
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 폰트생성
- GAN
- Font Generation
- motion matching
- UE5
- deep learning
- NLP
- userwidget
- 언리얼엔진
- 딥러닝
- animation retargeting
- dl
- WinAPI
- Unreal Engine
- Stat110
- 디퓨전모델
- 생성모델
- Generative Model
- CNN
- cv
- BERT
- ddpm
- WBP
- 오블완
- Diffusion
- RNN
- ue5.4
- multimodal
- 모션매칭
- Few-shot generation
- Today
- Total
Deeper Learning
Few-Shot Unsupervised Image-to-Image Translation 본문
Ming-Yu Liu, Xun Huang, Arun Mallya, Tero Karras, Timo Aila, Jaakko Lehtinen, Jan Kautz, [NVIDIA, Cornell University, Aalto University] (2019.05)
Abstract
- Unsupervised image-to-image(i2i)는 여러 class 간 매핑을 학습하는 방법
- 최근 방법론들은 좋은 성과를 보였으나 학습과정에서 많은 수의 소스, 타깃 이미지를 필요로 하는 문제가 존재
- 인간은 매우 적은 수의 이미지로도 object를 잘 파악하는데에서 영감을 받아 few-shot 연구를 진행
- 저자는 새로운 모델 아키텍처, adversarial 학습 scheme을 함께 사용하여 few-shot generation을 성공
- 여러 실험과 다양한 baseline 방법론과의 비교를 통해 제시한 모델의 효과에 대한 검증을 마침
- https://github.com/NVlabs/FUNIT
GitHub - NVlabs/FUNIT: Translate images to unseen domains in the test time with few example images.
Translate images to unseen domains in the test time with few example images. - GitHub - NVlabs/FUNIT: Translate images to unseen domains in the test time with few example images.
github.com
1. Introduction
