
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- UE5
- Diffusion
- BERT
- Font Generation
- CNN
- NLP
- 딥러닝
- Unreal Engine
- Stat110
- RNN
- Generative Model
- 생성모델
- motion matching
- cv
- GAN
- 모션매칭
- ue5.4
- deep learning
- Few-shot generation
- 언리얼엔진
- animation retargeting
- WinAPI
- userwidget
- 디퓨전모델
- WBP
- ddpm
- multimodal
- dl
- 오블완
- 폰트생성
- Today
- Total
Deeper Learning
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding 본문
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
Dlaiml 2022. 12. 6. 21:46Jinshan Zeng, Yefei Wang, Qi Chen, Yunxin Liu, Mingwen Wang, and Yuan Yao, (2022.11)
Abstract
- 현재 중국어 폰트 생성의 주류 방식은 GAN 기반 모델, 하지만 GAN 기반 모델은 mode collapse 문제를 겪고 있음
- 이 문제를 해결하기 위해 one-bit stroke encoding과 few-shot semi-supervised scheme으로 local, global structure 정보를 찾아내는 방식을 제시
- 해당 아이디어를 기반으로 본 논문은 stroke encoding과 few-shot semi-supervised scheme을 CycleGAN과 결합하여 mode collapse 문제를 완화한 StrokeGAN+를 제시
- 4개의 metric에서 기존 방법론을 뛰어넘는 성능을 보이며 SOTA 달성
1. Introduction
- 중국어 폰트 생성은 최근 개인 폰트 디자인, 캘리그래피 폰트 생성 등 여러 방면에 활용된다는 점에서 많은 주목을 받았다
- 이전 연구들은 auto-encoder guided GAN 모델을 사용하여 폰트 생성을 img-to-img translation 문제로 정의하여 supervised 태스크로 접근
- CalliGAN은 보조 네트워크 모듈을 추가하여 component 정보와 stroke 정보를 뽑아내고 이를 활용
- 최근 Se-gan에서는 stroke 정보를 GAN 기반 image translation에 활용
- paired data를 활용하는 방식의 경우 성능이 뛰어나나 pair data를 모을 수 없는 상황이 존재
- 따라서 unpaired data를 활용하는 폰트 생성 방식이 연구되었으나 mode collapse 문제를 겪고 있음

- SQ-GAN은 간단한 square-block geometric transformation을 사용하여 CycleGAN이 간단한 spatial structure를 잡아낼 수 있도록 하였으나 위 Fig.1에서 볼 수 있듯이 global structure를 잡아내지 못하는 문제가 존재
- 위 그림을 보면 local, global structure는 stroke, paired data에서 대응되는 문자와 관련되어 있음을 알 수 있음
- 아래 두 질문을 통해 mode collapse를 완화시키는 효과적인 전략을 제시하는 것이 본 연구의 목적
- Stroke 정보의 활용이 mode collapse를 완화시키는가?
- few-shot paired data의 활용이 모델 성능을 더 향상시키는가?
- 중국어 글자가 32개의 basic stroke로 구성되어 있기 때문에 단순한 32차원의 one-bit stroke encoding으로 local information을 표현 가능
- 하지만 같은 stroke encoding을 사용하더라도 다른 spatial structure를 가진 글자가 존재하기 때문에 적은 paired data를 few-shot semi-supervised 정보로 활용하여 global structure를 추출
- 모델이 local, global structure 정보를 학습할 수 있도록 stroke reconstruction loss와 few-shot semi-supervised(FS3) loss를 사용
- 저자가 제시한 contributions
