
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Diffusion
- RNN
- Stat110
- deep learning
- 오블완
- Unreal Engine
- BERT
- ue5.4
- Generative Model
- dl
- ddpm
- WinAPI
- Font Generation
- Few-shot generation
- 생성모델
- 모션매칭
- motion matching
- WBP
- GAN
- 언리얼엔진
- multimodal
- UE5
- NLP
- animation retargeting
- cv
- CNN
- 디퓨전모델
- 폰트생성
- 딥러닝
- userwidget
Archives
- Today
- Total
Deeper Learning
ConvMixer: Patches Are All You Need? 본문
Asher Trockman, J.Zico Kolter. Carnegie Mellon University and Bosch Center for AI. (2022.01.24)
Abstract
- CNN이 vision task에서 지배적인 아키텍처였으나 최근 ViT가 SOTA를 달성
- self-attentoin의 quadratic runtime의 한계로 large images를 처리하기 위해 patch embedding을 사용한다.
- 여기서 질문, ViT의 성능은 Transformer 아키텍처로 인한 것인가? 아니면 input representation으로 patch를 사용한 것이 영향을 끼쳤는가?
- 논문은 후자에 대한 증거를 제시한다
- patch를 바로 input으로 받는 MLP-Mixer, 같은 resolution을 network내에서 유지하며 spatial, channel dimension을 separate 하는 ConvMixer를 제시
- ConvMixer는 mixing step에 오직 convolution을 사용
- 비슷한 data size, parameter 수에서 ViT, MLP-Mixer, ResNet의 성능을 넘어섬
1. Introduction
- CNN이 vision task에서 지배적인 아키텍처였으나 최근 Vision Transformer 아키텍처가 large dataset이 있는 상황에서 CNN의 성능을 넘어섬
- Transformer based 아키텍처의 문제는 self-attention의 quadratic 계산 복잡도
- pixel 단위로 self-attention을 적용하는 것은 거의 불가능하기 때문에 먼저 patches로 이미지를 나누고 linearly embedding을 적용시킨 patches에 transformer를 적용
- 저자는 ViT의 뛰어난 성능이 Transformer 아키텍처가 아닌 patch-based representation에 있을 수 있다는 질문에 대해 연구
- MLP-Mixer와 비슷한 ConvMixer를 제시
- patches representation
- 모든 layer에서 동일한 input resolution
- no downsampling
- channel-mixing, spatial-mixing
- ConvMixer는 ViT, MLP-Mixer와 다르게 standard convolution만을 사용

- 매우 단순한 구조임에도 불구하고 ConvMixer는 비슷한 parameter에서 ResNet, ViT, MLP-Mixer의 성능을 뛰어넘음
- ConvMixer는 성능이나 속도를 높이기 위한 모델 디자인이 아니며 patch representation 자체가 ViT, MLP-Mixer 등 모델의 성능에 영향을 미치는 중요한 요인이라는 것을 제시하는 모델
- patch embedding의 효과를 정확히 다른 요인들과 disentangle 하기 위해서는 많은 실험이 필요하지만 ConvMixer가 미래에 다른 향상된 아키텍처와 비교할 수 있는 강력한 convolutional-but-patch-based baseline이 될 수 있을 것이라 믿는다
2. A Simple Model: ConvMixer
- ConvMixer는 patch embedding layer 이후 반복되는 단순한 convolutional block으로 구성된 간단한 구조
- patch size p, embedding dimenstion h의 patch는 다음과 같이 convolution으로 만들 수 있다.
- input channel cin, output channel h, kernel size p, stride p
- ConvMixer Block은 depthwise convolution(group num = channel dim), pointwise convolution(1x1 kernel)로 구성
- Depthwise convolution에는 large kernel 사용, post-activation BN 사용
- ConvMixer Block을 반복하고 global pooling, softmax classifier를 사용하여 prediction
- ConvMixer의 instance는 다음과 같이 4개의 parameter로 결정된다.
