
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- Unreal Engine
- RNN
- 모션매칭
- WBP
- Diffusion
- 딥러닝
- dl
- UE5
- CNN
- Stat110
- 디퓨전모델
- NLP
- Few-shot generation
- GAN
- 오블완
- 폰트생성
- 생성모델
- Generative Model
- ue5.4
- multimodal
- 언리얼엔진
- WinAPI
- BERT
- animation retargeting
- cv
- Font Generation
- motion matching
- userwidget
- deep learning
- ddpm
Archives
- Today
- Total
Deeper Learning
SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation 본문
AI/Deep Learning
SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
Dlaiml 2022. 12. 10. 12:37Jie Zhou, Yefei Wang, Yiyang Yuan, Qing Huang, Jinshan Zeng (2022.11)
Abstract
- 효과적인 가이드 정보가 없어 GAN-based 모델이 mode collapse 문제를 겪고 있음
- 본 연구는 skeleton guided channel expansion(이하 SGCE) 모듈로 skeleton 정보를 generator에게 channel expansion 방식으로 주어 local, global structure를 파악하게 하는 새로운 guidance 방식을 제시
- SGCE 모듈을 통해 mode collapse 문제가 완화되었으며 실험을 통해 이를 보임
- 4개의 metrics에서 SOTA를 달성
- 다른 중국어 폰트 생성 모델에도 plug-and-play 모듈로 활용가능하며 성능 또한 향상
1. Introduction
- 현존 중국어 폰트 생성 모델은 두 카테고리로 나눌 수 있음
- source, target domain의 one-to-one paired dataset을 기반으로하는 supervised models
