
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- WinAPI
- Few-shot generation
- 디퓨전모델
- Font Generation
- 오블완
- WBP
- GAN
- Stat110
- 딥러닝
- Diffusion
- 폰트생성
- multimodal
- Unreal Engine
- 모션매칭
- userwidget
- CNN
- NLP
- ddpm
- UE5
- 언리얼엔진
- BERT
- 생성모델
- ue5.4
- motion matching
- dl
- RNN
- deep learning
- animation retargeting
- Generative Model
- cv
Archives
- Today
- Total
Deeper Learning
Font Generation with Missing Impression Labels 본문
Seiya Matsuda, Akisato Kimura, Seiichi Uchida, Kyushu Univ., NTT, (2022.03)
Abstract
- impression labeling 된 dataset을 사용하여 specific impression fonts를 GAN으로 생성하는 것이 목표
- Main difficulty
- font impression은 애매
- 특정 impression label이 없다고 그 폰트가 해당 impression에 해당하지 않는 것이 아님 (dataset이 불안정)
- Key Idea
- co-occurrence-based missing label estimate
- impression label space compressor
- MyFonts 데이터셋은 전문가 + 비전문가가 tagging 한 font-impression label pair data
- missing multi-label을 예측하고 이를 통해 폰트를 생성하는 method를 제시
1. Introduction
- MyFonts 데이터셋은 전문가 + 비전문가가 tagging한 font-impression label pair data
