
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Generative Model
- 오블완
- dl
- WinAPI
- ue5.4
- UE5
- Diffusion
- 딥러닝
- deep learning
- cv
- Few-shot generation
- userwidget
- Unreal Engine
- motion matching
- 디퓨전모델
- NLP
- BERT
- RNN
- Font Generation
- 폰트생성
- animation retargeting
- ddpm
- 언리얼엔진
- 생성모델
- multimodal
- 모션매칭
- Stat110
- GAN
- WBP
- CNN
- Today
- Total
Deeper Learning
Diffusion Model 수식 정리 본문
prerequisite: Diffusion Model에 대한 기초적인 이해
Diffusion Model

T = 전체 Timesteps 수
xT = forward process를 T 번 적용한 마지막 Timestep T 에서의 이미지
x0 = 원본 이미지
Forward Process
q(xt|xt−1)=N(xt,√1−βtxt−1,βtI)
β 는 noise(variance)의 강도를 조절하는 parameter로 DDPM 논문에서는 0.0001 ~ 0.02의 값을 사용
β 가 선형적으로 timesteps에 따라(DDPM에서는 linear noise scheduler 사용) 0.0001에서 0.02까지 증가하면 √1−βt 는 1에서 0.989.. 까지 감소
x250 을 구하려면 위 one-step forward process를 250번 거쳐야 하는데 이는 병렬적으로 처리가 불가능한 프로세스라 시간이 오래 걸리는 문제가 있음.
한 번에 x0 에서 임의의 timestep t 의 xt 를 구할 수 있는 방법이 있는데 이를 설명하기 위해 notation을 추가로 정의해보자.
αt=1−βt
¯αt=t∏s=1αs, q(xt|xt−1)=N(xt,√αtxt−1,(1−αt)I)
Reverse Process
pθ(xt−1|x)
forward process와 반대로 denoise 하는 process, parameter set θ 를 가지는 모델을 사용
Training Objective 수식 Ver.1
Marginalize
p(x)=∫p(x,z)dz
Expectation
Ex(f(x))=∫xf(x)dx
Chain rule
p(x)=p(x,z)p(z|x)
p(x,z)=p(z|x)p(x)
MLE objective logp(x) 에서 시작
(34) x1:T 와 joint distribution을 Marginalize
logp(x)=log∫p(x0,x1:T)dx1:T=log∫p(x0:T)dx1:T
(35) 1=q(x1:T)q(x1:T) 를 곱해준다
(36) Expectation의 정의를 사용하여 정리
(37) Jensen’s inequality로 만든 부등식
(38) Chain rule 활용
T = 2 라고 하면
q(x1:2|x0)=q(x1,x2|x0)=q(x2|x0,x1)q(x1|x0)
이전 state에만 영향을 받는 Markov property에 의하여
q(x2|x0,x1)q(x1|x0)=q(x2|x1)q(x1|x0)
일반화하면
q(x1:T|x0)=T∏t=1q(xt|xt−1)
reverse process 부분도 마찬가지로 Chain rule을 활용하면
p(x0:T)=p(xT)p(x0:T−1|xT)=p(xT)T∏t=1pθ(xt−1|xt)
(39) timestep T, 1에 해당하는 수식을 분리
(40) t의 범위를 조정
(41) log 성질 활용
(42) log 성질 활용
(43) 셋째 항에서 Expectation 시그마 안으로 이동
(44) Expectation의 term을 각 항에서 사용하는 변수로 한정
(45) KL-divergence의 정의와, joint distribution에서 Expectation의 marginalize 성질을 활용하여 전개
KL(p||q)=∫xp(x)log(p(x)q(x))dx=Ex∼p[log(p(x)q(x))]
Eq(xT−1,xT|x0)[logp(xT)q(xT|xT−1)]=−Eq(xT−1,xT|x0)[logq(xT|xT−1)p(xT)]
=−Eq(xT−1|x0)q(xT|xT−1)[logq(xT|xT−1)p(xT)]=−Eq(xT−1|x0)∫xq(xT|xT−1)[logq(xT|xT−1)p(xT)]dx=−Eq(xT−1|x0)[DKL(q(xT|xT−1)||p(xT))]
셋 째항도 마찬가지로 정리하면
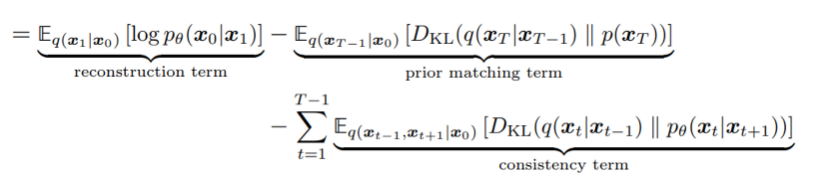
첫째항은 첫 forward process를 거친 이미지가 주어지고 원본 데이터의 log probability를 예측하는 reconstruction term으로 해석할 수 있으며 해당 term은 VAE에서도 등장
둘째항은 마지막 timestep의 xT 의 분포가 Gaussian prior와 일치하는지 계산하는 prior matching term으로 학습가능한 parameter가 없기 때문에 optimization이 이루어지지 않는다. (전체 timestep이 충분히 클 경우 마지막 forward process를 거친 데이터는 Gaussian을 따른다는 가정도 있음)
셋째항은 consistency term으로 xt 에서 분포가 consistent 하도록 하는 역할을 하는데 모든 timestep에서 denoising step의 분포를 대상 데이터의 한 step 전의 noising step과 맞추도록 KL-divergence를 사용한다.
