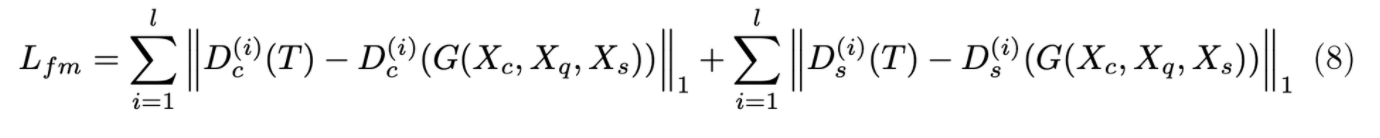
- True image와 generated image의 Style & Content Discriminator의 모든 layer의 feature map끼리 L1 loss를 더하여 구성
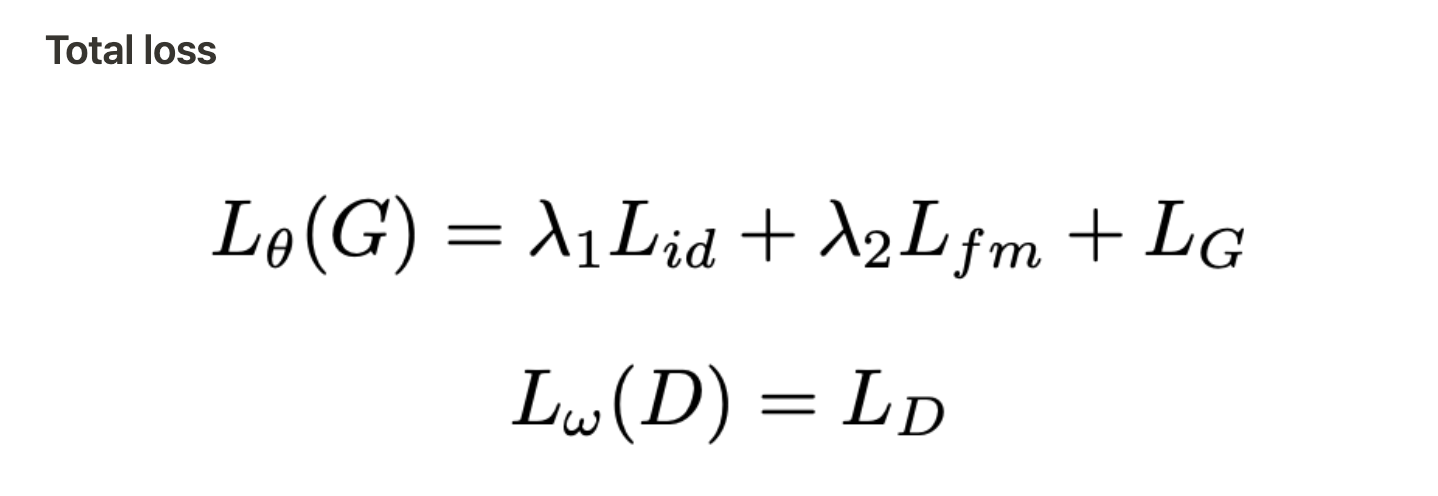
Experiments


Conclusion
- few-shot font generation을 위한 모델인 GANet을 제시
- 적은 수의 reference glyph으로 high-quality 결과를 보여줌
- glyph attention module, multi-task discriminator로 구성한 GANet으로 SOTA 퀄리티를 보여줌
후기 & 정리
- 단순하게 non-local network 구조를 가져온 아키텍처
- font domain에서 style, content를 local과 global 한 특성으로 구분하여 reshape을 통해 attention score가 부여되는 차원을 조절하는 것이 유일한 novelty
- 각 모듈에 대한 검증 및 설명이 부족함
- 랜덤 샘플링하는 content, style stack에서 유의미한 spatial & content attention을 꾸준하게 뽑아낼 수 있는지 의문
- 기존 method와의 비교 예시가 더 많았어야 한다고 생각
Reference
[0] Mingtao Guo et al. (2021). "GANet: Glyph-Attention Network for Few-Shot Font Generation". Under review as a conference paper at ICLR 2022
https://openreview.net/pdf/3e4c2baccd8879ac685fc39ed0c7440aade346a8.pdf
'AI > Deep Learning' 카테고리의 다른 글
| VAE: Auto-Encoding Variational Bayes (0) | 2022.02.26 |
|---|---|
| ConvMixer: Patches Are All You Need? (0) | 2022.02.21 |
| AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer (0) | 2022.02.15 |
| CGAN: Conditional Generative Adversarial Nets (0) | 2022.02.09 |
| StyleGAN2: Analyzing and Improving the Image Quality of StyleGAN (0) | 2022.02.07 |
'AI/Deep Learning' Related Articles
more




Comments