
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- UE5
- Unreal Engine
- userwidget
- WinAPI
- multimodal
- Few-shot generation
- 디퓨전모델
- 딥러닝
- BERT
- animation retargeting
- 모션매칭
- ue5.4
- Font Generation
- 오블완
- 생성모델
- Diffusion
- Stat110
- RNN
- deep learning
- Generative Model
- WBP
- motion matching
- GAN
- 언리얼엔진
- CNN
- ddpm
- NLP
- dl
- cv
- 폰트생성
- Today
- Total
Deeper Learning
GraphCodeBERT: Pre-training Code Representations with Data Flow 본문
GraphCodeBERT: Pre-training Code Representations with Data Flow
Dlaiml 2022. 8. 26. 17:53Daya Guo, Shuo Ren, Shuai Lu, Zhangyin Feng, Duyu Tang, Shujie Liu, Long Zhou, Nan Duan, Alexey Svyatkovskiy, Shengyu Fu, Michele Tufano, Shao Kun Deng, Colin Clement, Dawn Drain, Neel Sundaresan, Jian Yin, Daxin Jiang and Ming Zhou
[School of Computer Science and Engineering, Sun Yat-sen University, Beihang University, Peking University, Harbin Institute of Technology, Microsoft Research Asia, Microsoft Devdiv, Microsoft STCA] (2020.09)
Abstract
- code pre-training 모델은 다양한 code 관련 task에서 큰 성능 향상을 보였지만 현존하는 방식들은 code snippet을 token의 sequence로 여겨 code를 이해하는데 도움이 되는 code의 고유 구조를 무시한다
- code의 고유 구조를 고려하는 프로그래밍 언어를 위한 pre-trained 모델인 GraphCodeBERT를 제시
- AST처럼 syntactic-level의 구조를 사용하지 않고 변수 사이의 값들의 “value가 어디서 왔는지” 관계를 인코딩하는 semantic-level의 구조를 사용
- masked language modeling에 추가로 2개의 structure-aware pre-training task로 학습
- predict code structure edges
- align representation between source code and code structure
- code structure에 효율적인 graph-guided masked attention function를 사용
- code search, clone detection, code translation, code refinement task에서 SOTA를 달성
- code search에서 모델이 token-level attentions 보다 structure-level attentions 에서 좋은 성능을 보이는 것을 확인
1. Introduction
- 기존 code 대상의 언어모델들은 code 고유의 구조를 무시하고 token의 sequence로 이를 취급하였음
- 하지만 code의 구조는 code를 이해하기 위해서 매우 중요한 역할을 한다
- v = max_value - min_value라는 코드에서 v라는 글자에서는 그 뜻을 알기 어려우나 코드 구조(”=”을 사용하여 할당)를 이해한다면 의미를 이해하기 수월함
- 6개 프로그래밍 언어의 2.3M개의 함수+자연어 pair 데이터셋인 CodeSearchNet dataset을 사용
- 저자가 언급한 contribution
- GraphCodeBERT는 code representation을 학습하기 위해 code의 semantic structure를 처음 활용한 pre-trained 모델
- source code와 data flow를 학습하기 위한 dataset 소개
- GraphCodeBERT는 code search, clone detection, code translation, code refinement task에서 좋은 성능을 보여줌
2. Data Flow
- Data flow는 node가 변수를 뜻하며 edge가 해당 변수가 어디에서 왔는지를 나타내는 graph의 형태
- v = max_value - min_value라는 코드에서 data flow는 v가 max_value, min_value에서 생겨난 것을 표현해줌
`

- code를 AST로 parsing 후 변수들을 node로 관계를 edge로 표현한 그래프로 변환
3. GraphCodeBERT

3.1. Model Architecture
- Figure 2에 잘 묘사되어있는데, 자연어, code, Data Flow의 node(변수들)이 [SEP] token을 사이에 두고 input으로 주어짐
- BERT의 구조를 따름
3.2. Graph-guided Masked Attention