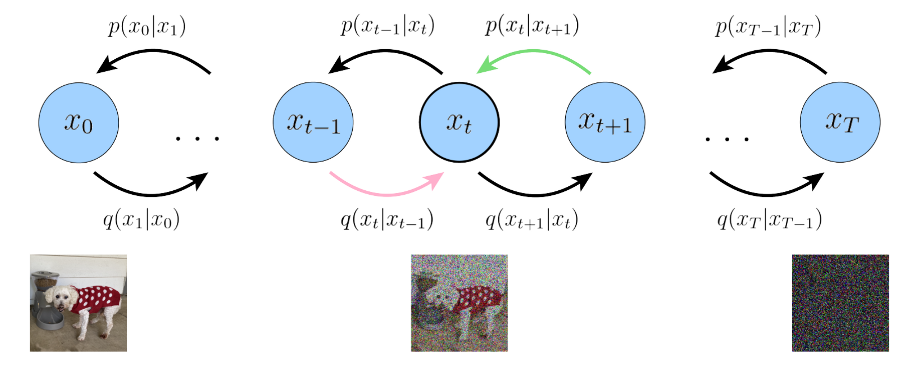
위에서 전개한 Training objective의 consistency term는 매 timestep에서 q(xt|xt−1) 와 p(xt|xt+1) 을 matching하는 방식으로 VDM(variational diffusion model)을 최적화 할 수 있다.
최종 Training objective의 식은 모두 기댓값을 사용하는데 이는 Monte Carlo 추정을 통해 근사할 수 있다. 여기에서 문제가 하나 있는데, 우리가 도출한 ELBO는 모든 timestep에서 두 random variables xt−1,xt+1 에 대한 기댓값을 사용하는 것이다. (consistency term에서)
timestep마다 하나의 random variable을 사용하는 것보다 2개의 random variables을 사용하면 Monte Carlo 추정에서 variance가 더 커지는 문제가 생긴다.
Training Objective 수식 Ver.2
timestep마다 하나의 random variable에 대한 기댓값만 사용하도록 수식을 다시 정리할 필요가 있다.
바로 이전 단계의 state에만 영향을 받는 Markov Property에 따라 x0 를 추가 조건으로 주어도 식은 동일하다.
q(xt|xt−1)=q(xt|xt−1,x0)
q(xt|xt−1,x0)=q(xt−1|xt,x0)q(xt|x0)q(xt−1|x0)
새로 정리한 forward process의 수식을 통해 다시 Training objective 식을 전개해보자 (37) ELBO 부분부터 이어서 시작하면
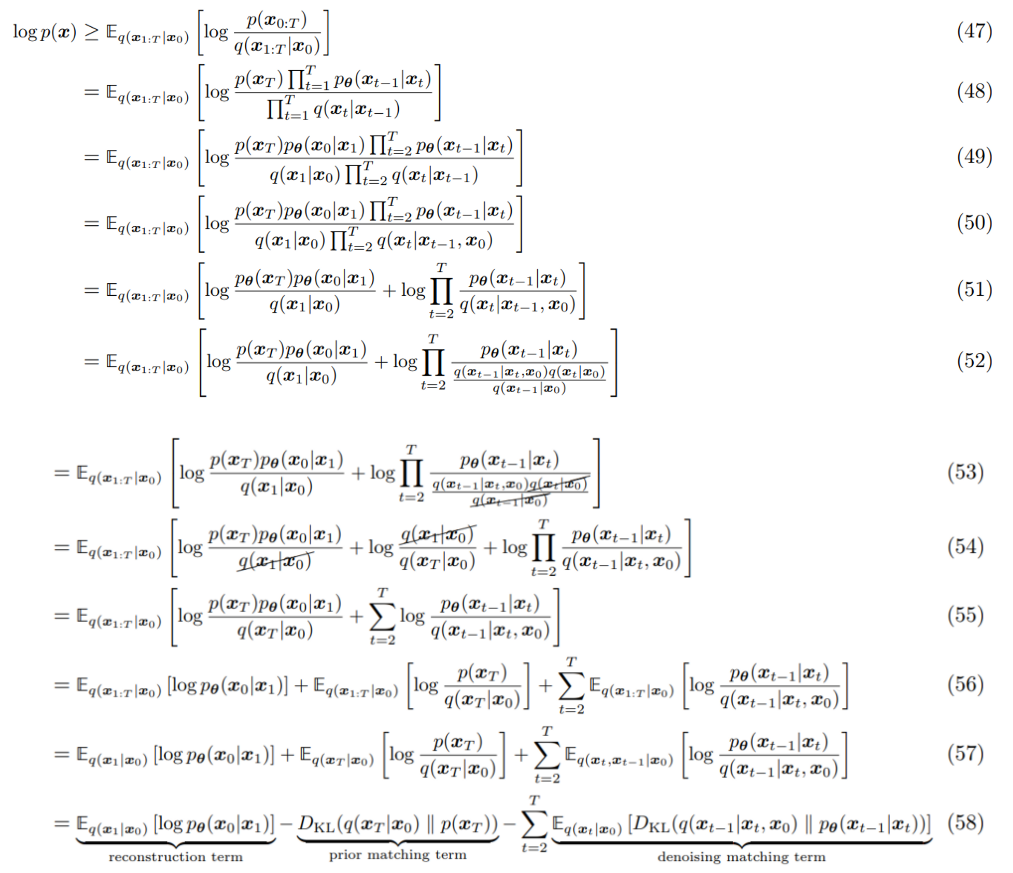
(48) (38)과 동일
(49) t=1에 해당하는 식을 밖으로 빼서 따로 표기
(50) Markov property로 인해 x0 을 condition에 추가하여도 동일한 식
(51) log 성질에 따라 항 분리
(52) 새로 정리한 forward process 수식 q(xt|xt−1,x0)=q(xt−1|xt,x0)q(xt|x0)q(xt−1|x0) 대입
(53)