- 인간은 처음 보는 동물의 사진을 보고도 다른 pose의 모습을 상상할 수 있을 정도로 generalization에 뛰어남 (알고있던 동물과 비슷한 경우 특히 더)
- 최근 unsupervised i2i 연구는 translation을 위해 모든 classes의 수많은 image 데이터를 필요로 하는 한계가 존재
- 인간과 machine imagination의 능력 차이를 줄이는 시도로 저자는 적은 수의 target class image로도 source class에서 target class로 translation을 가능케 한 Few-shot Unsupervised Image-to-image Translation(FUNIT) 프레임워크를 제시
- 모델은 target class를 학습 과정에서 보지 못하지만 테스트 과정에서 target class의 image를 생성하도록 요구 받음
- 인간의 few-shot generation 능력은 과거의 시각적 경험에서 나온다는 가설을 바탕으로 FUNIT을 학습시킬 때 다양한 class로 구성된 데이터셋을 사용
- 적은 예시 이미지를 보고 다른 class로 translation 시키도록 모델을 학습시킴
- FUNIT은 GAN과 새로 제시한 네트워크 아키텍처로 원하는 few-shot unsupervised i2i translation 능력을 얻는데 성공
- few-shot 이미지 분류 task에서도 기존 feature hallucination을 활용한 방식의 성능을 뛰어넘으며 SOTA를 달성
2. Related Work
Unsupervised/unpaired image-to-image translation
- source class의 input image를 target class의 이미지로 매핑시키는 conditional image generation function을 학습하는 것이 목표
- marginal distributions의 샘플로 joint distribution을 복원하도록 하는 내재적인 ill-posed 문제 존재 (marginal distributions은 real world에서 dependent)
- 위 문제를 해결하기 위해 source data의 pixel values, pixel gradients, semantic features 등을 제약하는 방식, cycle consistence 제약 등의 방식이 연구되었음
- FUNIT은 partially shared latent space 가정을 기반으로 하지만 few-shot unsupervised i2i translation task를 목적으로 하는 것이 차이점
- 현존하는 모델은 2가지 한계가 존재
- sample inefficient
