
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Font Generation
- CNN
- Few-shot generation
- deep learning
- multimodal
- WBP
- 모션매칭
- BERT
- Diffusion
- userwidget
- Unreal Engine
- Stat110
- GAN
- motion matching
- ue5.4
- Generative Model
- WinAPI
- 디퓨전모델
- 폰트생성
- RNN
- ddpm
- dl
- 오블완
- animation retargeting
- 언리얼엔진
- NLP
- 딥러닝
- 생성모델
- UE5
- cv
Archives
- Today
- Total
Deeper Learning
Zero-Shot Text-to-Image Generation 본문
Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever (2021.02)

Abstract
- Text-to-Image(이하 TTI) generation은 고정된 데이터셋을 학습하기 위한 더 좋은 모델링 가정을 찾는 방향으로 연구가 집중되었음
- 이러한 가정은 복잡한 아키텍처, auxiliary loss 그리고 object part labels, segmentation mask와 같은 side information을 수반
- 하지만 저자는 text와 image token을 하나의 stream으로 처리하여 transformer-based 아키텍처로 autoregressive하게 처리하는 간단한 방식으로 TTI 접근
- 저자가 제시한 방식은 충분한 데이터와 scale이 주어지면 zero-shot 기준 기존 domain-specific 모델과 비슷한 성능을 보임
1. Introduction
- TTI에 대한 연구는 GAN, energy-based, MS-COCO 데이터 추가, cross-modal masked language 학습 등 여러 접근 방식이 존재했으나 가장 뛰어난 성능을 보이는 방법론도 심각한 아티팩트(일그러지는 물체, 앞뒤 물체의 혼합, 잘못된 물체 위치)가 발생
- autoregressive transformer의 모델 사이즈, 데이터를 잘 scale up하는것은 최근 text, image, audio 도메인에서 많은 성과를 기록
- 하지만 TTI는 여전히 MS-COCO, CUB-200과 같은 작은 데이터셋을 사용, 저자는 모델 사이즈, 데이터셋 사이즈가 성능을 제한하는 요인이라고 생각
- 본 논문은 12-billion parameter autoregressive transformer와 인터넷에서 수집한 250 million image-text pair data를 사용하여 natural language로 컨트롤이 가능한 high-fidelity 이미지 생성모델의 학습이 가능하다는 것을 증명
- training labels 없이 zero-shot으로 MS-COCO에서 고품질 이미지 생성에 성공
- 기초적인 단계의 image-image translation도 가능
2. Method
- text와 image token을 하나의 stream으로 만드는것이 목표이나 image pixel을 그대로 tokens으로 사용하기에는 고화질의 이미지를 감당할 수 없음