T∏t=2q(xt−1|xt,x0)q(xt|x0)q(xt−1|x0)=q(x1|x2,x0)q(x2|x0)q(x1|x0)q(x2|x3,x0)q(x3|x0)q(x2|x0)...q(xT−1|xT,x0)q(xT|x0)q(xT−1|x0)
소거되는 항 q(x2|x0),q(x3|x0)... 을 모두 소거하면 아래와 같다.
T∏t=2q(xt−1|xt,x0)q(xt|x0)q(xt−1|x0)=q(xT|x0)q(x1|x0)T∏t=2q(xt−1|xt,x0)
이를 활용해서 식을 전개
(54) 소거
(55) log 성질에 따라 항 합침
(56) log 성질에 따라 항 분리
(57) Expectation의 대상이 되는 변수만 표기
(58) (45)번 전개방식과 동일하게 Expectation과 KL divergence의 관계를 활용
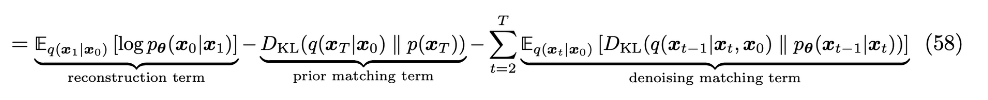
첫째항, 둘째항은 이전 전개와 동일하게 해석할 수 있다.
셋 째항은 denoising matching term 으로 tractable ground-truth denoising transition step인 q(xt−1|xt,x0) 에 모델이 예측한 denoising step pθ(xt−1|xt) 가 가까워지도록 하는 역할을 한다. q(xt−1|xt,x0) 는 noisy image xt 를 완벽히 denoise한 이미지 x0 정보를 가지고 denoise를 하기 때문에 ground-truth signal의 역할을 한다.
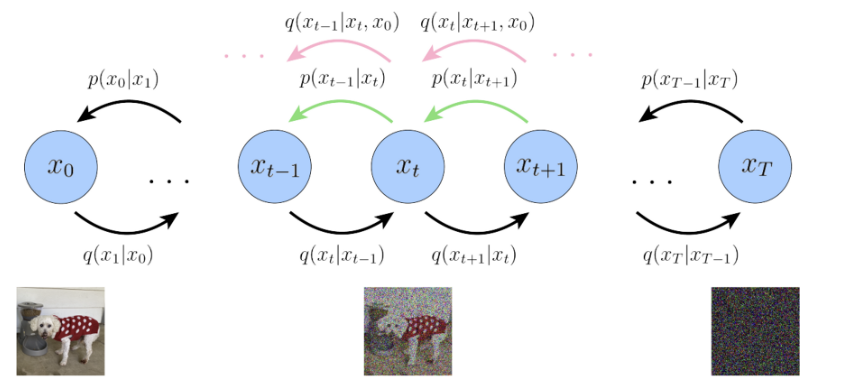
처음 전개한 식과 다르게 이제 timestep마다 하나의 random variable에 대한 Expectation을 계산한다. (처음과 다르게 초록, 분홍색 화살표의 condition이 동일하여 방향이 같음)
Ground-truth Denoising Step 수식 정리
이렇게 새로 구한 Training objective에서 아직 해결되지 않은 문제가 있다. denoising matching term의 ground-truth denoising transition step q(xt−1|xt,x0) 를 어떻게 나타낼지인데, 우선 Bayes Rule을 사용해보면 아래와 같다.