- width(hidden dimenstion) h
- depth d (number of ConvMixer layer)
- patch size p, internal resolution을 조정
- kernel size k of depthwise convolution layer
- variants를 ConvMixer-h/d로 이름 붙임
- MLP나 self-attention은 멀리 떨어진 정보도 mix 하지만 작은 kernel size의 CNN은 그렇지 못하기 때문에 ConvMixer에서는 large size kernel을 사용
- MLP와 self-attention이 이론적으로 더 flexible 하며 larger receptive field를 가지고 content-aware operation이지만 convolution의 bias는 vision task에 적합하여 데이터의 효율적 사용을 가능케 함
3. Experiments
ImageNet-1k classification task 수행
RandAugment, mixup, CutMix, random erasing, gradient norm clipping 사용
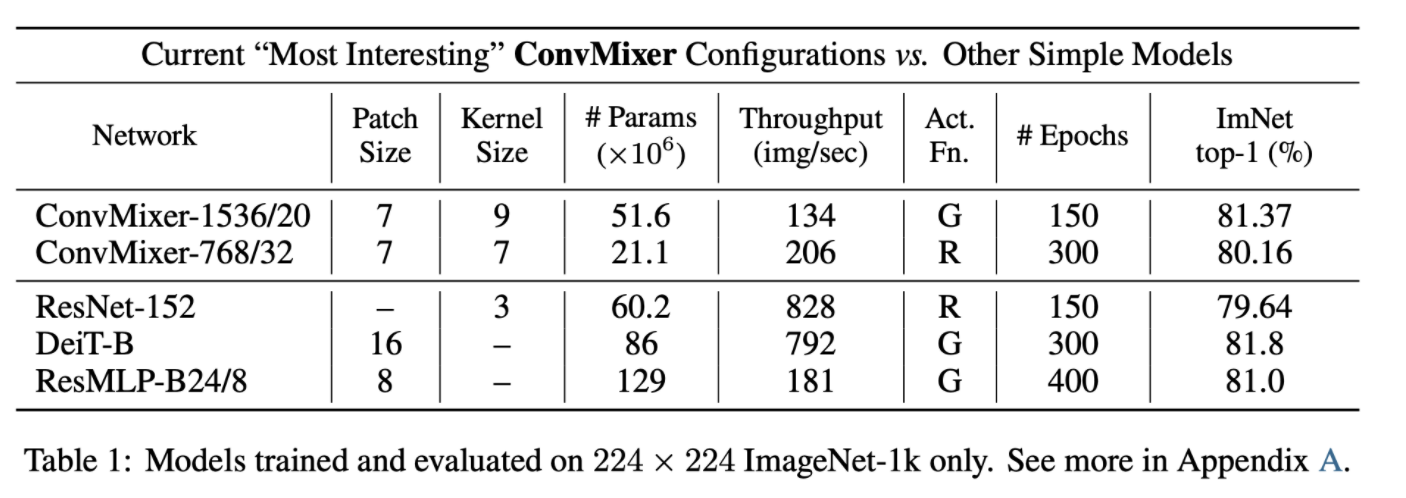
- large kernel에서 더 좋은 성능, smaller patches에서 더 좋은 성능, large patches는 더 큰 network를 요구
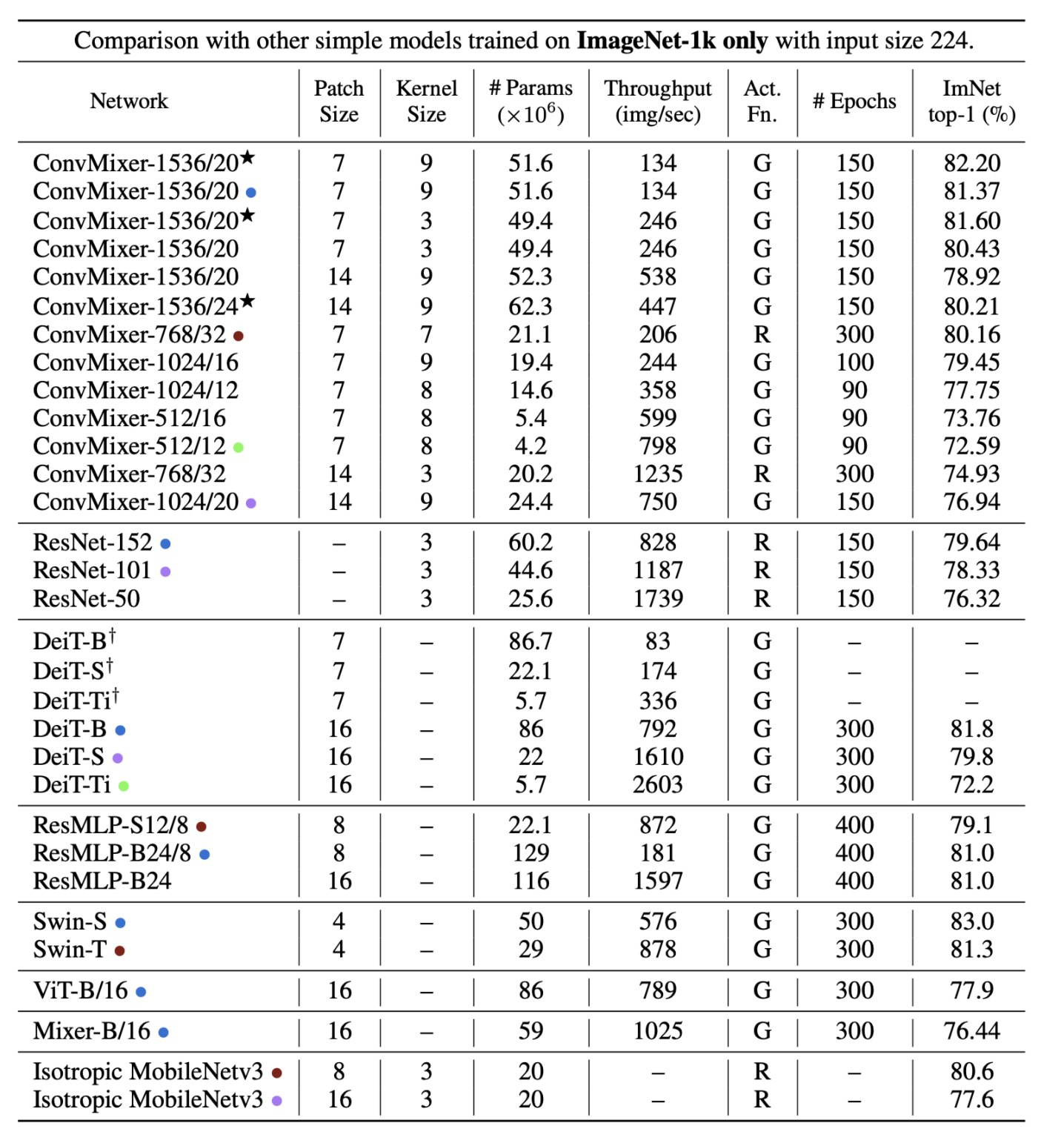
- ConvMixer-1536/20은 ResNet-152, ResMLP-B24 보다 적은 parameter로 비슷한 성능을 보였으며 DeiT과도 견줄만한 성능을 보임
- ConvMixer-768/32는 ResNet-152의 1/3 정도의 parameter로 구성되어 있으나 비슷한 성능을 기록함
- 하지만 smaller patch size로 인해 inference throughput이 다른 모델에 비교했을 때 낮은 문제가 있음
- hyperparameter tuning과 최적화가 아직 적용하지 않은 ConvMixer이기 때문에 개선의 여지가 있음
4. Conclusion
- standard convolution만을 사용하여 patch embedding의 spatial, channel information을 mix 하는 ConvMixer를 제시
- 정확도와 속도를 향상시키기 위한 실험을 하지 않았음에도 ViT, MLP-Mixer의 성능을 뛰어넘었으며 ResNet, DeiT, ResMLP와 비슷한 성능을 보임
- feature의 resolution이 유지되는 isotropic 아키텍처 + patch embedding 자체가 딥러닝에서 강력한 teamplate라는 증거를 제시
- Transformer를 vision task에 적용할 때 attention 뿐 아니라 patch embedding의 효과도 존재한다는 것을 강조
- SOTA를 달성하지는 못하였지만 patch-mixing design 자체의 효과와 후에 patch-based 아키텍처의 베이스라인이 될 수 있을 것이라고 생각
- future work으로는 모델 & 학습 최적화, Semantic segmentation 등 다른 task에 적용, patch embedding의 다른 factor와 disentangle 된 고유한 효과에 대한 연구를 제시
후기 & 정리