- CycleGAN에 local, global structure 정보를 추가로 제공하여 mode collapse를 완화한 중국어 폰트 생성모델 StrokeGAN+을 제시
- 모델의 효율성을 검증하기 위한 여러 실험
- unpair data 기반 베이스라인에 본 논문에서 제시한 아이디어를 추가하여 성능 향상에 성공
2. Proposed Model
2.1. Stroke Encoding and Few-shot Semi-supervised
Scheme
- 효과적인 supervision 정보가 없어 CycleGAN 기반 모델이 mode collapse를 겪는데 stroke 정보를 supervision 정보로 활용 가능
- 같은 stroke encoding을 사용하더라도 다른 spatial structure를 가진 글자가 존재하기 때문에 적은 paired data를 few-shot semi-supervised 정보로 활용하여 global structure를 추출
2.2. Model Architecture and Training Loss
- CycleGAN, Stroke, few-shot semi-supervised(이하 FS3) 크게 3개의 모듈로 구성되어 있음
- 2개의 discriminator를 사용:생성 결과가 실제 폰트와 같은지 판별하는 discriminator, 생성 글자의 stroke를 판별하는 decoder와 비슷한 역할의 discriminator
- source 폰트의 데이터는 pair 데이터가 존재하냐에 따라 S={Sf,Su} 로 나뉨 (Target data는 T={Tf,Tu})
- 학습 과정은 다음과 같다
- S를 Generator G에 주어 generated 글자 T′={T′f,T′u}를 생성
- T′를 Discriminator에 target set과 함께 discriminator에 input으로 주어 Real/Fake 판별
- T′를 stroke를 추출하는 discriminator에 넣어 실제 폰트와 stroke encoding 비교
- T′를 다시 Generator에 넣어 reconstruction data S′={S′f,S′u} 를 생성하고 consistency loss 계산
- FS3 모듈에서 FS3 loss 계산
- 전체 loss 수식을 보는 것이 더 이해하기 편함 (SE는 stroke encoding)
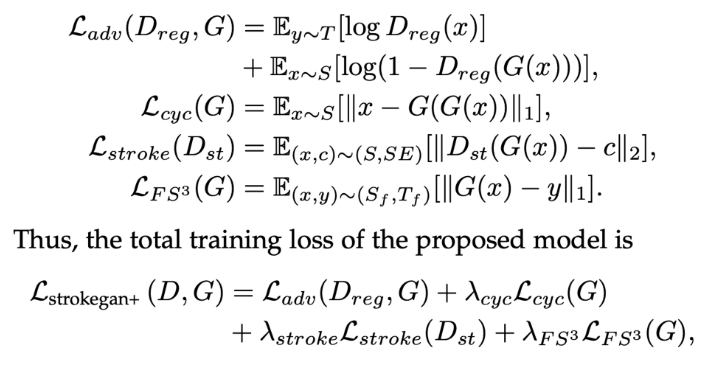
- Generator는 StorkeGAN loss를 줄이도록 학습하고 Discriminator는 StrokeGAN loss를 증가시키도록 학습
3. Experiments
3.1. Experimental Settings
- 14개 폰트 데이터 사용
- Pix2Pix, FUNIT, AttentionGAN, CycleGAN, SQ-GAN, StrokeGAN과 StrokeGAN+를 비교
- 모델 아키텍처는 이전 연구인 StrokeGAN과 동일
- Discriminator는 PatchGAN의 구조를 따름
- Adam(beta1=0.5, beta2=0.999)
- FID, LPIPS, PSNR, SSIM을 metric으로 지정
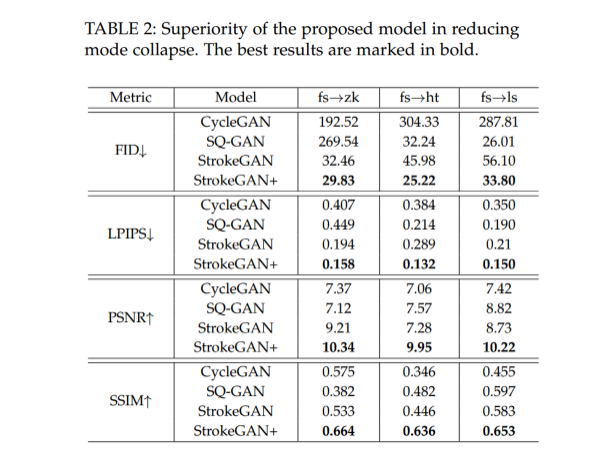
3.2. Superiority in Reducing Mode Collapse
- Fig.1을 보면 StrokeGAN+가 다른 모델에 비해 mode collapse에 강건함을 볼 수 있음
- StrokeGAN의 획 손실 문제도 이전에 비해 완화
3.3. On Few-Shot Semi-Supervised Schemes
- 2가지 Few-shot strategy를 비교
- pair sample characters를 랜덤으로 선정 (r)
- pair sample characters를 고정 (d)
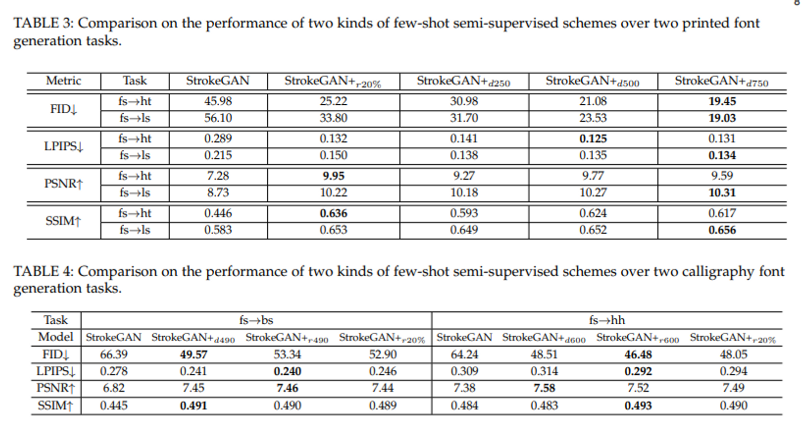
- few-shot semi-supervised sample을 주니 확실히 성능이 향상
- 고정 750 글자 정보를 주니 가장 전체적으로 좋은 생성 결과
- 일반적으로 고정된 글자를 주는 것이 더 좋은 결과를 보이나 캘리그래피 폰트는 그렇지 않았음
- StrokeGAN에 단순하게 데이터를 unpaired data로 추가하고 결과를 비교해봐도 StrokeGAN+가 few-shot semi-supervised를 통한 global structure 학습으로 인해 좋은 결과를 기록
3.4. Comparison with State-of-the-art Models