q(xt−1|xt,x0)=q(xt|xt−1,x0)q(xt−1|x0)q(xt|x0)
forward process는 위에서 정의한 것을 사용하면
q(xt|xt−1,x0)=q(xt|xt−1)=N(xt;√αtxt−1,(1−αt)I)
남은 term인 q(xt|x0),q(xt−1|x0) 는 아래의 reparameterization trick을 사용해 정리한다.
x∼N(x;μ,σ2)
x=μ+σϵ, ϵ∼N(ϵ,0,I)
이를 활용해서 xt∼q(xt|xt−1),xt−1∼q(xt−1|xt−2) 를 다시 써보면
xt∼q(xt|xt−1)=N(xt;√αtxt−1,(1−αt)I) xt=√αtxt−1+√1−αtϵ, ϵ∼N(ϵ;0,I) (59)
xt−1∼q(xt−1|xt−2)=N(xt−1;√αt−1xt−2,(1−αt−1)I)xt−1=√αt−1xt−2+√1−αt−1ϵ, ϵ∼N(ϵ;0,I) (60)
{ϵ∗t,ϵt}Tt=0∼i.i.d. N(ϵ;0,I) 와 같이 2T개의 random noise variables를 정의하고 이제 이를 모두 활용하여 xt∼q(xt|x0) 을 전개해보자
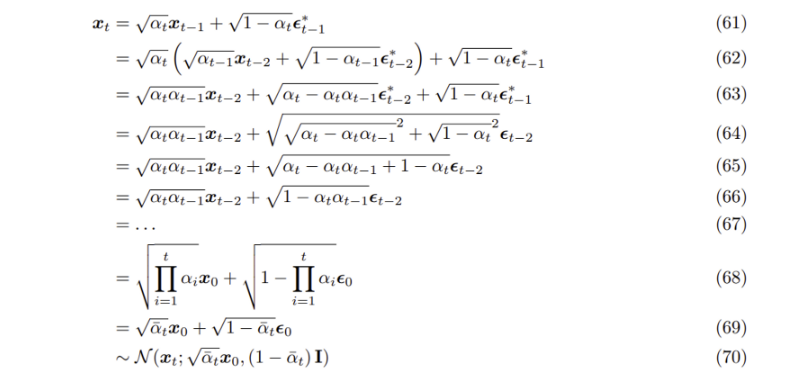
(61) 앞서 reparameterization trick을 사용해 구한 (59)식 사용
(62) 앞서 reparameterization trick을 사용해 구한 (60)식 사용
(63) √αt 를 곱해주는 분배법칙
(64)
√αt−αtαt−1ϵ∗t−2 는 reparameterization trick을 사용하면 반대로 평균이 0이고 분산이 αt−αtαt−1 인 가우시안 분포 N(0,(αt−αtαt−1)I) 의 sample로 생각할 수 있다.
√1−αtϵ∗t−1 도 마찬가지로 N(0,(1−α)I) 분포의 sample로 여길 수 있으며 두 가우시안 분포의 합은 각 가우시안 분포의 평균의 합이 평균이고, 분산의 합이 분산인 새로운 가우시안 분포가 되기 때문에(하단 수식 참고) (64)식으로 정리가 가능하다.
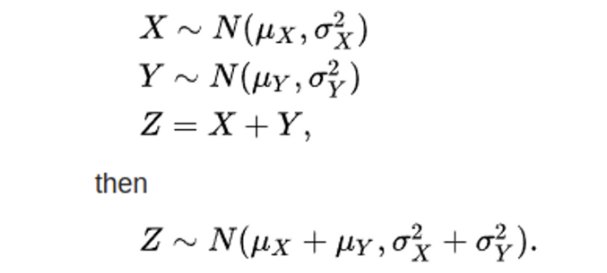
(65) 제곱근과 제곱 풀기
(66) αt 정리
(67, 68) (61)에서 xt−1,ϵ∗t−1 를 정리하면 (66)처럼 되는데 이를 timestep t에서 0까지 반복하고 이를 정리한 식
(69) α 의 timestep에 따른 누적곱을 새롭게 정의
ˉα=t∏i=1αi
(70) reparameterization trick에 의해 해당 random variable이 따르는 분포를 가우시안 분포로 표현
이제 x0 에서 한 번에 xt 로의 forward process를 식으로 아래와 같이 나타낼 수 있게 되었다
q(xt|x0)=N(xt;√ˉαtx0,(1−ˉαt)I)
이제 정리가 필요한 term을 모두 정리하였으니 딥러닝 모델의 denoise process가 근사하기를 바라는 ground-truth denoising transition step q(xt−1|xt,x0) 수식을 simplify 해보자.

