
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Generative Model
- 폰트생성
- RNN
- 디퓨전모델
- cv
- WinAPI
- Few-shot generation
- Unreal Engine
- ue5.4
- BERT
- 모션매칭
- ddpm
- GAN
- 생성모델
- animation retargeting
- userwidget
- NLP
- multimodal
- 오블완
- WBP
- Stat110
- motion matching
- Diffusion
- 딥러닝
- deep learning
- Font Generation
- UE5
- 언리얼엔진
- dl
- CNN
Archives
- Today
- Total
Deeper Learning
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer 본문
AI/Deep Learning
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformer
Dlaiml 2022. 10. 22. 15:18Yitian Liu, Zhouhui Lian, [Wangxuan Institute of Computer Technology, Peking University, Beijing, China] (2022.10.13)
Abstract
- 적은 데이터로 고품질의 중국어 폰트를 생성해내는 것은 어려운 일이며 현존하는 few-shot 폰트 생성 방식은 low-resolution의 획이 끊기는 폰트를 만드는데 그쳤다
- 이러한 문제를 해결하기 위해 본 논문은 고품질의 few-shot 생성이 가능한 FontTransformer를 제시
- key idea는 prediction error가 쌓이는 것을 피하기 위한 parallel Transformer, 생성된 획의 퀄리티를 높이기 위한 serial Transformer의 사용
- 실제 같은 고품질의 글자를 생성하기 위해서 input 글자의 정보를 최대한 활용하기 위한 encoding 방식 제시
1. Introduction
- 다양한 스타일의 고품질 폰트 수요는 증가하고 있으나 시간과 인력이 많이 드는 폰트 제작과정은 이 수요를 감당할 수 없음
- 딥러닝 베이스의 폰트 생성 방법론이 여럿 제시되었으나 퀄리티가 좋지 않음
- 중국어 폰트는 연속되는 획으로 이루어져 있기 때문에 이를 연속된 정보로 처리할 필요가 있음
- 이전 방식들은 글자 이미지를 연속된 정보로 보지 않았기 때문에 깔끔하지 못한 경계선과 획이 망가지는 문제가 존재하였음
- 위 문제를 해결한 새로운 few-shot 폰트 생성 모델인 FontTransformer를 제시

- Parallel Transformer에서 style transfer, Serial Transformer에서 Refinement가 이루어짐
- 메모리의 한계로 이전 폰트 생성 딥러닝은 주로 256x256의 이미지를 사용하였으나 본 논문에서는 glyph 이미지는 반복되는 패턴을 가지는 패치로 구성되었다는 점을 이용한 chunked glyph image encoding을 사용하여 1024x1024의 이미지를 생성
- 주요 contributions
- 1024x1024 글자 이미지를 생성 가능하며 Transformer를 폰트 생성에 최초로 사용한 사용한 중국어 폰트 생성 모델 FontTransformer를 제시