- 데이터셋의 label 일관성이 부족
- 예시로 abdominal-krunch 폰트는 thick, bold와 같은 impression을 가지고 있으나 labeler는 이를 tagging하지 않았음

- CP-GAN, CMLE, ILSC 등 모듈을 제시
- 전체 모델 아키텍쳐
- main contributions
- missing label에 대한 강건함을 가지는 impression 기반 폰트 생성 cGAN 제시
- missing label 상황에서 image 생성 시스템을 제시
- 다른 method와 비교하였을 때 더 나은 결과를 증명하기 위한 quantitative & qualitative experiments
2. MyFonts Dataset
- 26개의 char classes (알파벳)
- Google News Dataset으로 pretrain 한 word2vec을 사용하기 때문에 vocab에 없는 impression을 삭제하는 전처리
- 17202개의 폰트 사용, 1430개의 impression 사용
3. The Proposed Model
auxiliary classifier를 통해 얻은 multi-label (multi-hot impression label)을 condition으로 image를 생성하는 CP-GAN 형식을 따름
CP-GAN
- CP-GAN (Class-Distinct and Class-Mutual Image Generation with GANs (BMVC 2019))
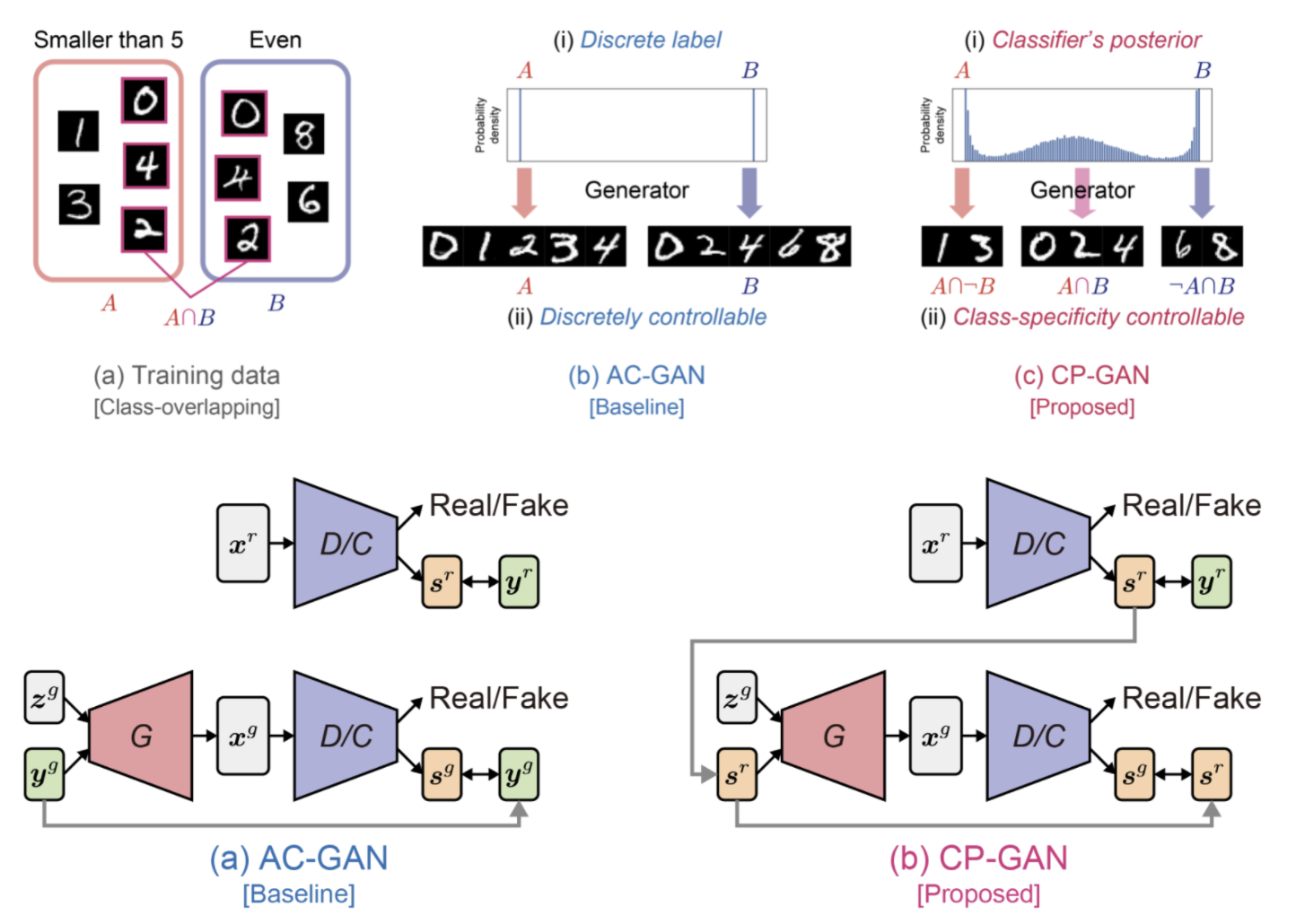
- 위 그림들에 직관적으로 모델 구조가 잘 설명되어있음
- AC-GAN의 구조를 따르나 CP-GAN은 class 간 관계를 classifier posterior를 통해 capture 하여 generator에 feeding
Co-occurrence-based missing label estimator(CMLE)
- CMLE는 co-occurrence matrix를 사용하는 missing label estimator