(71) xt,xt−1 에 Bayes Rule 적용
(72) 앞서 정리한 수식 대입
(73) 비례관계 기호와 함께 Gaussian 분포의 P.D.F 식 사용, α 로 구성된 상수항은 비례기호 하에 생략 가능
(74) 공통으로 항들에 포함된 1/2을 괄호 밖으로
(75) 제곱을 풀고 x0,xt 로만 구성된 항들을 따로 정리
exp{−12[(x2t−2xt√αtxt−1+αtx2t−1)1−αt+x2t−1−2√ˉαt−1xt−1x0+ˉαt−1x201−ˉαt−1−x2t−2xt√¯αtx0+ˉαtx201−ˉαt]}
=exp{−12[x2t1−αt+−2xt√αtxt−1+αtx2t−11−αt+x2t−1−2√ˉαt−1xt−1x01−ˉαt−1+ˉαt−1x201−ˉαt−1−x2t−2xt√¯αtx0+ˉαtx201−ˉαt]}
=exp{−12[(−2xt√αtxt−1+αtx2t−1)1−αt+(x2t−1−2√ˉαt−1xt−1x0)1−ˉαt−1+x2t1−αt+ˉαt−1x201−ˉαt−1−x2t−2xt√¯αtx0+ˉαtx201−ˉαt]}
=exp{−12[(−2xt√αtxt−1+αtx2t−1)1−αt+(x2t−1−2√ˉαt−1xt−1x0)1−ˉαt−1+C(xt,x0)]}
(76) C(xt,x0) 을 비례기호를 사용하여 제거, 분자에서 항을 따로 표현
(77) x2t−1,xt−1 을 기준으로 식을 묶어 표현
(78) 첫째항에서 덧셈 부분을 계산
(79, 80) 첫째항의 분자 부분 계산, αt 가 지워짐
(81) 1−¯αt(1−αt)(1−¯αt−1) 로 식을 묶어 표현
(82) xt−1 가 포함된 항의 분자, 분모에 (1−αt)(1−ˉαt−1) 를 곱해주어 식을 정리
(83) (1−αt)(1−ˉαt−1) 를 xt−1 가 포함된 항에서 분배법칙을 이용하여 정리, 앞의 coefficient 부분에서는 1−ˉαt 로 분자, 분모를 나누어줌
(84) Gaussian distribution의 p.d.f를 정리해보면
N(xt−1,μ,σ2)=1√2πσexp{−12(xt−1−μσ)2}∝exp{−12(xt−1−μσ)2}=exp{−12(1σ2)(xt−1−μ)2}=exp{−12(1σ2)(x2t−1−2xt−1μ+μ2)}
정리한 식을 (83)의 식과 비교해보면
μ=√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αtσ2=(1−αt)(1−ˉαt−1)1−ˉαt
μ,σ 가 위와 같은 Gaussian 분포의 p.d.f와 비슷한 것을 볼 수 있다.
μ2 부분이 빠져있는데, μ 가 xt,x0 으로 구성된 항이기 때문에 (75)에서 C(xt,x0) 을 상수항으로 여기며 비례기호를 사용하여 식에서 배제한 것 처럼 비례기호를 사용하여 μ2 이 추가되었다고 가정하면 Gaussian distribution 꼴로 식을 만들 수 있다.
이제 Ground truth denoising step은 Gaussian 분포로 모델링 되었으며 식은 아래와 같다.
q(xt−1|xt,x0)∝N(xt−1;√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αt,(1−αt)(1−ˉαt−1)1−ˉαt)
Denoising Matching Term 수식 정리
q(xt−1|xt,x0)∝N(xt−1;√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αt,(1−αt)(1−ˉαt−1)1−ˉαt)
위 식에서 variance는 timestep에 따라 고정된 상수인 α term으로만 구성되어 있기 때문에 모델이 예측하는 denoising step pθ(xt−1|xt) 의 Variance는 Ground-truth denoising step의 variance를 그대로 사용하면 되기 때문에 μθ(xt,t) 를 parameterize하는 것만 남았다.

Denoising matching term을 다시보면 Ground-truth denoising step에 모델이 예측한 denoising step을 근사시키기 위해 KL Divergence를 사용하는데 둘다 Gaussian 분포로 모델링하였기 때문에 KL Divergence 식이 아래처럼 간단해진다.
DKL(N(x;μx,Σx)||N(y;μy,Σy))=12[log|Σy||Σx|−d+tr(Σ−1yΣx)+(μy−μx)TΣ−1y(μy−μx)]
GT(Ground truth) reverse process q 와 모델이 구한 reverse process p 는 둘 다 Gaussian 으로 모델링 되었으며 variance는 α 로 구성한 상수로 동일하게 세팅되어 있는 상태에서 Denoising Matching Term의 수식을 정리해보자.