- 학습 과정에서 적은 image로 학습을 하면 translation 성능이 크게 떨어짐
- two classes
- 두 classes 간 translation만 학습이 가능
- 허스키에서 고양이로 translation 하도록 학습한 모델은 허스키에서 호랑이로 translation 하는 모델을 만드는 데 사용할 수 없음
- Benaim and Wolf는 하나의 source class image와 target class images로 데이터셋을 구성하여 sample inefficient 문제를 해결하고자 하였음
Multi-class unsupervised image-to-image translation
- multiple classes로 확장한 개념
- FUNIT은 multiple classes로 training set이 구성된 것은 비슷하지만 unseen target classes로의 translation이라는 측면에서 다름
Few-shot classification
- 최근 meta-learning에 집중하며 새로운 task에서의 성능을 높이기 위한 연구가 진행 중
- training set augmentation을 통해 few-shot classification을 위한 새로운 feature vectors를 얻는 방향 연구 활발
- FUNIT도 few-shot classification에 활용 가능
3. Few-shot Unsupervised Image Translation
- 정해진 source classes에서 images를 뽑아 데이터셋을 구성, paired image를 만들지 않음 (다른 class의 같은 pose 동물 image를 특별하게 뽑지 않음)
- source class images를 multi-class unsupervised i2i translation model을 학습하는 데 사용하고 test에는 새로운 class(target class)의 적은 수의 image를 사용
- 모델은 few target images를 활용하여 source class image를 target class의 image로 translation

- conditional image generator G 와 multi-task adversarial discriminator D 를 사용
- 이전의 unsupervised i2i translation 프레임워크에서 사용하던 generator와 달리 FUNIT의 G 는 content image x 와 특정 class의 K 개의 images {y1,...,yk} 를 input으로 받는다
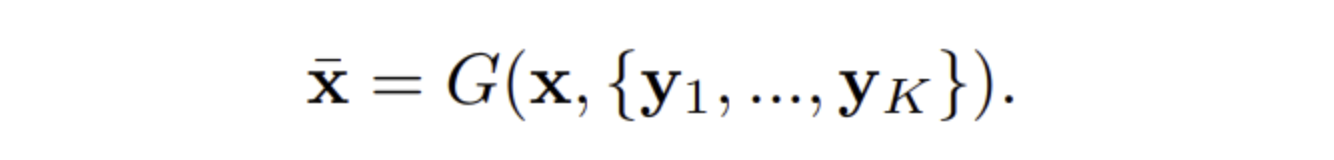