- Transformer의 self-attention이 아닌 patch embedding의 효과에 집중하여 standard convolution으로만 구성한 ConvMixer를 제시
- 작은 데이터셋에서도 적은 parameter로 나쁘지 않은 성능을 보임
- 구현 또한 매우 간단하며 SA, MLP의 large receptive field concept을 가져오기 위해 large size kernel을 사용
- NLP의 Transformer를 그대로 vision에 적용한 ViT가 여러 후속 논문들에 의해 분석되고 있음
- computing power, memory가 발전함에 따라 high resolution image가 지금보다 더 일반적인 input이 되면 patch-base도 마찬가지로 정석이 될 수 있을 것이라 생각
- 코드 또한 아래와 같이 간단하여 적용도 쉽기 때문에 모델 최적화에 대한 연구가 더 이루어졌으면 좋겠다고 생각
# https://github.com/locuslab/convmixer/blob/main/convmixer.py
def ConvMixer(dim, depth, kernel_size=9, patch_size=7, n_classes=1000):
return nn.Sequential(
nn.Conv2d(3, dim, kernel_size=patch_size, stride=patch_size),
nn.GELU(),
nn.BatchNorm2d(dim),
*[nn.Sequential(
Residual(nn.Sequential(
nn.Conv2d(dim, dim, kernel_size, groups=dim, padding="same"),
nn.GELU(),
nn.BatchNorm2d(dim)
)),
nn.Conv2d(dim, dim, kernel_size=1),
nn.GELU(),
nn.BatchNorm2d(dim)
) for i in range(depth)],
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(dim, n_classes)
)Reference
[0] Asher Trockman, J.Zico Kolter. Carnegie Mellon University and Bosch Center for AI. (2022.01.24). "PATHCES ARE ALL YOU NEED?". https://arxiv.org/pdf/2201.09792.pdf
[1] https://github.com/locuslab/convmixer/blob/main/convmixer.py
'AI > Deep Learning' 카테고리의 다른 글
| Font Generation with Missing Impression Labels (0) | 2022.03.23 |
|---|---|
| VAE: Auto-Encoding Variational Bayes (0) | 2022.02.26 |
| GANet: Glyph-Attention Network for Few-Shot Font Generation (0) | 2022.02.18 |
| AdaConv: Adaptive Convolutions for Structure-Aware Style Transfer (0) | 2022.02.15 |
| CGAN: Conditional Generative Adversarial Nets (0) | 2022.02.09 |
'AI/Deep Learning' Related Articles
more