- code token과 variable sequence에서 특정 keys가 query와 attention이 계산되지 않도록 masking
- query와 key가 서로 연결되지 않은 variable node, 또는 서로 관련이 없는 code, variable node일 때 masking을 통해 softmax 값이 0에 가깝게 되도록 -inf를 더해줌
3.3. Pre-training Tasks
Maksed Language Modeling
- source code와 pair comments의 token 중 15%를 masking
- 나머지 세팅은 BERT와 동일
Edge Prediction
- data flow의 representation을 학습하기 위해 사용
- 모델이 “value가 어디에서 왔는지”를 판별하는 structure-aware representation을 학습하기 위함
- data flow의 node 20%를 샘플링하고 해당 node에 연결된 edge를 masking, masked edge를 예측하는 task
- negative sampling

`Node Alignment
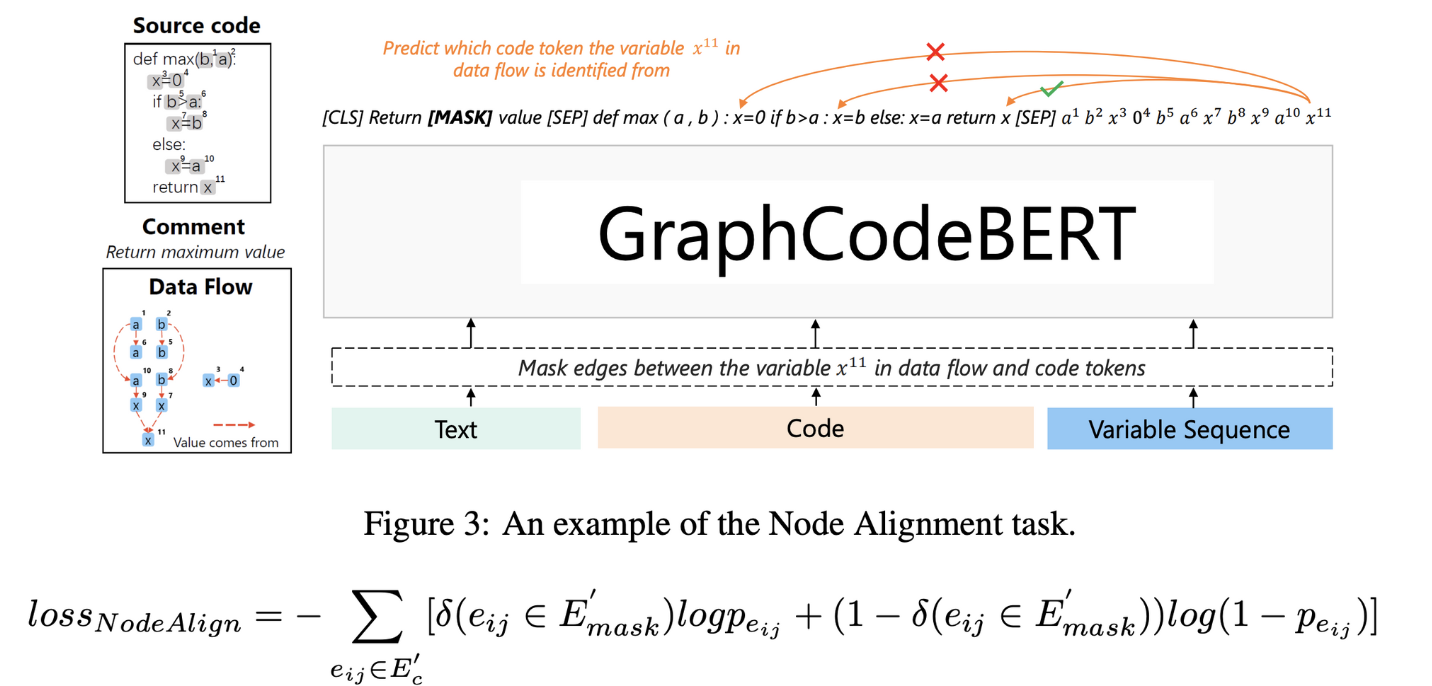
- data flow와 source code의 representation을 맞추기 위해 code token과 nodes의 관계를 예측하는 task
- 20%의 variable node를 샘플링하고 해당 node와 code sample의 edge를 masking하고 predict
4. Experiments

- code search, code clone detection, code translation, code refinement에서 좋은 성능을 기록