- one-to-one paired data를 필요로 하지않는 unsupervised models
- Unsupervised models의 경우 mode collapse 문제가 발생
- 이를 해결하기 위해 획의 정보를 guidance information으로 제공하였던 StrokeGAN, SQ-GAN

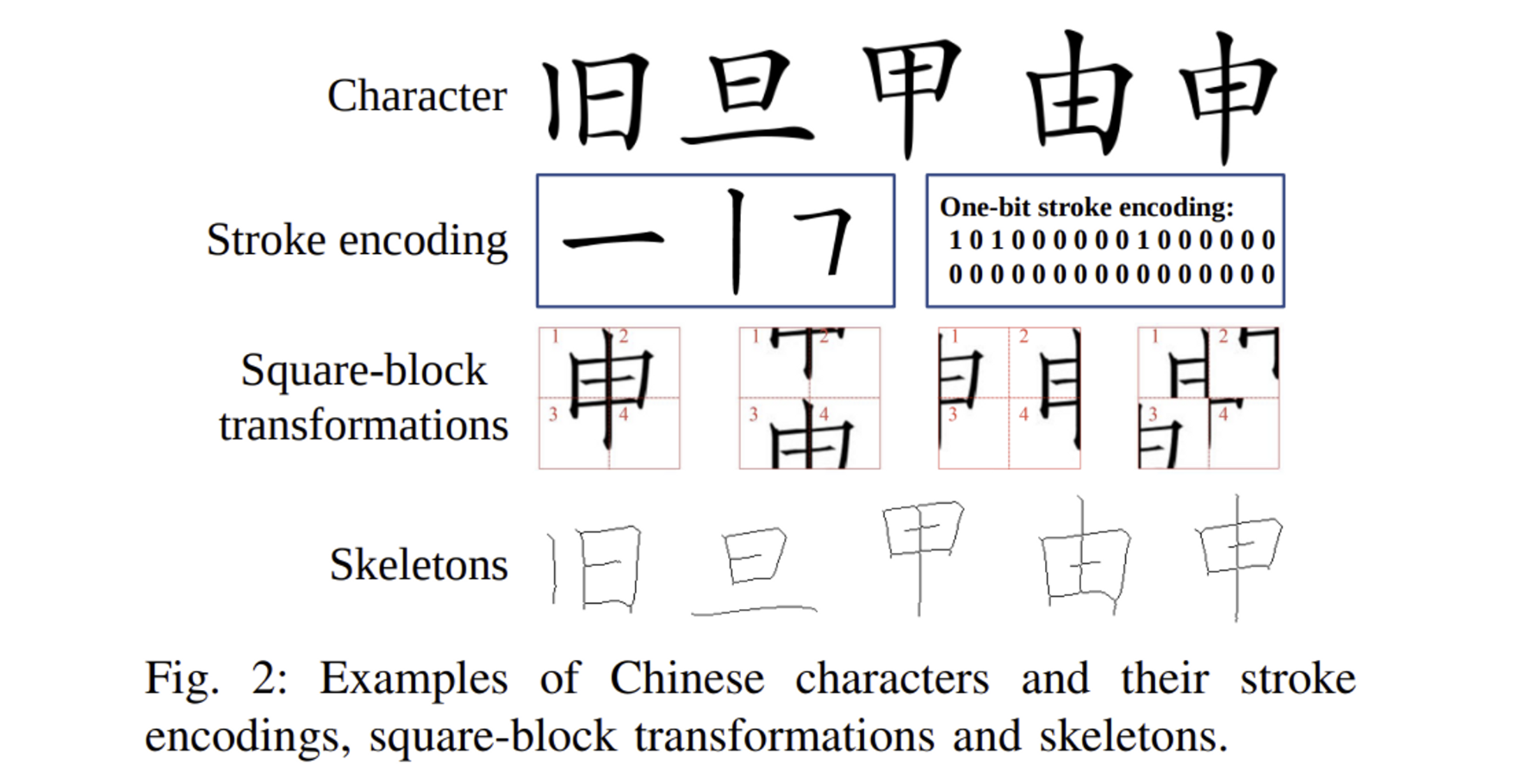
- 중국어 폰트 생성 학습에 효과적인 가이드 정보를 주는것에 집중
- 아래 두 질문에 대한 답을 찾는것이 목표
- 어떤 가이드 정보가 중국어 폰트 생성에 더 효과적인가?
- 가이드 정보를 어떻게 효과적으로 사용할 것인가?
- global, local structure 정보를 담고있는 skeleton을 가이드 정보로 사용
- 기존 연구들의 skeleton 활용 방식인 stroke-encoding, square-block transformation은 skeleton이 표현가능한 local, global structure를 온전하게 담지 못함
- 따라서 저자는 온전한 skeleton information을 generator의 input에 channel expansion으로 추가하여 skeleton 정보를 활용하는 방식을 제시
- 본 논문의 contributions은 다음과 같음
- SGCE 모듈을 활용하여 skeleton에서 global, local structure 정보를 추출하는 새로운 guidance를 제시
- 제시한 방식이 mode collapse를 완화함을 여러 실험을 통해 보임
- 다른 중국어 폰트 생성 모델에 제시한 모듈을 쉽게 적용할 수 있고 성능 또한 향상
2. SGCE for Chinese Font Generation
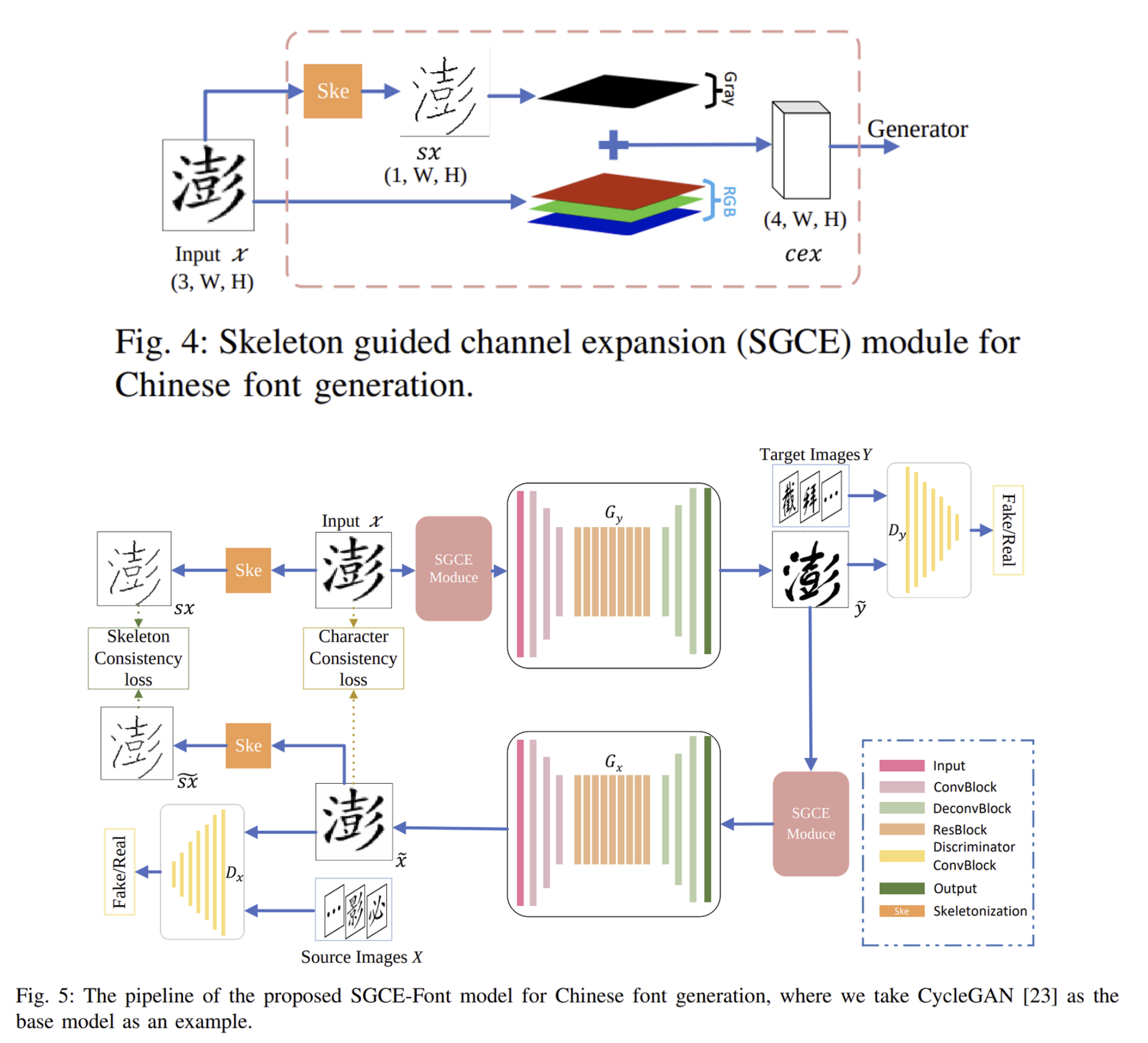
- Fig.4와 같이 input x 에서 skeletonization strategy Ske 를 사용하여 single channel skeleton인 sx 를 추출
- sx 를 원본 RGB 이미지 x 와 결합하여 만든 4-channel image 정보 cex 가 generator의 input으로 주어짐
- Skeletonization strategy
- 이미지를 binarize