- S,T 는 source classes, target classes의 set
- 학습과정에서 G 는 random sampling된 두 class cx,cy∈S,(cx≠cy) 간 image translation을 학습
- test에서 G 는 unseen target class c∈T 의 images를 class images로 주어 source class의 이미지를 target class로 translation
3.1. Few-shot Image Translator
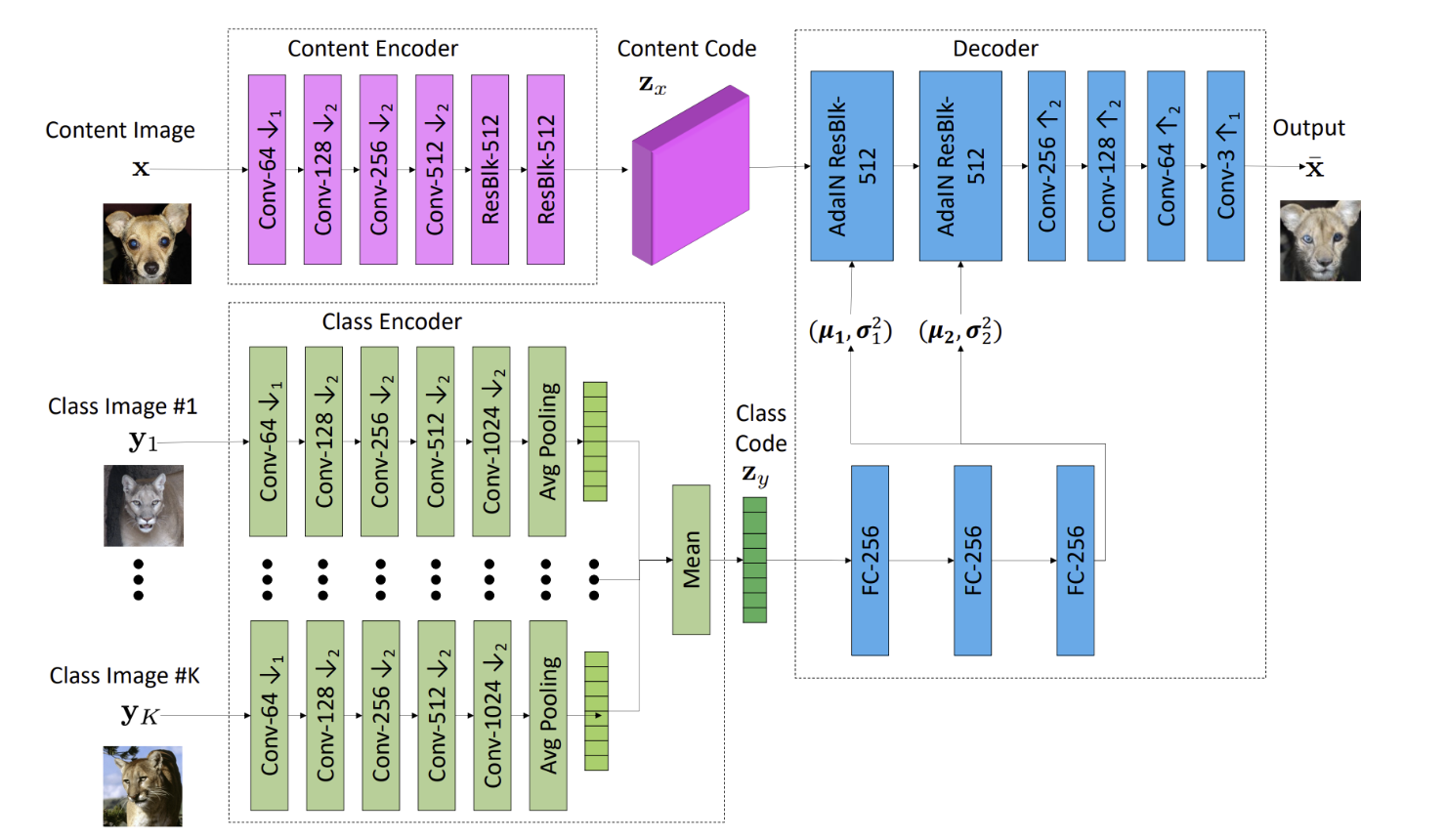
- few-shot image translator G 는 content encoder Ex, class encoder Ey, decoder Fx 로 구성되어 있다
- content encoder는 content image를 content latent code로 매핑하며 class encoder는 K개의 class images를 각각 intermediate latent vector로 매핑한 후 최종 class latent code를 얻기 위해 sample들의 mean을 연산
- decoder는 AdaIN residual blocks, upscale convolution blocks으로 구성되어 있음
- AdaIN의 parameter μ,σ2 는 class code를 2개의 FC layer에 통과시켜 얻으며 이를 사용하여 class code가 global look에 영향을 미치며(외형) content image의 local structure는 유지되도록 함(눈의 위치 등)
- 학습과정에서 본 source object classes의 수에 따라 generalization 성능이 달라지는 것을 발견
3.2. Multi-task Adversarial Discriminator
- D 는 여러 adversarial classification task를 동시에 풀며 학습된다
- source class의 real image인지 G 가 만들어낸 translation image인지 binary classification task 수행
- source classes가 하나가 아니기 때문에 D 는 각 source class의 결과에 대해 예측
- class c의 real image에 대해 D 가 fake image라고 판별하면 penalize
- class c의 generated image에 대해 D 가 real image라고 판별하면 penalize
- G 는 class c의 generated image에 대해 D 가 fake image라고 판별하면 penalize