- 글자 이미지를 token sequences로 인코딩하는 chunked glyph image encoding을 사용하여 메모리의 제약이 적어지고 고화질의 이미지 생성 가능
- 적은 input samples로도 퀄리티 좋은 글자 이미지를 생성한 few-shot font generation SOTA 모델
2. Method Description
- 첫 스테이지에서는 image patches를 생성하기 위해 Parallel Transformer를 사용, 다음 스테이지에서는 부드러운 경계선을 만들기 위해 Serial Transformer를 사용
- 각 스테이지에서는 glyph image를 sequence로 인코딩하고 style, content, wubi embedding을 sequence에 추가
2.1. Chunked Glyph Image Encoding
- 다른 vision Transformer의 방식처럼 FontTransformer에서도 글자 이미지를 sequence로 encoding 하고 input으로 feed
- binary bitmap인 폰트의 patch는 자주 반복되는 패턴으로 구성되기 때문에 ViT나 VQGAN에서와 같이 복잡한 매핑을 학습하기 위한 Linear Projection을 사용하지 않아도 전체 글자 이미지를 표현하는 compact sequence를 만들 수 있음
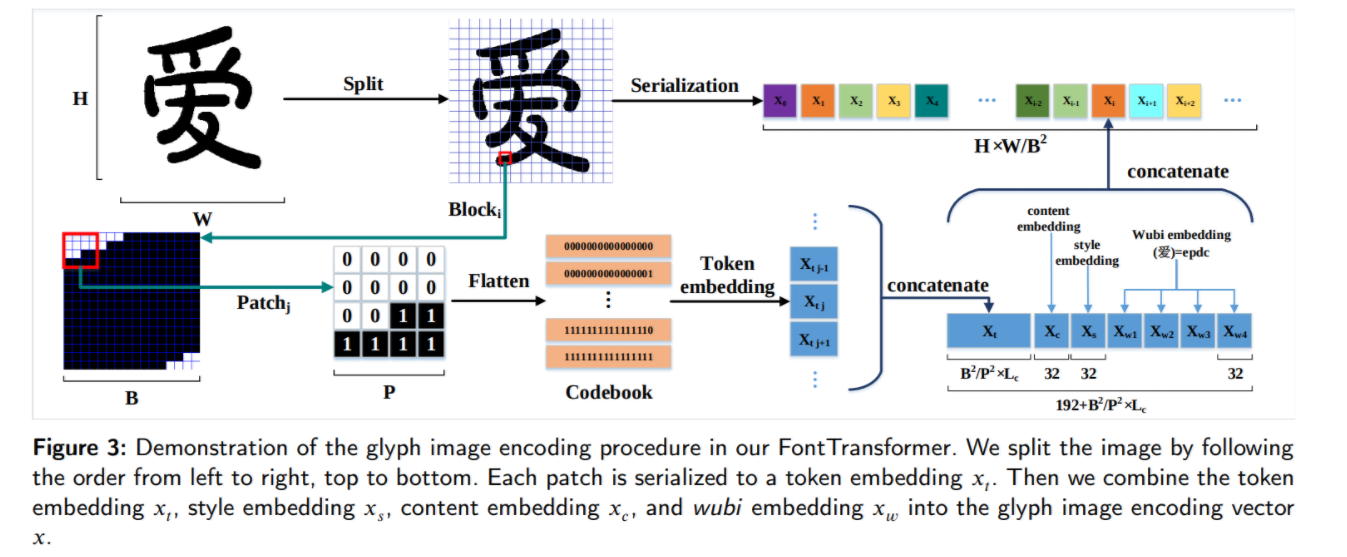
- sequence의 길이를 줄이기 위해 저자는 chunked glyph image encoding을 제시
- single-channel 2D glyph image I∈{0,1}H×W 를 flattened blocks sequence L={Ib1,...,IbN|Ibi∈{0,1}B2} 로 reshape (block의 크기는 B x B, Image의 크기는 H x W)
- 그 후 각 blocks Ib∈{0,1}B2을 크기가 P x P인 patch (B^2 / P^2)개로 다시 나눔 (Figure 3 참고)
- (P x P) 크기의 patch를 flatten하고 각 patch를 binary number로 표현, b∈[0,2P2−1]
- 총 2P2 개의 코드북 key값이 만들어지는데 각 key에 대응하는 value는 standard normal distribution N(0,1) 에서 샘플링한 Lc dimension의 벡터
- Block내의 Patches를 Codebook을 사용하여 모두 embedding vector로 치환하고 이를 concat하여 Xt 벡터 생성 (Figure 3 참고)
- B,P,Lc 를 조정하여 임의의 high-resolution 글자 이미지를 정해진 token length, codebook size에 인코딩이 가능
- 높은 퀄리티의 글자 이미지 생성을 위해 encoding 모듈에 content embedding, style embedding 정보를 추가로 제공
- 중국어 글자의 구조에 따른 labeling 방식인 wubi coding method를 활용하여 만든 wubi embedding을 추가로 제공
2.2. FontTransformer
Stacked Transformer
- Transformer의 Decoder는 순차적으로 token을 생성하기 때문에 추론 시 error가 쌓여서 문제가 발생