- [Table I] 처럼 3x3 patch에서 대상 pixel P1 주위 픽셀을 넘버링 (edge의 경우 zero-padding)
- N(P1) 는 3x3 image patch에 존재하는 non-zero points의 수
- P(P1) 은 P2∼P9 sequence에서 (0,1) pairs의 수
- 아래 (a) and (b or c)를 만족하면 중앙의 pixel의 값을 제거
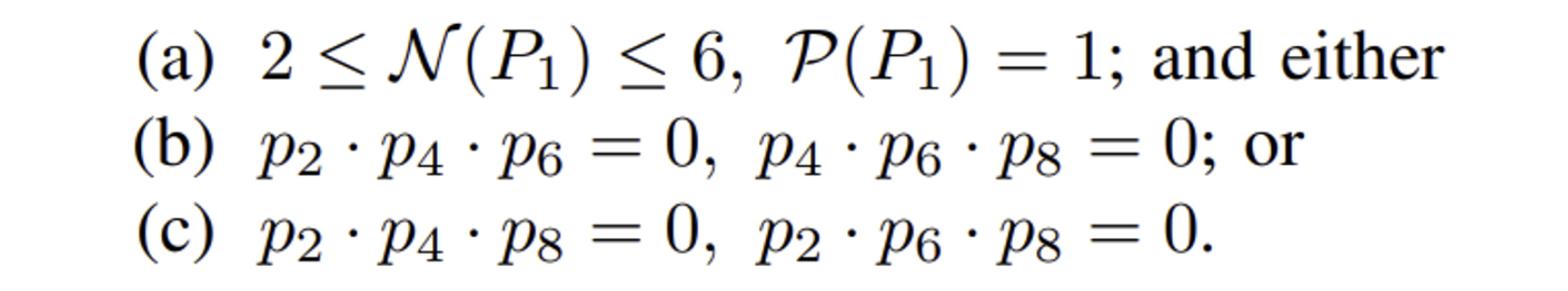
- 논문을 토대로 작성한 code snippet
#Skeletonization Code Snippet
import cv2
import numpy as np
from glob import glob
import os
glyph_value = 1
background_value = 0
padding_value = background_value
def get_pixel_values(img,x,y):
try:
return img[y][x]
except IndexError:
return padding_value
def build_patch(img, x, y):
p1 = get_pixel_values(img, x, y)
p2 = get_pixel_values(img, x, y-1)
p3 = get_pixel_values(img, x+1, y-1)
p4 = get_pixel_values(img, x+1, y)
p5 = get_pixel_values(img, x+1, y+1)
p6 = get_pixel_values(img, x, y+1)
p7 = get_pixel_values(img, x-1, y+1)
p8 = get_pixel_values(img, x-1, y)
p9 = get_pixel_values(img, x-1, y-1)
return np.array([[p9, p2, p3], [p8, p1, p4], [p7, p6, p5]]).astype(int)
def is_delete_pixel(patch, img):
p9, p2, p3 = patch[0]
p8, p1, p4 = patch[1]
p7, p6, p5 = patch[2]
seq = [p2, p3, p4, p5, p6, p7, p8, p9, p2]
count_01 = 0
for i in range(len(seq)-1):