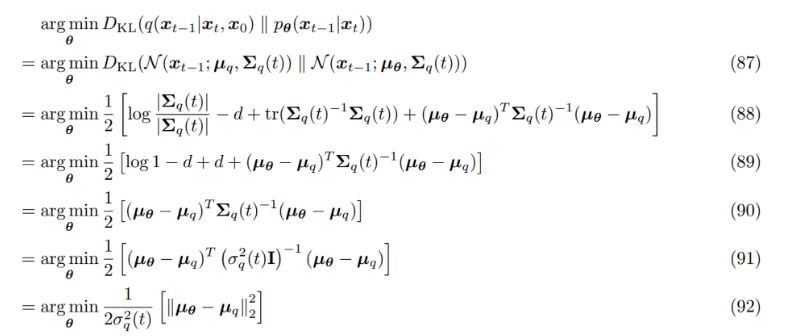
(87) 은 앞에서 구한 GT denoising step, 모델이 근사하는 denoising step을 Gaussian 형태로 표현한 것, variance는 α 로 구성되어 있어 따로 추정하지 않고 GT denoising step의 variance를 그대로 사용
(88) 두 다변량 Gaussian 분포의 Kullback–Leibler divergence 식을 사용
(89) 앞서 forward process를 정의할 때 Diagonal covariance matrix로 정의하였기 때문에 inverse matrix는 element에 역수를 취한것과 같고 원본 covariance matrix와 그 inverse matrix를 곱하면 Identity matrix가 되며 Trace를 구하면 dimension d 와 같다.
(90) log1=0, -d+d=0
(91) Diagonal covariance matrix 이기 때문에 Identity matrix와 상수부로 분리
(92) 역행렬은 각 element의 역수를 취한것과 동일 하고 variance가 각 변량에서 동일하기 때문에 상수로 표현가능하여 대괄호 밖으로 뺄 수 있음
벡터를 Transpose하고 원본 벡터와 곱하는 것은 벡터의 원소들의 제곱의 합인데 Frobenius norm은 벡터에서 원소들의 제곱의 합에 square root를 씌운것이기 때문에 argmin 하에 등호 사용가능
Denoising matching term에서 우리가 원하는 것은 이제 GT(이하 Ground truth, forward process의 수식으로 구한 denoising step) mean과 모델이 예측한 mean 값의 L2 norm이 가장 작아지는 model parameter set θ 를 구하는 것이 되었다.
앞서 (84) 에서 구한 GT denoising step의 mean의 수식은 아래와 같다.
μq(xt,x0,t)=√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αt
t,x0,xt 값과 상수 αt 로 식이 구성되어 있는데 모델을 통해 근사하려는 μθ(x,t) 는 Noise가 없는 원본 데이터 x0 의 정보가 없다는 차이점이 있다.
xt 의 정보는 동일하게 가지고 있기 때문에 이를 대입하면
μθ(xt,t)=√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)ˆxθ(xt,t)1−¯αt
x0 은 모델의 추정이 필요한 값으로 모델은 xt,t 를 사용하여 원본 이미지 x0 를 예측해야 한다.
새롭게 얻은 GT denoising step의 μq, predicted denoising step의 μθ 식을 대입하여 (92)에 이어서 식을 정리해보자.

(96) (92)식에서 새로 얻은 μq,μθ 식 대입
(97) 두 항에서 동일한 xt term 빼서 제거
(98) √ˉαt−1(1−αt)1−ˉαt 로 식을 묶음
(99) 상수부분을 Frobenius norm 밖으로 빼냄
(100) 임의의 timestep 2~T에서의 수식
Variational Diffusion Model(VDM)의 최적화는 neural network가 임의의 timestep의 noisy image에서 원본 GT image를 추정하면서 이루어진다.
Learning Diffusion Noise Parameters
앞서 forward process에서 α 는 1에서 최소값과 최대값을 정하고 timestep에 따라 일정하게 증가하는 β 를 빼서 계산한 timestep에 따라 fix된 상수로 정의하였는데 이를 neural net이 학습하도록 하는 방식도 있다.
단순하게 새로운 neural net을 사용하여 각 time step의 αt 를 예측하게 할 수 있는데 문제점은 α 의 cumulative product인 ˉαt 를 매번 새롭게 계산해야하는 computational cost가 발생한다는 것이다.
위에서 전개한 수식을 활용하면 더 효율적인 방식을 찾을 수 있다.