- Pixelcnn 논문에서 Likelihood objective가 픽셀 간 short-range dependencies를 모델링하는 경향이 있다는 것을 밝힘
- Likelihood objective의 문제는 model의 capacity의 대부분이 인간이 물체를 인식하는데 중요한 low-frequency structure를 학습하는 데 쓰이지 않고 high-frequency detail을 학습하는데 사용되는 것
- 저자는 위 문제를 2-Stage 학습 방식을 통해 해결
- Stage 1
- 256x256 RGB image를 32x32 grid image tokens(단일 image token은 8192 code중 1개)으로 압축시키는 discrete variational autoencoder(dVAE)를 학습
- 이는 visual quality에 큰 degradation없이 transformer의 context size를 192(256x256x3 → 32x32)배 줄임(아래 사진은 dVAE 압축 이미지 비교)
- Stage 2
- 256 BPE-encoded text를 1024 image tokens과 concat하고 autoregressive transformer를 사용하여 image-text joint distribution을 학습
- 전체 학습과정은 image x, captions y, encoded image tokens z의 joint likelihood에 대한 maximizing evidence lower bound(ELB)로 볼 수 있음
- 구하고자 하는 것을 factorization y,z로 factorization한 아래식에서 ELB 산출 (수식 전개는 VAE와 유사, 후에 수식 비교 중점으로 포스팅 예정)
pθ,ψ(x,y,z)=pθ(x|y,z)pψ(y,z)
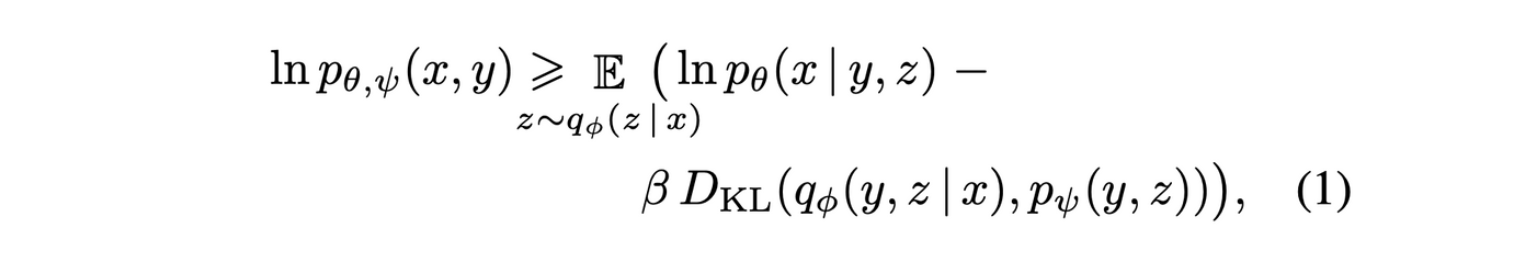
- $q_{\phi}$는 dVAE encoder가 만든 32x32 image token의 분포
- $p_{\theta}$는 dVAE decoder가 생성한 RGB images 분포
- $p_{\psi}$는 transformer가 모델링하는 text, image tokens joint distribution
- β는 1이어야 수식이 성립하지만 실험적으로 더 큰 값이 효과적
2.1. Stage One: Learning the Visual Codebook
- 우선 ϕ,θ (dVAE encoder, decoder parameter)에 대해 ELB를 maximize하기 위해 dVAE 단독학습
- initial prior pψ를 K=8192 codebook vectors에 대한 uniform categorical distribution로 설정
- qϕ는 encoder의 32x32 grid output의 spatial position별 8192 logits에 따라 parameterize되는 categorical distribution으로 설정
- qϕ가 discrete하기 때문에 reparameterization gradient를 사용 불가능
- gumble-softmax relaxation을 사용하여 해결 (qϕ 에 대한 expectation을 1qτϕ로 대체)