if seq[i] == 0 and seq[i+1] == 1:
count_01 += 1
if (2 <= np.sum(patch) <= 6) and (count_01 == 1):
if np.sum([p2*p4*p6, p4*p6*p8]) == 0 or np.sum([p2*p4*p8, p2*p6*p8]) == 0:
return True
return False
def binarize_img(img):
for y in range(img.shape[0]):
for x in range(img.shape[1]):
if img[y, x]:
img[y, x] = 1
return img
def extract_skeleton(p):
img = cv2.imread(p, cv2.IMREAD_GRAYSCALE)
binarized_img = binarize_img(img.copy())
# check range of binarized_img is 0-1
print(np.min(binarized_img), np.max(binarized_img))
# canvas = np.zeros_like(img)
# extract skeleton
for i in range(30):
org_bin_img = binarized_img.copy()
for y in range(img.shape[0]):
for x in range(img.shape[1]):
patch = build_patch(binarized_img, x, y)
if is_delete_pixel(patch, binarized_img):
org_bin_img[y, x] = background_value
binarized_img = org_bin_img
cv2.imwrite(f'{i}_iter_skeleton.png', binarized_img*255)
- 다른 연구들은 딥러닝 모델을 사용하여 component의 skeleton을 추출하려는 시도를 하였음
2.2. Proposed SGCE-Font Model
- skeleton 정보가 포함된 4채널의 input을 generator에게 feed하는 것을 제외하고 CycleGAN과 매우 유사
- SGCE 모듈에 input을 통과시키고 Generator(source to target) Gy를 사용하여 target font style의 글자를 생성