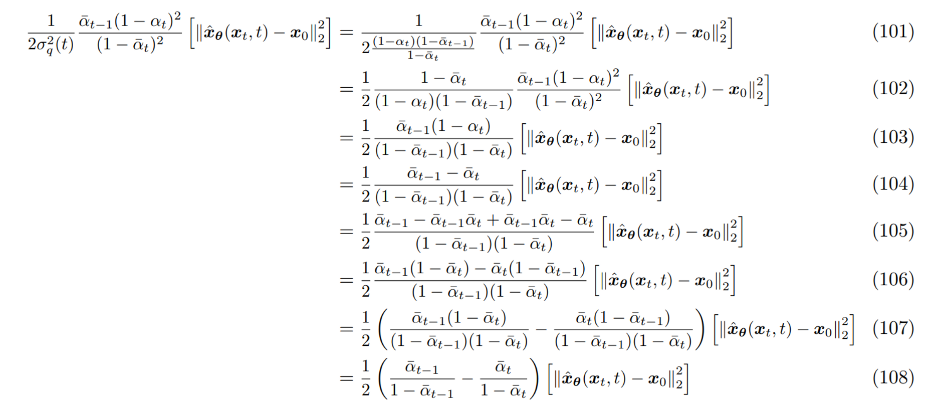
(101) (99) 수식에서 시작, 앞서 구한 GT denoising step 수식에서 분산 부분 수식을 대입
q(xt−1|xt,x0)∝N(xt−1;√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αt,(1−αt)(1−ˉαt−1)1−ˉαt)
(102) 1−¯αt 값을 분자, 분모에 곱해주어 식 저일
(103) 분자, 분모에서 동일한 식 소거
(104) ¯αt=αt×ˉαt−1 활용
(105) timestep에 따라 항을 나누기 위한 준비로 ˉαt−1ˉαt 를 추가
(106) ˉαt−1,ˉαt 로 분자의 항 묶음
(107) 두 항으로 식 나누기
(108) 분자, 분모 동일식 소거하여 timestep에 따른 항 분리 완료
Signal-to-noise ratio(SNR)는 noise 대비 signal의 level로 여러 형태로 정의할 수 있는데 아래 형태를 사용하겠다. https://en.wikipedia.org/wiki/Signal-to-noise_ratio#Definition
SNR=μ2σ2
이전에 정의한 q(xt|x0) 에 SNR 식을 적용해보면
q(xt|x0)=N(xt;√ˉαtx0,(1−ˉαt)I)SNR(t)=ˉαt1−ˉαt
SNR 식을 (108) 수식에 사용해보자
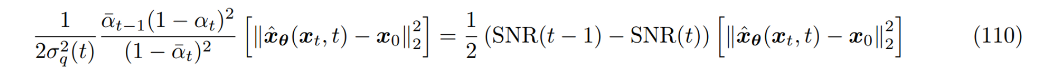
마지막 timestep T에 도달하였을 때, standard Gaussian이 되기 위해서는 SNR은 t가 커질 수록 점차 작아져야하기 때문에 SNR을 parameters η 를 가지는 단조 증가 neural net ωη(t) 로 모델링하자
SNR(t)=exp(−ωη(t))
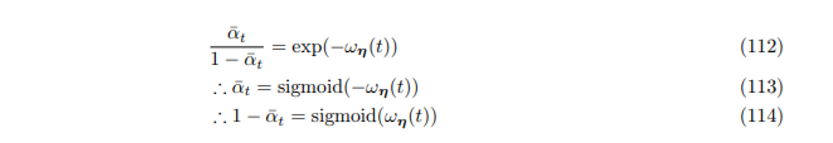
(112) 위에서 정한 SNR 식 대입
(113) Sigmoid 식 꼴로 식 변형
a=ˉα,b=ωη(t)a1−a=exp(−b)a=exp(−b)(1−a)a=exp(−b)−aexp(−b)a+aexp(−b)=exp(−b)a(1+exp(−b))=exp(−b)a=exp(−b)1+exp(−b)=11+exp(b)=11+exp(−(−b))sigmoid(z)=11+exp(−z)a=sigmoid(−b)ˉαt=sigmoid(−ωη(t))1−a=1−11+exp(b)=exp(b)1+exp(b)=11+exp(−b)=sigmoid(b)1−ˉαt=sigmoid(ωη(t))
Neural Net의 output에 sigmoid를 씌운 값이 1−ˉαt 를 추정하도록 하면 αt 를 직접적으로 추정하고 그 누적곱을 매번 계산하지 않아도 된다.
(실제 코드에서는 UNet model의 output의 dimension을 2배로 설정하고 반으로 나누어 epsilon(or original image) prediction, sigma prediction 으로 사용)
Epsilon Prediction
VDM은 neural net이 t,xt 가 주어진 상황에서 원본 이미지 x0 를 추정하는 방식으로 학습되는 것을 앞서 확인하였다.
원본 데이터 x0를 다른 term으로 나타낼 수 있는데 여러 forward step을 한 번에 정의한 식에 reparameterization trick을 사용하면 x0 가 xt,ϵ0 에 대한 식으로 정리된다.
q(xt|x0)=N(xt;√ˉαtx0,(1−ˉαt)I)xt=√ˉαtx0+√1−ˉαtϵ0x0=xt−√1−ˉαtϵ0√ˉαt(115)
(84)에서 구한 ground-truth denoising step의 mean의 수식과 approximate denoising step의 수식을 보면 모델에게 정보가 없는 x0 만 모델의 예측값으로 대체되는데 바로 위(115)에서 얻은 식을 사용하여 x0 를 xt,ϵ0 에 대한 식으로 바꾸면 모델은 ϵ0 를 예측해야하는 상황이 된다. (epsilon prediction)
μq(xt,x0,t)=√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)x01−¯αt
μθ(xt,t)=√αt(1−ˉαt−1)xt+√ˉαt−1(1−αt)ˆxθ(xt,t)1−¯αt

(117) (115)에서 얻은 식을 대입하여 x0 를 xt,ϵ0 에 대한 식으로 변경
(118) ˉαt 의 누적곱 성질을 활용하여 정리
√ˉαt−1=αt−1αt−2...α0√ˉαt=αtαt−1...α0√ˉαt−1√ˉαt=αt−1αt−2...α0αtαt−1...α0=1αt
(119,120) xt,ϵ0 으로 식을 정리하기 위함
(121) xt 로 묶은 식의 첫 항에서는 분자, 분모에 √αt 를 곱해주어 통분, ϵ0 로 묶은 식에는 분자, 분모에 √1−ˉαt 를 곱해주어 정리
(122,123,124) xt 의 계수부분 식 정리
새로 얻은 GT denoising step의 mean값을 근사하기 위해서 모델은 이제 ϵ0 을 추정해야하며 그에따른 approximate denosing step의 mean의 식은 아래와 같다.