- 위 문제로 인해 모델은 복잡흔 구조의 글자 이미지를 생성할 때 잘못된 topological structure. 미완성된 획을 가지는 결과물을 만들게 됨
- 첫 patches의 획을 생성하는데 실패하면 이어진 전체 획을 생성하지 못하는 문제 존재
- 이를 해결하기 위해 parallel Transformer Tp, serial Transformer Ts 를 사용
- parallel Transformer는 decoder에 시작 token을 입력하고 순차적으로 token을 생성하며 붙여나가는 Transformer의 방식이 아닌 Informer의 Generative Inference 방식을 따름 (아래 Informer 모델 구조 참고)
- Generative Inference는 input sequence에서 샘플링한 long sequence tokens와 target으로 하는 sequence가 들어가는 자리를 채울 tokens을 concat하여 input으로 사용
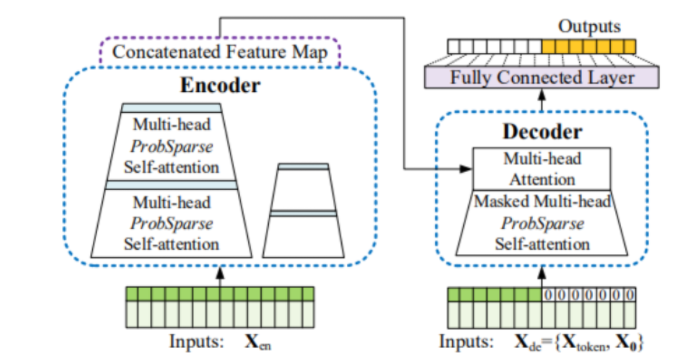
- source glyph image sequence Seq_source, reference glyph image sequence Seq_ref, blank glyph image sequence Seq_blank는 decoder에 input으로 주어진다
- glyph image encoding에 style, content, wubi embedding이 있기 때문에 Seq_blank를 Seq_ref 대신 제공한다
- serial Transformer는 생성 결과의 퀄리티를 높이기 위한 Transformer로 구조는 parallel Transformer와 거의 동일
Masked Attention
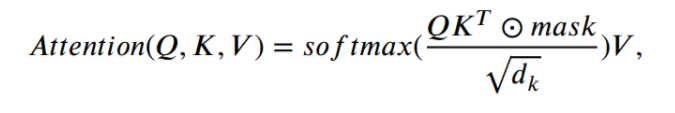
- 필요 없는 정보를 배제하기 위해 Masked Attention 사용
- patch 내부의 값이 모두 0인 blank patches는 글자 이미지에서 전체 pathces의 절반 이상을 차지
- blank patch의 경우 0, 나머지는 1의 값을 사용한 masking을 통해 정보가 거의 없는 patch를 학습에 활용하지 않음
Loss function
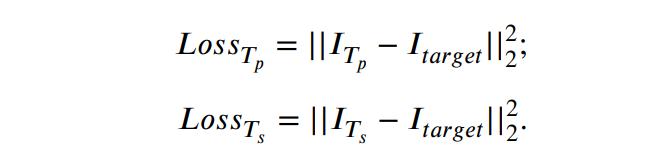
- 폰트 생성에서 많이 활용하는 perceptual loss, contextual loss를 사용해보았으나 결과에 차이가 없어 MSE loss만을 사용
- parallel Transformer, Serial Transformer의 생성 결과와 Ground Truth를 사용하여 loss 계산
3. Experiments
3.1. Dataset and Competitors
- 제시한 FontTransformer를 zi2zi, EMD, DG-Font, AGIS-Net, MX-Font와 비교
- 평가를 위해 6763개의 글자로 구성된 300개 폰트의 데이터셋을 구성, Arial Regular를 source font로 사용
3.2. Implementation Details
- 16x16 block size, 256 tokens
- Adam, beta1 = 0.9, beta2 = 0.98, learning rate = 1e-4