- S 개의 class를 classification 하는 방식보다 실험적으로 위 방식이 더 잘 작동하였음
3.3. Learning
- minimax optimization problem
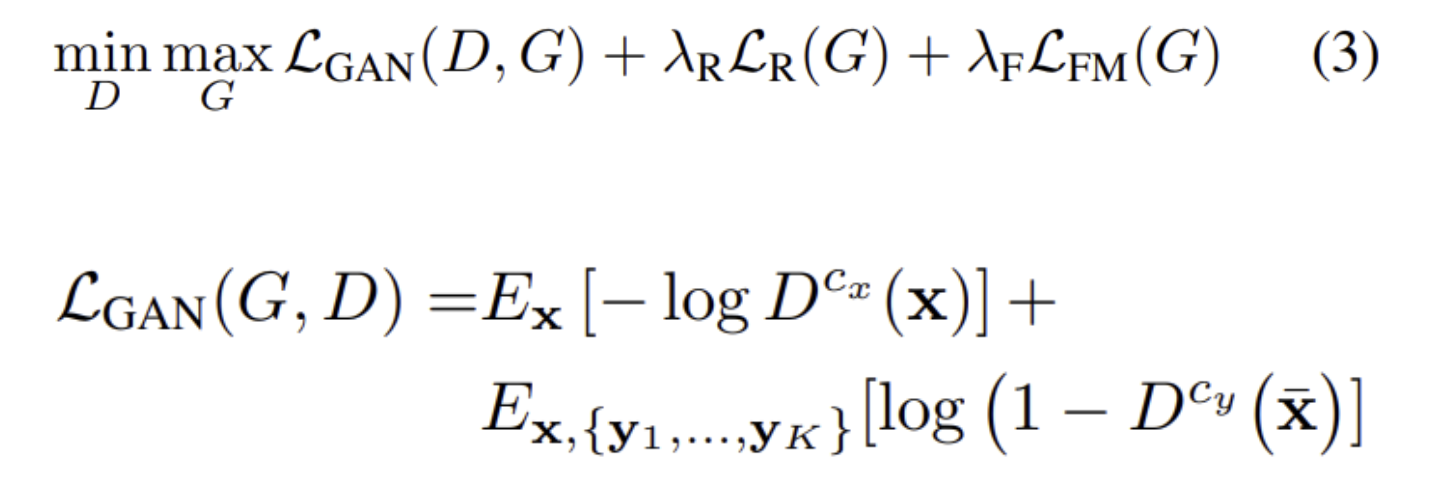
- content reconstruction loss는 G 가 translation을 잘 학습하도록 도와줌
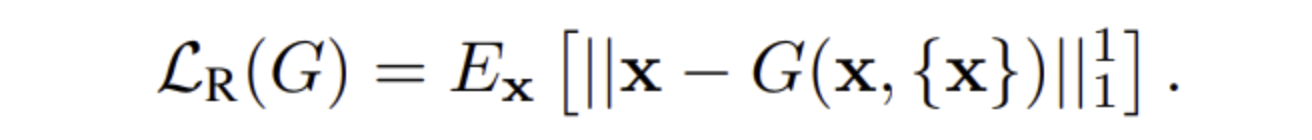
- feature matching loss는 학습을 regularize, Df 는 D 에서 last prediction layer를 제거한 구조

- 해당 loss들은 모두 기존에 사용되던 loss들
- 저자는 본 논문의 contribution은 기존에 제시된 objective들을 더 어렵고 새로운 few-shot unsupervised i2i translation setting에 적용한 것이라고 언급
4. Experiments
- λR=0.1,λF=1
- RMSProp, lr=0.0001, hinge GAN loss 사용
- real gradient penalty regularization 사용
- K = 1, 5, 10, 15, 20으로 각각 학습, 64 content images를 한 batch로
- ImageNet에서 샘플링한 Animal Face dataset을 만들고 학습에 사용, Birds, Flowers, Foods 데이터 사용
- StarGAN baseline 두 버전으로 만들어 성능 비교
- StarGAN-Fair-K: target class의 images를 학습과정에서 FUNIT과 동일하게 보지 못하도록 세팅
- StarGAN-Unfair-K: target class의 images가 학습 데이터에 포함된 세팅
- Metrics
- Translation accuracy: InceptionV3 classifier 두 개(모든 class 학습, target class만 학습)을 사용하여 결과가 target class에 속하는지 측정
- Content preservation: VGG Conv5 features의 L2 distance를 비교, domain-invariant perceptual distance (DIPD) 측정
- Photorealism: inception scores(IS)
- Distribution matching: target object classes 각각의 평균 Frechet Inception Distance (FID)
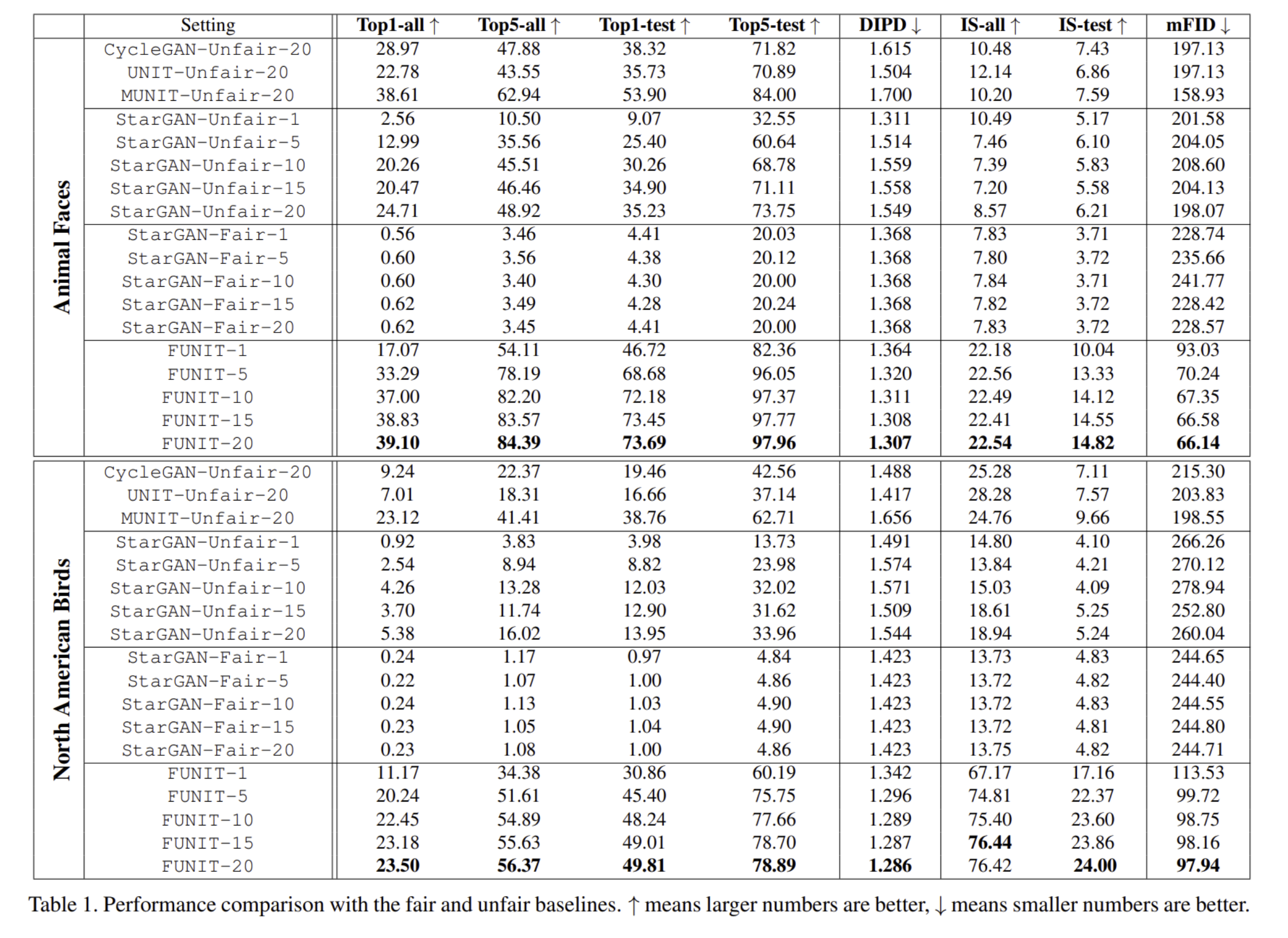