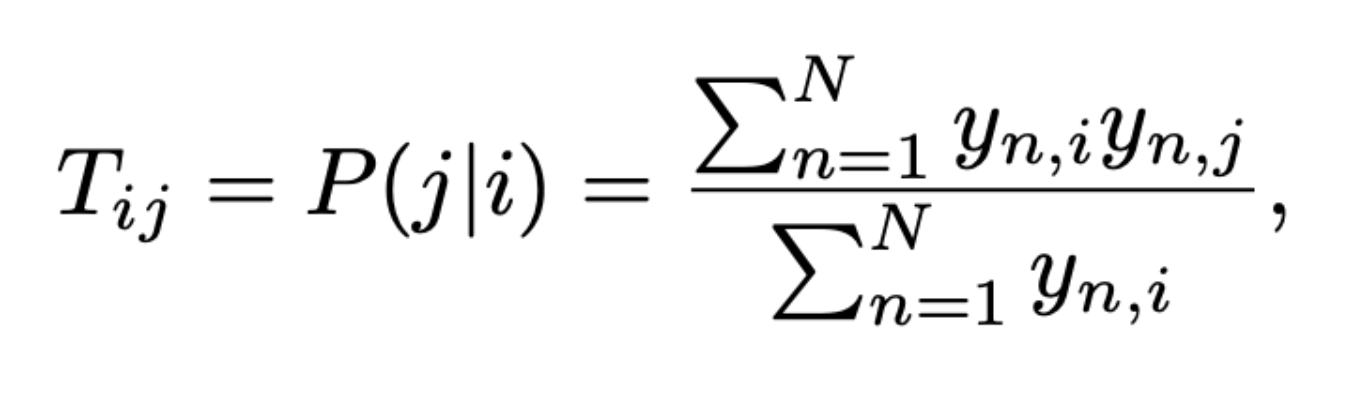
- n은 font index
- i, j는 impression
- 단순한 동시발생 matrix
CMLE
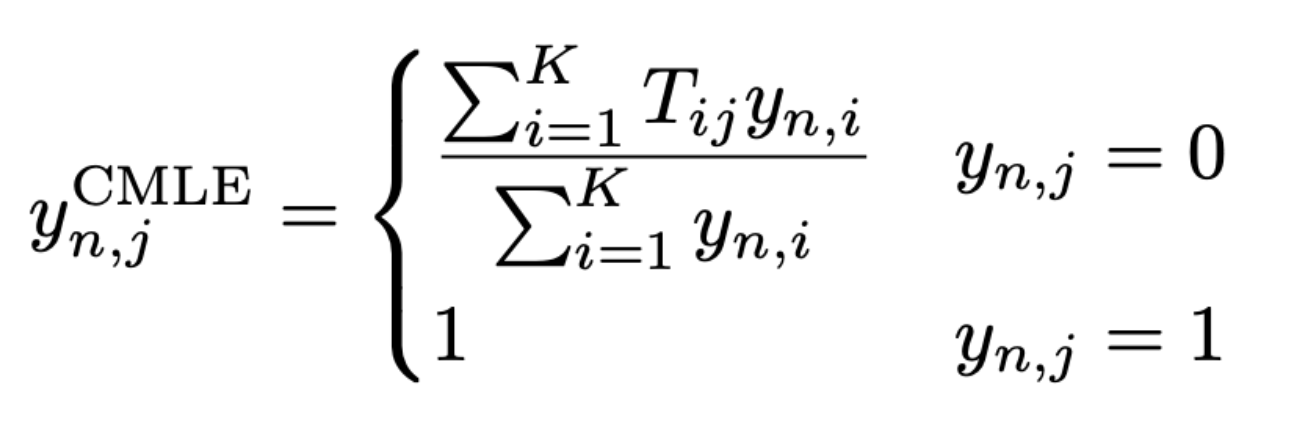
- font n에 impression j가 있을 경우 해당 impression label은 1 (attached)
- font n에 impression j가 없을 경우 해당 impression label은 0이 아니라 matrix T에서 해당 font의 attached labels, j를 사용하여 label을 부여합니다.
- CMLE로 estimate한 multi-hot label을 ground-truth impression label로 사용합니다.
Impression label space compressor(ILSC)
- ILSC는 간단한 two-layer encoder-decoder
- auxiliary classifier로 예측한 K-dim impression이 input이 되며 output의 차원도 동일합니다 (input: 분류기가 예측한 K개의 impression의 confidence)
- latent dim은 K보다 작은 d
- d개의 기저벡터는 각각 비슷한 impression을 압축한 새로운 impression 표현을 가지도록 학습됩니다. (thick, bold, thin이 original impression일 때 d=2이면 의미가 비슷한 impression이 thick bold가 하나의 기저벡터에 의해 표현되기를 기대)
- 따라서 만약 auxiliary classifier가 thick이라는 impression을 예측하지 못하였여도 잘 학습된 ILSC를 사용하면 다시 K-dim impression으로 decoding 되었을 때 thick을 예측 가능 (missing label prediction)
- auxiliary classifier는 CMLE output을 ground-truth로 pretraining.