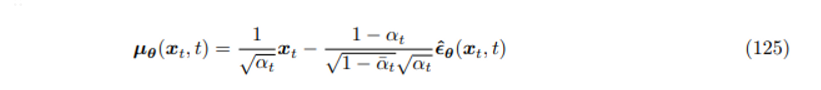
epsilon prediction 세팅으로 다시 denoising matching term의 수식을 전개해보자
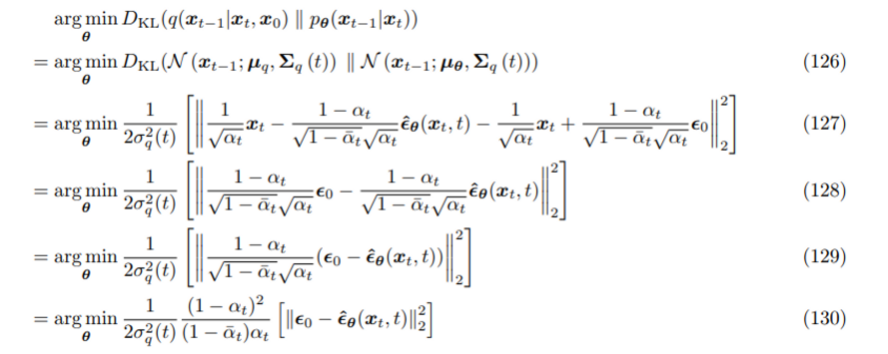
(127) (124)(125)에서 새로 얻은 μq,μθ 식 대입
(128) 두 항에서 동일한 xt term 빼서 제거
(129) 1−αt√1−ˉαt√αt 로 식을 묶음
(130) 상수부분을 Frobenius norm 밖으로 빼냄
모델은 xt,t 가 주어진 상황에서 Standard Gaussian 분포를 따르는 ϵ0∼N(ϵ;0,I)을 예측해야 한다.
VDM에서 원본 이미지 x0 을 예측하는 것은 x0 를 임의의 timestep t의 xt 로 만드는데 사용하는 noise ϵ 을 예측하는 것과 동일하다.
후기 & 정리
지금까지 아래 항목에 대해 다루었다.
- forward process
- reverse process
- ELBO를 활용한 MLE Training objective 정리
- 하나의 random variable이 condition이 되도록 다시 MLE Training objective 정리
- Denoising matching term 정리
- Noise parameter (Sigma, Variance) 학습 설정
- Epsilon prediction 설정
여러 Diffusion 코드 베이스를 빠르게 파악하거나 다른 Diffusion 논문의 수식을 이해하고 구현하는데 도움이 될 것 같아 line by line으로 전반적인 Diffusion 모델의 수식을 정리해보았다.
log variance training, previous mean prediction, epsilon prediction, x0 prediction, learning sigma, simple loss 등과 같이 여러 개인 구현 Diffusion repo에서 통일되지 않은 용어로 세팅들을 설명하고 있는데 수식과 코드를 대조하면서 보면 더욱 쉽고 빠르게 코드를 이해할 수 있음.
주로 “Understanding Diffusion Models: A Unified Perspective” 논문을 참고하였는데 VAE와 HVAE 수식 전개, Score-based generative model, Classifier-free-guidance 같은 개념도 자세하게 설명되어있어 개인적으로 추천한다.
Reference
[0] https://minibatchai.com/diffusion/generative-models/text2image/2022/06/17/Diffusion.html
[1] https://vinesmsuic.github.io/paper-ddpm/#Parametrized-Reverse-Denoising-Diffusion-Process
[2] Calvin Lui. (2022). “Understanding Diffusion Models: A Unified Perspective”. https://arxiv.org/abs/2208.11970
Understanding Diffusion Models: A Unified Perspective
Diffusion models have shown incredible capabilities as generative models; indeed, they power the current state-of-the-art models on text-conditioned image generation such as Imagen and DALL-E 2. In this work we review, demystify, and unify the understandin
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| Improved-DDPM: Improved Denoising Diffusion Probabilistic Models (0) | 2023.04.19 |
|---|---|
| DDIM: Denoising Diffusion Implicit Models (0) | 2023.04.14 |
| DDPM: Denoising Diffusion Probabilistic Models (0) | 2023.01.20 |
| SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation (0) | 2022.12.10 |
| StrokeGAN+: Few-Shot Semi-Supervised Chinese Font Generation with Stroke Encoding (0) | 2022.12.06 |