- Adam optimizer로 relaxed ELB maximize, 안정적인 학습을 위한 설정
- relaxation temperature τ를 1/16으로 annealing
- encoder의 끝, decoder의 시작 부분에 1x1 conv
- resblock activation에 작은 상수 곱하기
- KL weight β를 6.6으로 설정하면 codebook 활용도가 늘고 reconstruction error가 감소
2.2. Stage Two: Learning the Prior
- ϕ,θ를 고정하고 ψ에 대해 ELB를 최대화하여 text, image tokens의 prior를 학습
- pψ는 12-billion parameter sparse Transformer에 의해 표현됨
- text-image pair에서 caption은 vocab size 16384, 최대 256 tokens으로 BPE-encoding, image는 vocab size 8192(codebook), 32x32=1024 tokens encoding
- image tokens은 dVAE encoder logits에서 gumbel noise를 추가하지 않고 argmax sampling
- Stage 1에서 이미 dVAE parameter를 학습을 마치고 fix 하기 때문에 gradient가 흐를 필요가 없기 때문
- encoding된 text, image tokens을 concat하여 single stream으로 구성
- Transformer는 decoder-only model로 image tokens은 모든 text tokens에 attend
- text-to-text attention은 Transformer decoder의 기본 masking인 causal mask 사용
- image-to-image attention은 row, column, convolution mask 사용 가능
- 저자는 text-to-text, image-to-text, image-to-image의 masking 방식을 적절하게 하나로 통일하는 것이 더 성능이 좋았다고 함

- text tokens padding에 -inf의 logit을 적용하여 무시하는 대신 256 text position에 따라 각기 다른 special padding token을 추가
- validation loss는 증가하였으나, out-of-distribution caption에 대해서 더 좋은 결과를 보여줌
- image modeling이 중심이기 때문에 text CE loss에는 1/8을 곱하고 image CE loss에는 7/8을 곱함
2.3. Data Collection
- 250 million text-images pairs를 수집 + Conceptual Captions + subset of YFCC100M으로 데이터셋 구성
2.4. Mixed-Precision Training
- GPU memory 절약, throughput 증가를 위해 16-bit precision parameter(Adam moments, activations) 사용
- underflow를 피하며 large scale 모델을 16-bit precision으로 학습시키는 것이 매우 어려웠음
- Appendix D에 여러 팁들을 기록