- [Table 1]을 보면 FUNIT은 다른 few-shot unsupervised image-to-image translation baseline의 성능을 뛰어넘은 것을 알 수 있음
- K=5인 few-shot 조건에서 FUNIT은 다른 Unfair 세팅 베이스라인을 뛰어넘는 성능을 보여줌
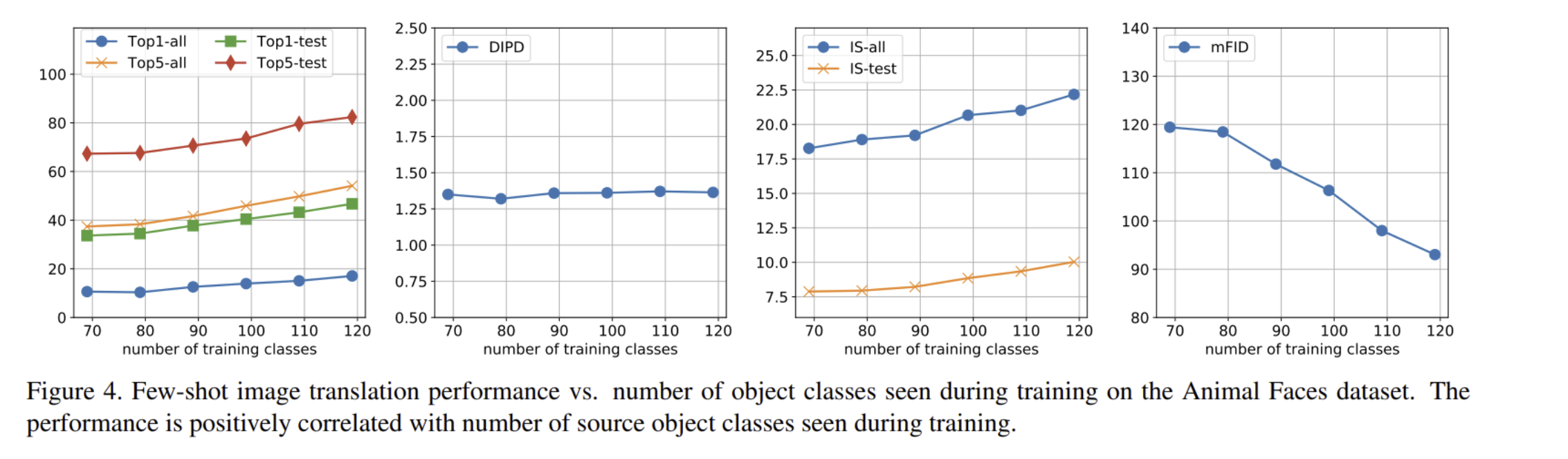
- Training classes 수가 많아지면 가설대로 더 좋은 성능을 보임
- FUNIT generated images를 활용하여 classifier를 학습하였더니 기존 방법론들 성능을 뛰어넘음
5. Discussion and Future Work
- 처음으로 few-shot unsupervised i2i translation framework를 제시
- target class에 속한 image 수, 학습 과정에서 class 수가 증가함에 따라 생성 결과물의 퀄리티가 좋아지는 것을 보임
- 새로운 class가 source class와 매우 다른 외형을 가질 경우 translation에 실패하고 단순하게 color를 옮김, 이를 해결하는 것을 Future work으로 제시
후기 & 정리
- few-shot unsupervised i2i translation framework FUNIT을 제시
- target class의 데이터가 부족한 few-shot 상황에서 성공적으로 translation, 데이터가 많아지면 그에 따라 결과물의 퀄리티가 향상됨을 보임
- 직관적인 모델 구조와 학습 방식
- K=5인 few-shot condition에서 target class의 정보를 가지고 있는 Unfair 세팅 baseline 모델보다 좋은 성능을 보여줌
- 목적에 맞는 아키텍처 설계, 학습방식이 매우 중요함
Reference
[0] Ming-Yu Lie et al. (2019). "Few-Shot Unsupervised Image-to-Image Translation". https://arxiv.org/abs/1905.01723
Few-Shot Unsupervised Image-to-Image Translation
Unsupervised image-to-image translation methods learn to map images in a given class to an analogous image in a different class, drawing on unstructured (non-registered) datasets of images. While remarkably successful, current methods require access to man
arxiv.org