- token dim = 448, batch size = 64, 10 epoch pre-train, 100 epoch fine-tuning
3.3. Metrics
- MAE, FID
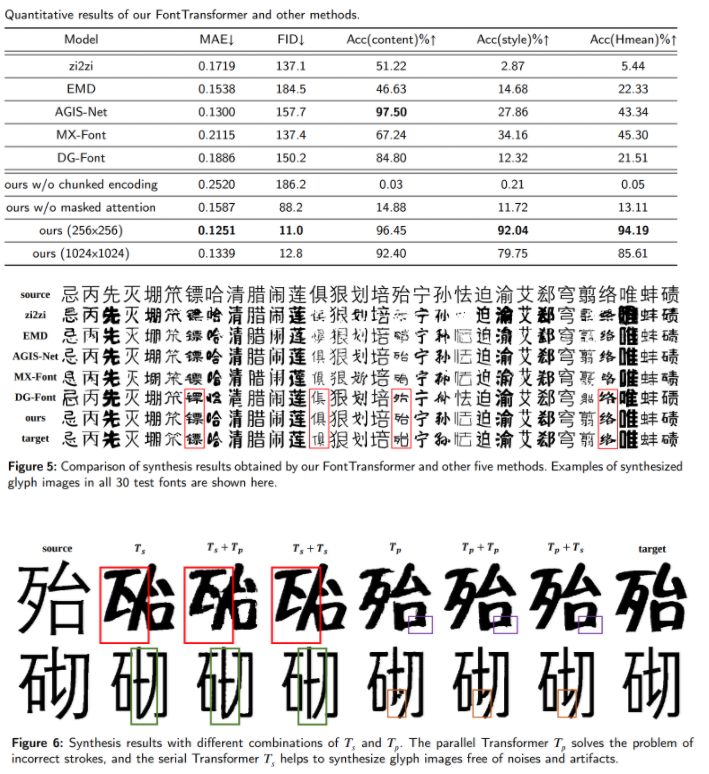
3.4. Ablation Study

3.5. Failure Cases

4. Conclusion and Future Work
- novel end-to-end few-shot Chinese font synthesis method, FontTransformer 제시
- stacked Transformer를 사용하여 부드러운 획, 알맞은 구조를 갖춘 high-resolution 글자 이미지를 생성이 가능
- 후속 연구로는 Transformer의 복잡도를 줄이며 생성 결과의 품질을 유지하는 것을 제시
후기 & 정리
- stacked Transformer를 활용하여 효율적으로 고화질의, 고품질의 글자 이미지를 생성하는 FontTransformer를 제시
- 기존 few-shot 폰트 생성 논문들과 다르게 1024x1024의 이미지를 생성 가능
- Font domain에 적합한 Codebook을 구성하는 방식 제시
- 동일 component를 사용하는 글자들 사이의 일관성 유지와 계산복잡도 감소가 다음 과제로 보임
Reference
[0] Yitian Liu, et al. (2022). "FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformers". https://arxiv.org/abs/2210.06301
FontTransformer: Few-shot High-resolution Chinese Glyph Image Synthesis via Stacked Transformers
Automatic generation of high-quality Chinese fonts from a few online training samples is a challenging task, especially when the amount of samples is very small. Existing few-shot font generation methods can only synthesize low-resolution glyph images that
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| CLIP: Learning Transferable Visual Models From Natural Language Supervision (0) | 2022.11.04 |
|---|---|
| Few-Shot Unsupervised Image-to-Image Translation (0) | 2022.11.02 |
| GraphCodeBERT: Pre-training Code Representations with Data Flow (0) | 2022.08.26 |
| CodeBERT:A Pre-Trained Model for Programming and Natural Languages (0) | 2022.08.23 |
| Longformer: The Long-Document Transformer (0) | 2022.07.29 |
'AI/Deep Learning' Related Articles
more