4. Experimental Results
- impression 간 correlation heatmap
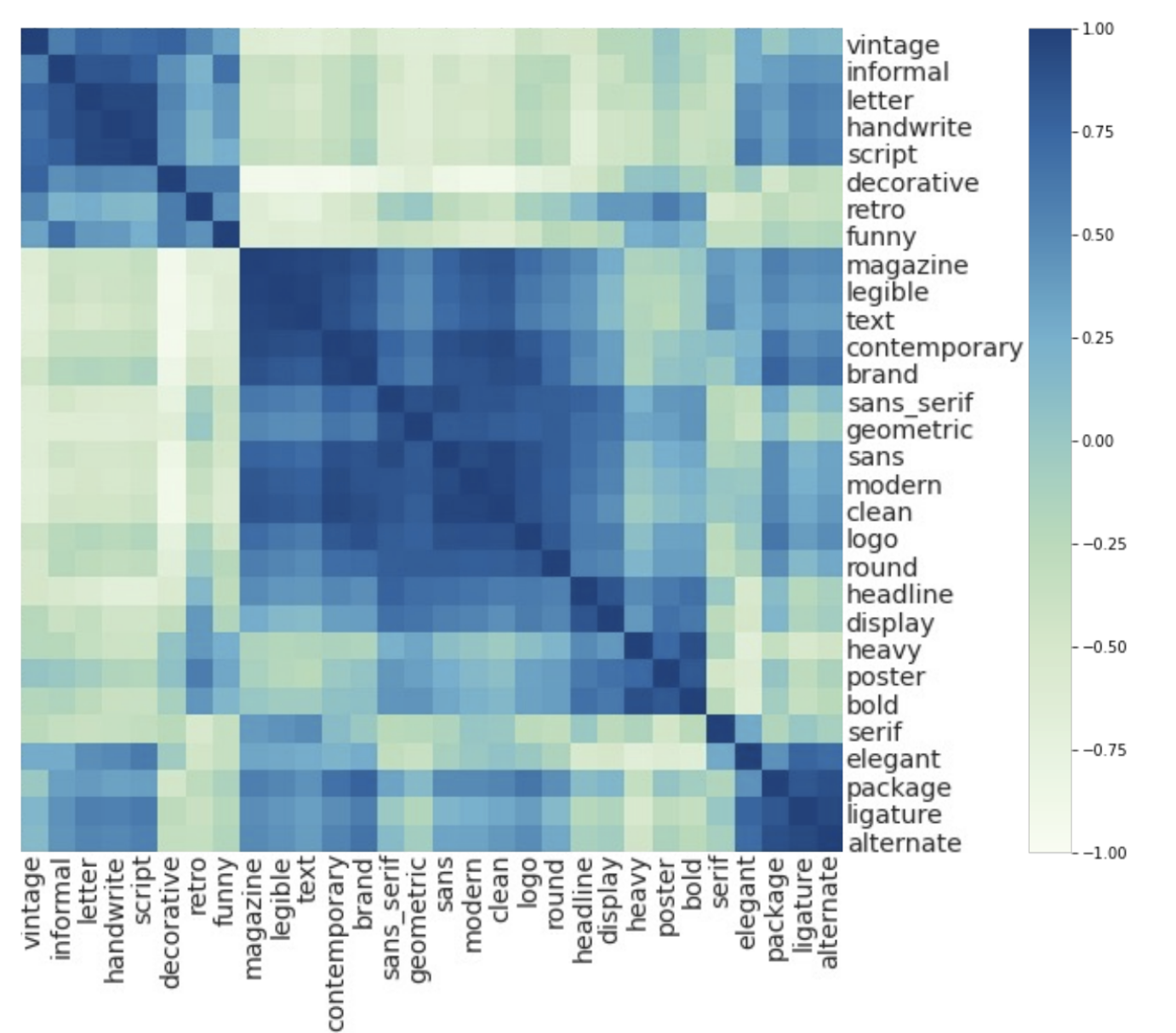
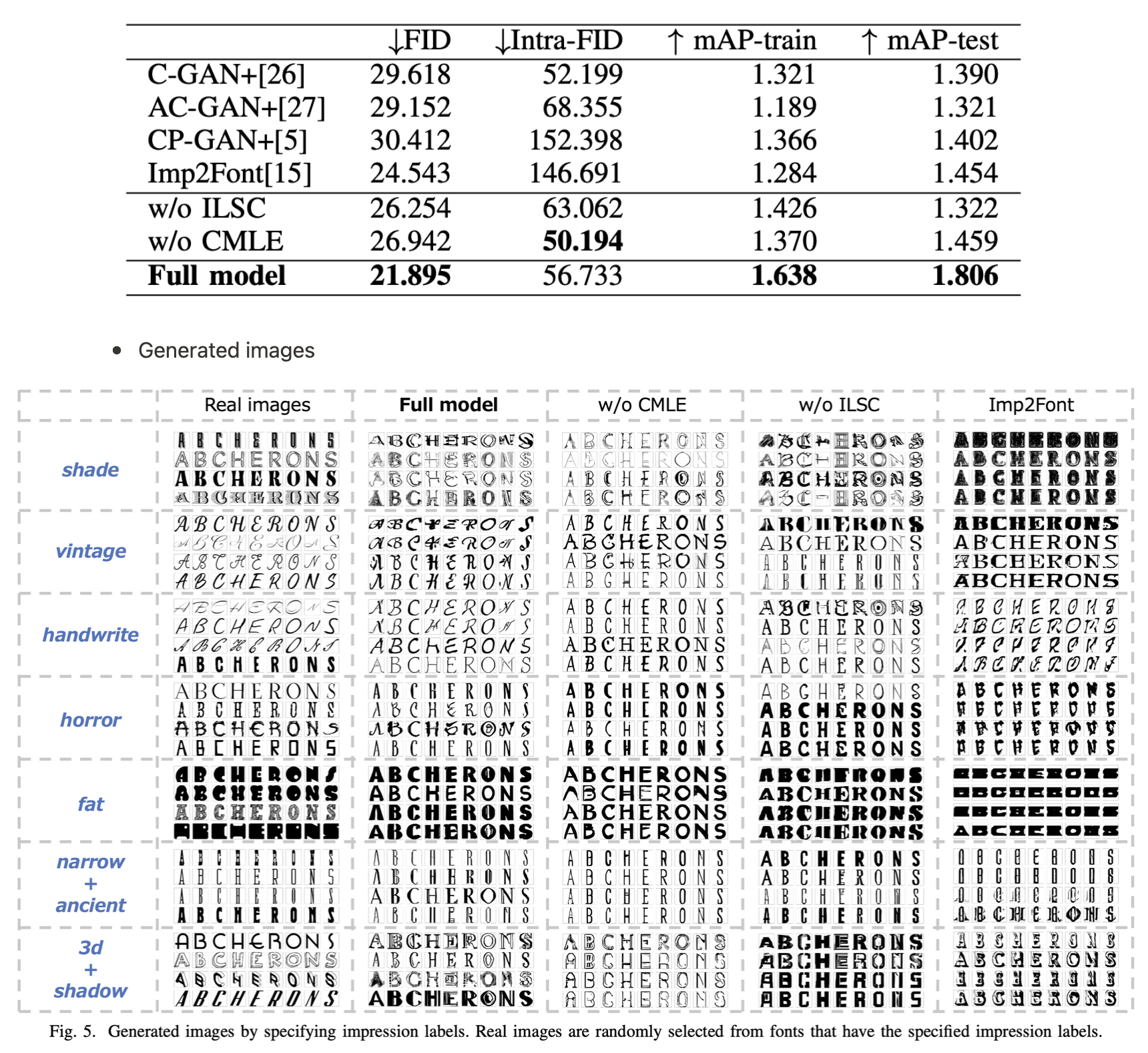
- Interpolation

5. Conclusion and Future work
- missing label에 robust 한 cGAN을 사용하여 impression을 condition으로 font를 생성하는 새로운 방식 제시
- co-occurrence-based missing label estimator(CMLE), impression label space compressor(ILSC)를 제시
- 여러 실험을 통해 제시한 method가 더 높은 퀄리티와 diversity를 달성함을 보임
- Future work
- 제시한 method로 font impression estimate (auxiliary classifier)
- ILSC를 사용하여 비슷한 impression을 분석할 수 있음
후기 & 정리
- 2021년 5월의 동일 저자들의 impression-> font 생성 논문인 Imp2Font을 개선한 논문
- Imp2Font https://arxiv.org/pdf/2103.10036.pdf
- font impression의 문제점은 일관성 있게 태깅된 데이터셋의 부재
- label estimator를 SIFT를 사용한 key points 추출과 CMLE를 사용하여 구성해보면 좋을 듯 함
- Google news data로 pretrained 된 word2vec을 사용하여 자연어 관점에서 impression embedding 생성하는 것이 참신했음
- noise & gaussian perturbation에도 불구하고 고정된 multi-label에 대해 diversity가 부족해 보임
Reference
[0] Seiya Matsuda, Akisato Kimura, Seiichi Uchida, Kyushu Univ., NTT. (2022). "Font Generation with Missing Impression Labels". https://arxiv.org/pdf/2203.10348.pdf
'AI > Deep Learning' 카테고리의 다른 글
| f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization (0) | 2022.04.07 |
|---|---|
| GAN: Generative Adversarial Nets (0) | 2022.03.28 |
| VAE: Auto-Encoding Variational Bayes (0) | 2022.02.26 |
| ConvMixer: Patches Are All You Need? (0) | 2022.02.21 |
| GANet: Glyph-Attention Network for Few-Shot Font Generation (0) | 2022.02.18 |
'AI/Deep Learning' Related Articles
more