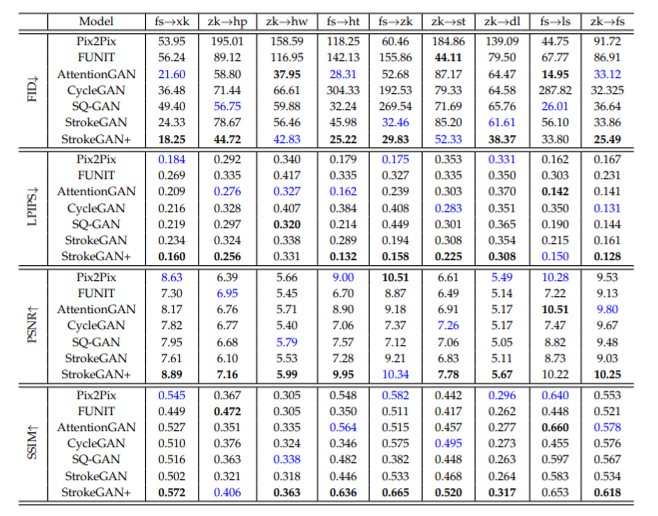

4. Generalizability and Extension
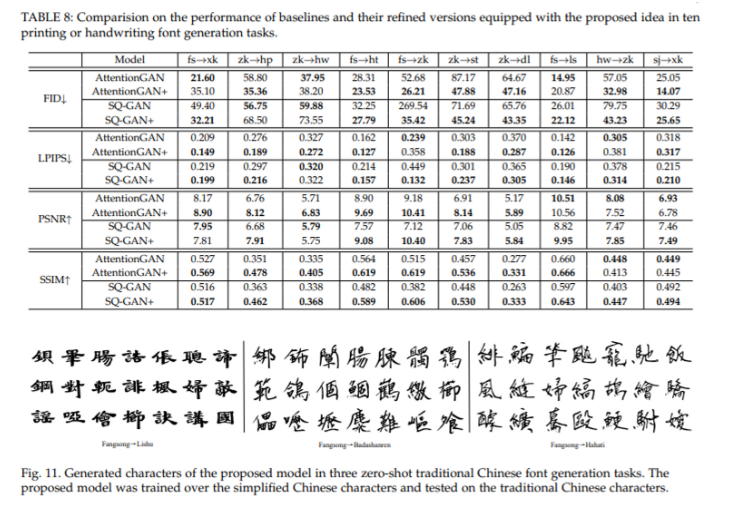
- Stroke 모듈과 FS3 모듈을 SQ-GAN, AttentionGAN에 추가하였더니 성능이 대체로 향상
- Fig.11을 보면 zero-shot font generation에서도 제시한 모듈이 효과가 있었음 (source font를 고정하고 target font를 바꾸는 기존 정석 few-shot font generation 세팅)
5. Conclusion
- 현존 중국어 폰트 생성 모델은 mode collapse 문제를 겪고 있음
- 이 연구는 간단하고 효과적인 supervision 정보를 제공하여 mode collapse를 완화
- local structure: one-bit stroke encoding
- global structure: few-shot semi-supervised samples
- 여러 실험을 통해 제시하는 방법론의 효과를 증명
- 논문의 아이디어를 다른 딥러닝 폰트 생성 방법론에 추가하고 성능 향상을 확인
후기 & 정리
- StrokeGAN의 후속 논문인 StrokeGAN+
- CycleGAN에 auxiliary information을 제공하기 위한 module이 추가된 구조
- local structure, global structure를 각각 one-bit stroke encoding, few-shot semi-supervised samples로 capture
- many-shot 중국어 font generation에서 SOTA를 달성
Reference
[0] Jinshan Zeng et al. (2022). "StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding". https://arxiv.org/abs/2211.06198
StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding
The generation of Chinese fonts has a wide range of applications. The currently predominated methods are mainly based on deep generative models, especially the generative adversarial networks (GANs). However, existing GAN-based models usually suffer from t
arxiv.org
[1] Jinshan Zeng et al. (2020). "StrokeGAN: Reducing Mode Collapse in Chinese Font Generation via Stroke Encoding". https://arxiv.org/abs/2012.08687
StrokeGAN: Reducing Mode Collapse in Chinese Font Generation via Stroke Encoding
The generation of stylish Chinese fonts is an important problem involved in many applications. Most of existing generation methods are based on the deep generative models, particularly, the generative adversarial networks (GAN) based models. However, these
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| DDPM: Denoising Diffusion Probabilistic Models (0) | 2023.01.20 |
|---|---|
| SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation (0) | 2022.12.10 |
| Zero-Shot Text-to-Image Generation (0) | 2022.12.03 |
| CLIP: Learning Transferable Visual Models From Natural Language Supervision (0) | 2022.11.04 |
| Few-Shot Unsupervised Image-to-Image Translation (0) | 2022.11.02 |