- resblock에서 activation의 gradient norm이 일정하게 뒤쪽 layer로 갈수록 감소하다가 16-bit로 표현할 수 있는 범위를 벗어나 문제가 발생
- resblock마다 gradient scale
2.5. Distributed Optimization
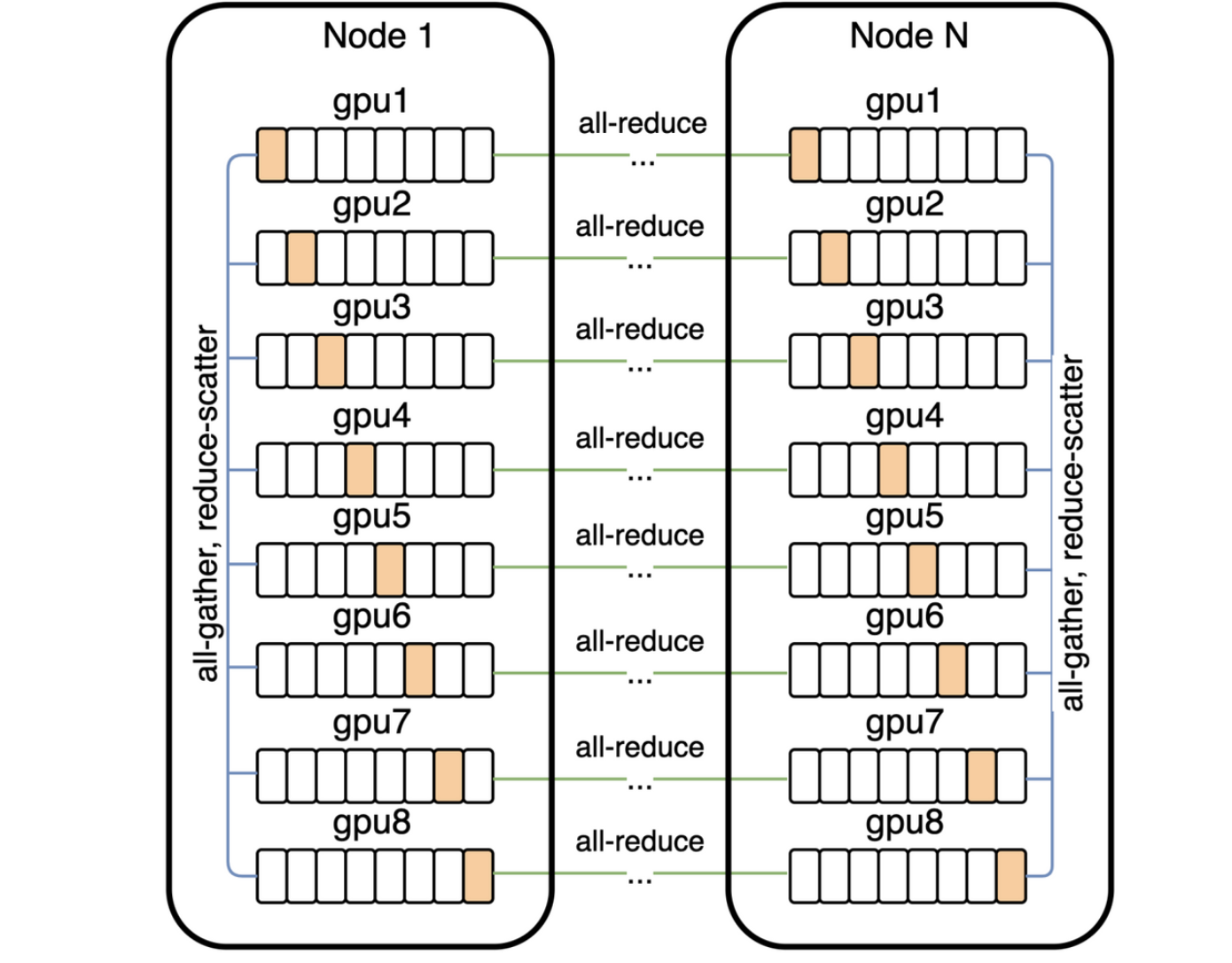
- 24GB의 메모리가 필요한 모델을 16GB의 V100에서 학습시키기 위해 parameter sharding 사용하여 intra-machine 통신 latency를 줄임
2.6. Sample Generation
- CLIP을 사용하여 생성된 이미지가 얼마나 caption과 일치하는지 측정하고 샘플링
- 여러 후보 이미지를 뽑고 가장 좋은 결과를 선정하는 것이 더 퀄리티가 좋음


3. Experiments
- 약 93%의 실험자가 MS-COCO에서 FID, IS 기준 SOTA인 DF-GAN보다 본 논문의 모델의 결과에 높은 점수를 매김
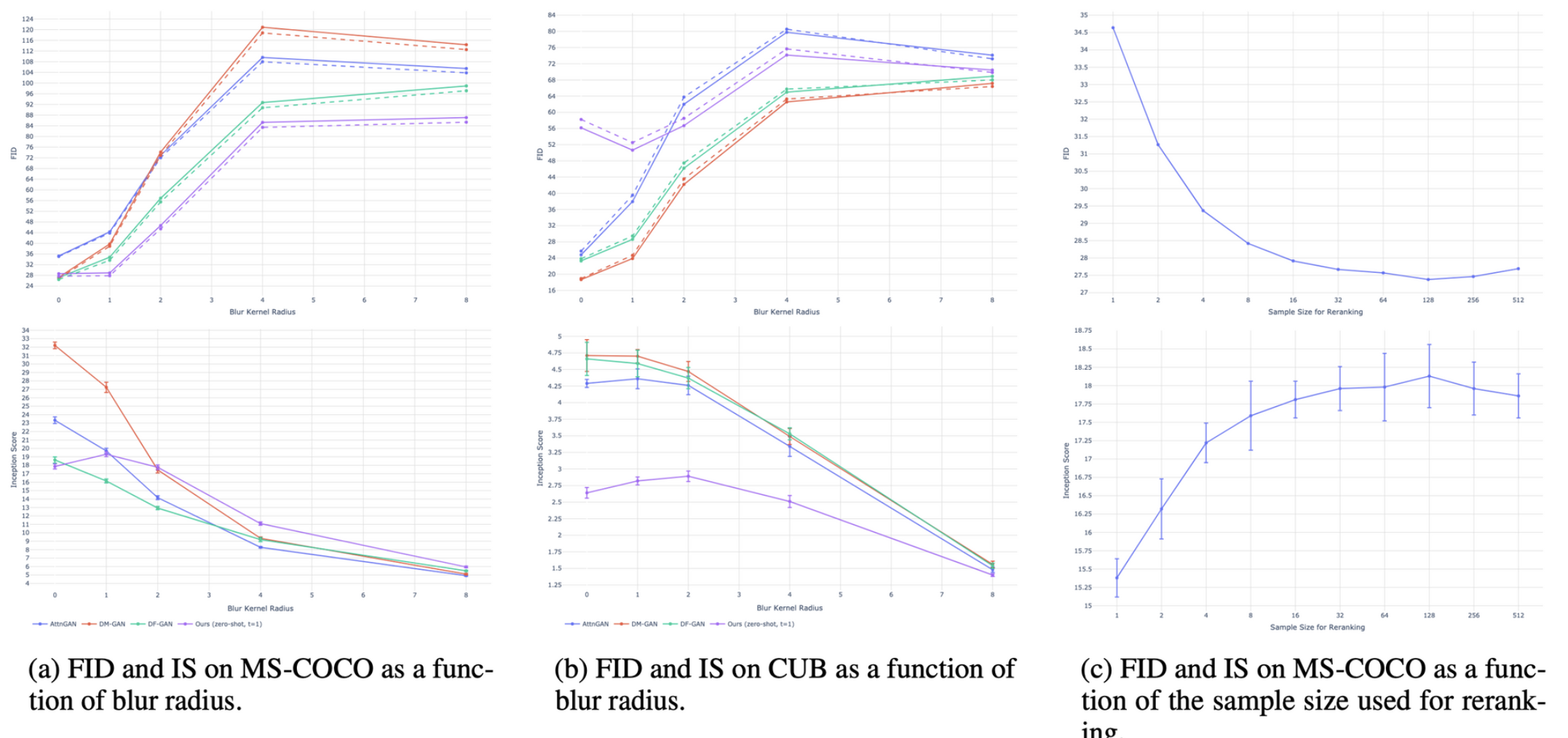
- MS-COCO에서 점선은 학습 데이터에 포함되는 검증 데이터를 제외한 수치
- image compression 과정에서 high-frequency detail을 살리지 못해 불리함이 있기 때문에 Blur kernel을 적용하고 결과를 비교
- blur kernel을 적용하여 image compression 불리함이 해소되면 다른 기존 모델보다 zero-shot임에도 가장 좋은 FID, IS score를 보임
- 하지만 CUB(새) 데이터셋과 같이 특이한 분포에서는 다른 모델보다 성능이 떨어지는데 저자는 fine-tuning으로 이를 해결할 수 있다고 하였고 이를 future-work으로 제시
- CLIP에게 많은 candidates를 주고 가장 좋은 결과를 뽑으면 성능이 향상(32개 까지 FID, IS 상승)
4. Conclusion
- autoregressive transformer 기반으로 text-to-image generation에 대한 간단한 접근법을 연구
- model, data scale up이 zero-shot, 단일 generative model 관점에서 일반화 성능을 향상시킴
후기&정리
- 작년 DALL-E가 생성한 아보카도 체어를 보고 신기해서 간단하게 모델 아키텍처와 학습 방식만 찾아보았는데 이제야 논문 정독 완료
- text-to-image generation도 역시 large scale 통한다는 것을 보여준 논문
- 생성 결과가 실제로 모델이 캡션의 의미를 이해하고 그리는 것 같아 놀라움
- 16-bit precision, distributed optimization 등 large scale 모델 학습을 위한 여러 시도들이 Appendix에 잘 기록되어있음
- 전체 학습방식 + 모델 아키텍처를 보여주는 Figure가 없어서 아쉬움
Reference
[0] Aditya Ramesh et al. (2021). “Zero-Shot Text-to-Image Generation”. https://arxiv.org/abs/2102.12092
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more




Comments