- 생성된 글자 ˜y와 실제 데이터 글자를 Discriminator에 통과시켜 판별
- 생성된 글자 ˜y를 SGCE 모듈, Generator(target to source) Gx에게 주어 source domain의 글자 ˜x를 생성
- 생성한 source domain의 글자 ˜x를 source 폰트와 함께 Discriminator에 넣어 판별
- 원본 source 글자 x 와 생성한 source 글자 ˜x 를 각각 Skeletonize하여 둘의 L1 loss를 측정
- 원본 source 글자와 생성한 source 글자의 L1 loss를 측정
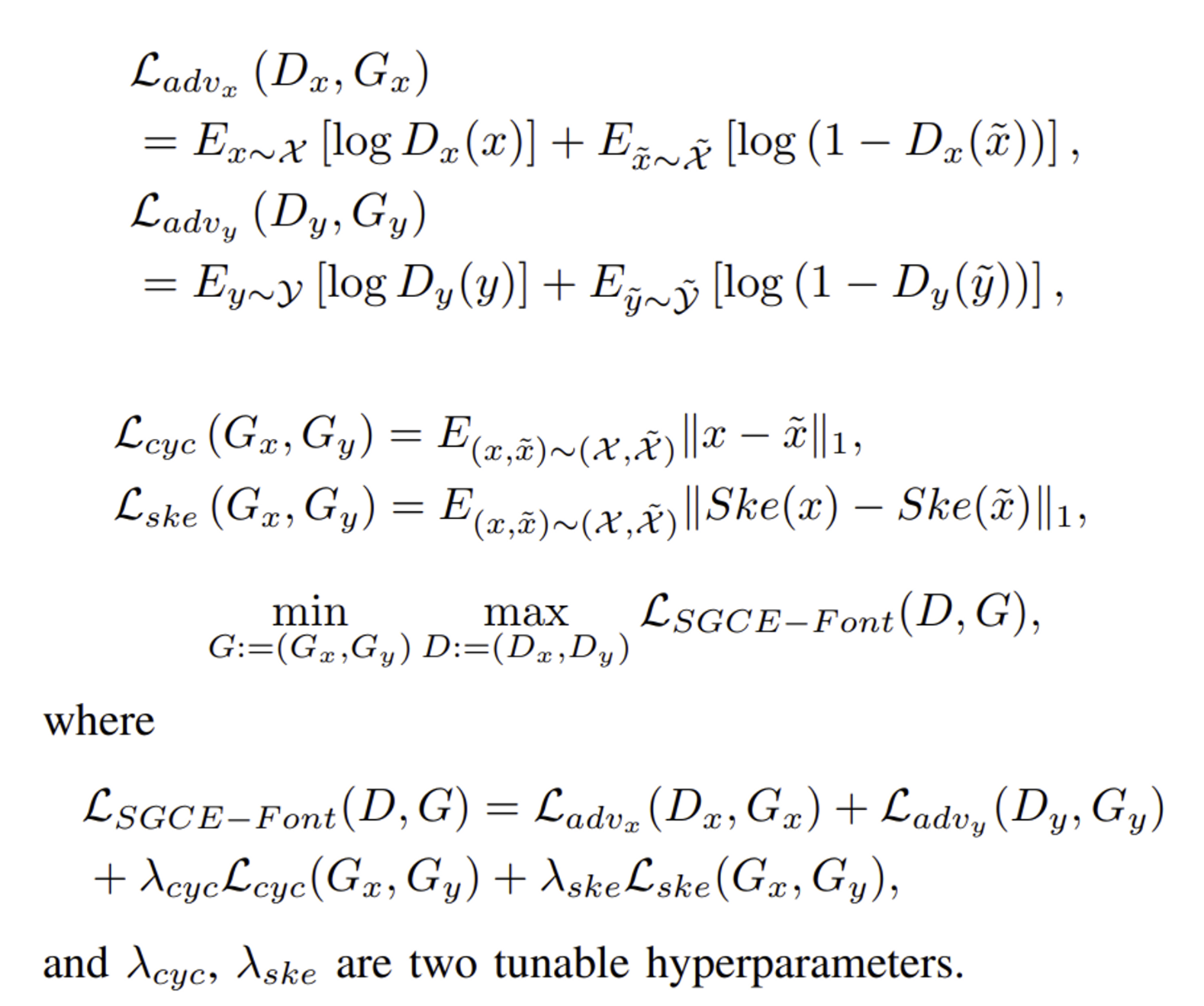
3. Experiments
- 3개의 고딕 폰트, 손글씨 폰트, 3개의 pseudo-손글씨 폰트, 3개의 calligraphy fonts 데이터셋
- 128 resolution image 사용, 데이터셋의 80%를 train set, 20%를 test set으로 사용
- CycleGAN, SQ-GAN, StrokeGAN, UGATIT, FUNIT, AttentionGAN 모델과 SGCE-Font를 FID, MSE, PSNR, SSIM에서 비교
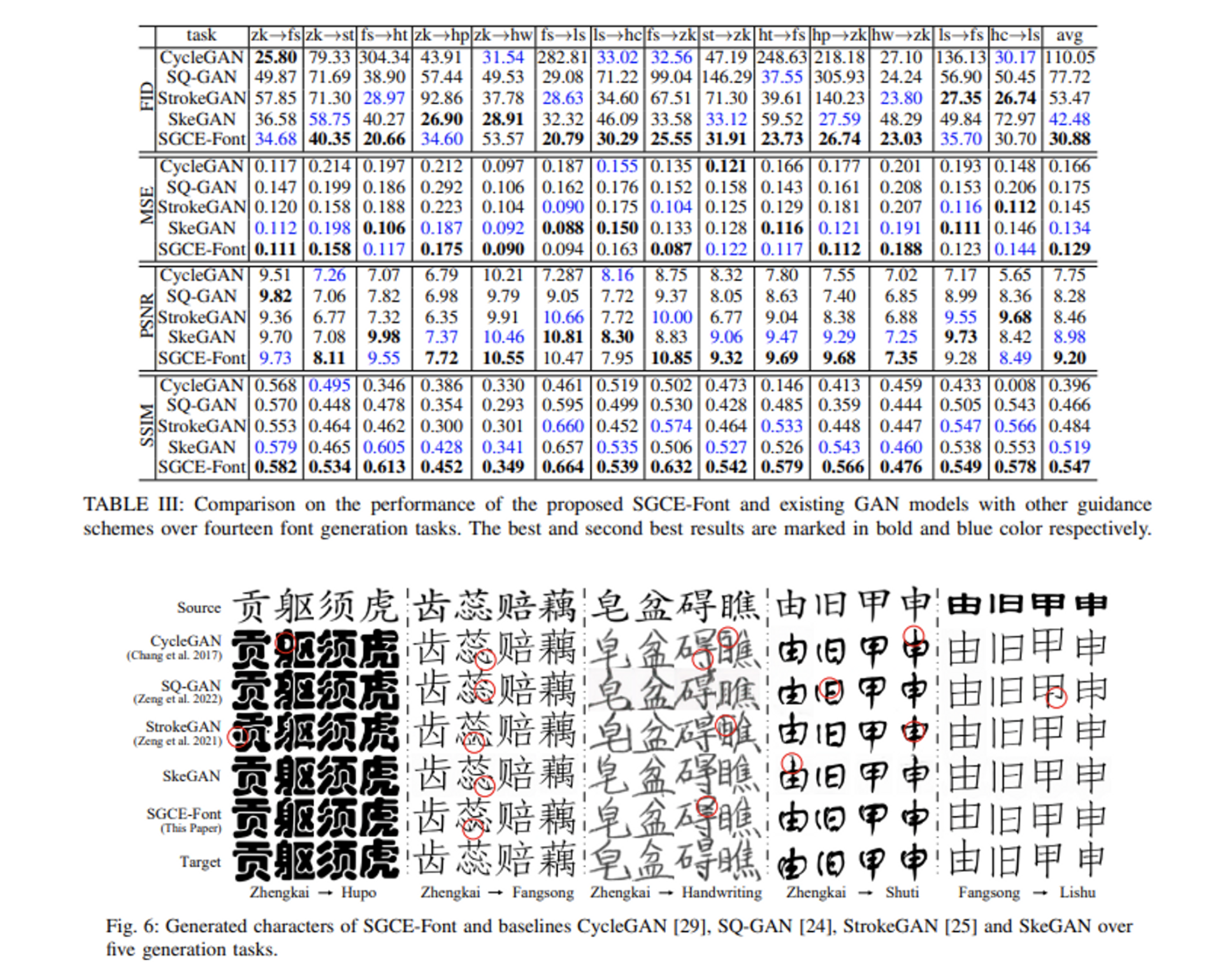

- 캘리그라피 스타일 폰트에서도 SGCE-Font의 성능이 뛰어났음

- 기존 method에 간단하게 SGCE 모듈을 추가하였더니 획을 더 잘 생성하는 효과가 있었음
4. Conclusion
- skeleton guided channel expansion(SGCE) 모듈로 skeleton 정보를 generator에게 channel expansion 방식으로 주어 local, global structure를 파악하게 하는 새로운 guidance 방식을 제시
- SGCE 모듈의 효과를 여러 실험으로 검증
- 다른 method에 쉽게 추가 가능하며 성능 향상에 도움이 되었음
- 다른 언어나 few-shot font 생성에 활용을 future work으로 제시
후기&정리
- 알고리즘으로 추출한 skeleton을 guidance information으로 활용하여 CycleGAN에서의 mode collapse 문제를 완화한 SGCE-Font
- skeleton information을 활용하는 StrokeGAN, StrokeGAN+와 비슷한 접근 방식
- 폰트 few-shot 생성 모델에서도 SGCE 모듈 추가로 획 손실 문제가 완화
- 논문에서 skeletonization code도 제공하지 않고 오타도 많으며 non-differentiable 프로세스의 gradient 처리 방식도 나와있지 않음
Reference
[0] Jie Zhou. (2022). "SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation". https://arxiv.org/abs/2211.14475
SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation
The automatic generation of Chinese fonts is an important problem involved in many applications. The predominated methods for the Chinese font generation are based on the deep generative models, especially the generative adversarial networks (GANs). Howeve
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| Diffusion Model 수식 정리 (0) | 2023.04.08 |
|---|---|
| DDPM: Denoising Diffusion Probabilistic Models (0) | 2023.01.20 |
| StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding (0) | 2022.12.06 |
| Zero-Shot Text-to-Image Generation (0) | 2022.12.03 |
| CLIP: Learning Transferable Visual Models From Natural Language Supervision (0) | 2022.11.04 |
'AI/Deep Learning' Related Articles
more




Comments