- Edge prediction, Node Align, Data flow에 대한 ablation study를 수행하여 모든 프로그래밍 언어에서 모델 디자인이 효과적이었음을 보임

- Code와 Node의 비율에 비해 [CLS] token이 Node에 더 집중하는 것을 보아 data flow가 중요함을 보임

- AST보다 GraphCodeBERT가 여러 sequence length에서 모두 좋은 성능을 기록
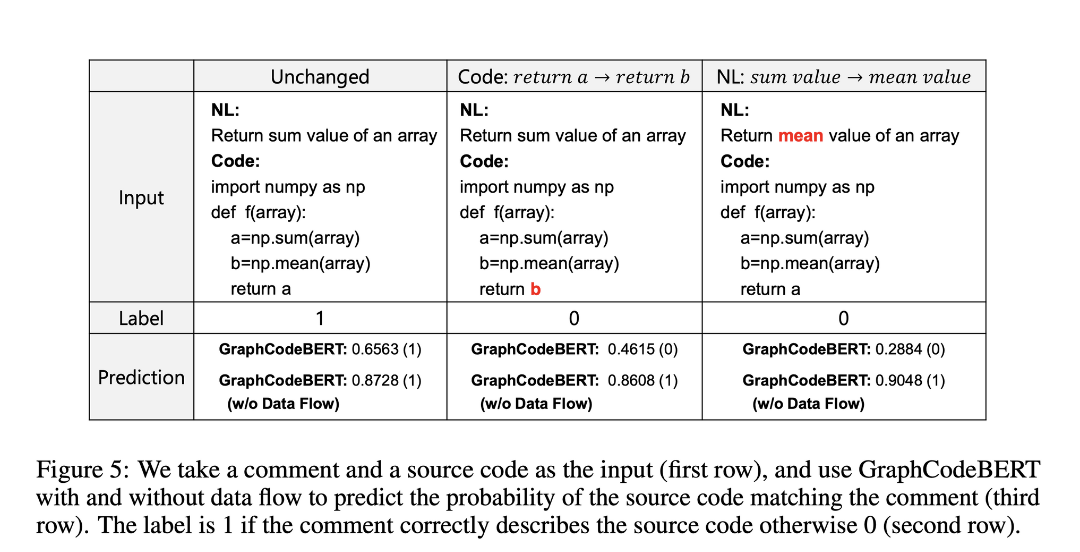
- Data flow를 사용하지 않는 경우 작은 code의 변화에 모델의 output이 크게 달라지지 않음
5. Conclusion
- code representation을 학습하기 위해 data flow를 사용하는 GraphCodeBERT를 제시
- code-structure를 고려한 최초의 pre-trained 모델
- code-structure를 고려한 training objectives 2개를 추가한 GraphCodeBERT는 code search, clone detection, code translation, code refinement에서 SOTA를 달성
후기 & 정리
- code structure를 고려한 training objective, input format을 사용하여 여러 code 관련 downstream task에서 SOTA를 달성한 GraphCodeBERT를 제시한 논문
- CodeBERT에서 후속 연구로 제시한 code-structure aware 모델링을 수행한 후속 논문
- CodeBERT와 마찬가지로 Kaggle AI4Code 대회에 참가할 때 사용했던 모델
- 같은 변수명이 여러번 반복되지만 그 의미가 달라지는 code의 특성을 Graph 구조를 사용하여 잘 모델에 녹여냈다고 생각함
Reference
[0] Daya Guo et al. (2020). "GraphCodeBERT: Pre-training Code Representations with Data Flow ". https://arxiv.org/abs/2009.08366
GraphCodeBERT: Pre-training Code Representations with Data Flow
Pre-trained models for programming language have achieved dramatic empirical improvements on a variety of code-related tasks such as code search, code completion, code summarization, etc. However, existing pre-trained models regard a code snippet as a sequ
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| Few-Shot Unsupervised Image-to-Image Translation (0) | 2022.11.02 |
|---|---|
| FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer (0) | 2022.10.22 |
| CodeBERT:A Pre-Trained Model for Programming and Natural Languages (0) | 2022.08.23 |
| Longformer: The Long-Document Transformer (0) | 2022.07.29 |
| Few-Shot Font Generation by Learning Fine-Grained Local Styles (0) | 2022.07.12 |



