
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- animation retargeting
- 딥러닝
- multimodal
- ue5.4
- 모션매칭
- 폰트생성
- Stat110
- WBP
- motion matching
- ddpm
- 오블완
- Few-shot generation
- GAN
- Font Generation
- 생성모델
- Generative Model
- 디퓨전모델
- UE5
- CNN
- dl
- Unreal Engine
- 언리얼엔진
- cv
- userwidget
- NLP
- deep learning
- WinAPI
- RNN
- BERT
- Diffusion
- Today
- Total
Deeper Learning
DDIM: Denoising Diffusion Implicit Models 본문
Jiaming Song, Chenlin Meng & Stefano Ermon, (2020.10) [Stanford University]
Abstract
- DDPM(Denoising diffusion probabilistic models)은 adversarial 학습 없이 고품질의 이미지 생성에 성공하였으나 sample을 만들기 위해 많은 스텝의 Markov chain을 거쳐야 하는 문제가 존재
- sampling을 빠르게 하기 위해 저자는 DDIM(denoising diffusion implicit models)을 제시
- DDPM에서 생성 과정은 Markovian diffusion process의 역으로 정의되어있음
- DDIM은 DDPM을 non-Markovian diffusion process의 class로 일반화하면서 DDPM과 동일한 training objective를 유지
- DDIM은 non-Markovian process로 일반화하였기 때문에 deterministic 생성 프로세스가 가능해졌고, 고품질의 샘플을 DDPM보다 10배~50배 빠르게 생성할 수 있게 되었다
- 연산량과 sample quality의 trade-off를 조절할 수 있게 되었고 latent space에서 바로 interpolation 또한 가능
1. Introduction
- GAN은 생성 분야에서 좋은 성능을 보이나 안정적인 학습을 위해 매우 세심한 최적화, 모델 아키텍처 세팅이 필요
- DDPM과 같은 iterative 생성 모델은 adversarial 개념의 학습 없이 좋은 퀄리티의 샘플을 생성해내는데 성공하였으나 하나의 sample을 생성할 때마다 모든 step을 반복해야 한다는 문제가 존재
- DDIM은 DDPM과 같은 objective funcion을 유지하면서 빠른 샘플링이 가능하여 DDPM과 GAN의 샘플 생성 속도 차이를 줄일 수 있음
- DDIM은 DDPM의 Markovian forward diffusion process을 non-Markovian으로 일반화
- 다양한 training objective가 surrogate objective를 공유

- non-Markovian diffusion process로 인해 short generative Markov chains이 생겼고 약간의 퀄리티 감소, 매우 큰 샘플링 속도 증가를 얻을 수 있었음
- DDIM vs DDPM
- DDIM은 DDPM보다 10~100배 빠르면서 샘플 퀄리티 또한 더 좋았음
- DDPM과 다르게 DDIM은 초기 latent variable을 동일하게 설정하고 샘플링하면 비슷한 고수준의 feature를 가진 샘플이 생성되는 일관성을 지님
- 일관성 성질로 인해 DDIM에서는 initial latent variable을 변경하며 image interpolation이 가능하지만 DDPM은 확률적 생성 프로세스로 인해 image space에서만 image interpolation이 가능하다.
2. Variational Inference for non-Markovian Forward Process
위 DDPM의 objective는 marginal q(xt|x0) 에만 의존적이며 joint q(x1:T|x0) 에 의존적인 것이 아님 (유도과정은 이전 Diffusion 수식 유도 과정 참고 https://dlaiml.tistory.com/entry/Diffusion-Model-수식-정리)
저자는 [Figure 1]의 우측 그림처럼 non-Markovian의 대체 inference process(q)를 사용하여 새로운 generative process를 실험하였다.
새로 정의한 non-Markovian inference process는 DDPM과 같은 surrogate objective를 가지는데 이를 아래에서 살펴보자
γ:=[γ1,...,γT] 로 α1:T 에 따라 정해지는 positive coefficients vector로 DDPM에서는 이를 1로 고정
2.1. Non-Markovian Forward Process
Notation
- forward process: q(x1:T|x0).
- reverse process(posterior) q(xt−1|xt).
- generative process pθ(x0:T)
(3)의 식은 DDPM에서 정의한 q(x1:T|x0) 으로 DDIM에서는 이를 (6)의 식과 같이 Non-Markovian으로 정의
모든 t에 대해 qσ(xt|x0)=N(√αtx0,(1−αt)I) 를 만족하게 하려면 (7)의 꼴의 식이 reverse process가 되어야 함. (논문 Lemma1 참고)
Forward process를 reverse process에 베이즈 정리를 사용하여 얻으면 아래와 같은데, DDPM과 다르게 forward process의 xt 가 xt−1,x0 에 depend 하여 더 이상 Markovian이 아닌 것을 볼 수 있다.
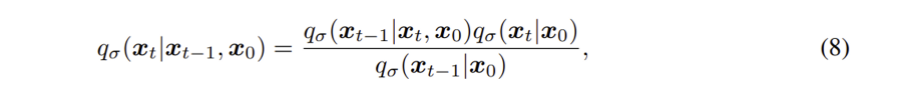
σ 는 forward process의 stochastic 정도를 조절하는 역할을 한다.
σ 가 극단적으로 0에 가까우면 xt,x0 이 주어지면 xt−1 이 fixed라고 볼 수 있다.
2.2. Generative Process and Unified Variational Inference Objective
다음으로 학습가능한 generative process pθ(x0:T) 를 정의해 보자.
xt, x0 를 앞서 정의한 reverse conditional distribution qσ(xt−1|xt,x0) 에 활용하여 xt−1 를 구할 수 있다.
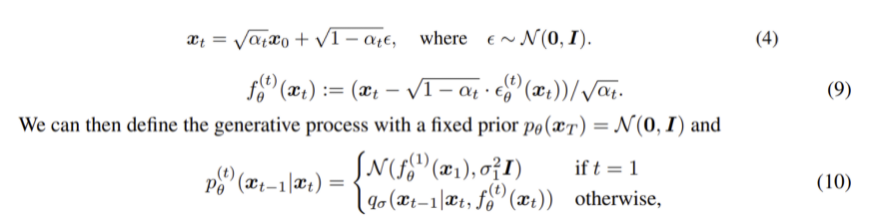
위 (4) 식을 x0 만 좌변에 남도록 정리하면 denoised observation을 추정하는 함수 f 를 (9)처럼 정의할 수 있고 이를 활용하여 generative process를 (10)과 같이 정의한다. (x0 을 f(t)θ(xt) 로 바꿈)
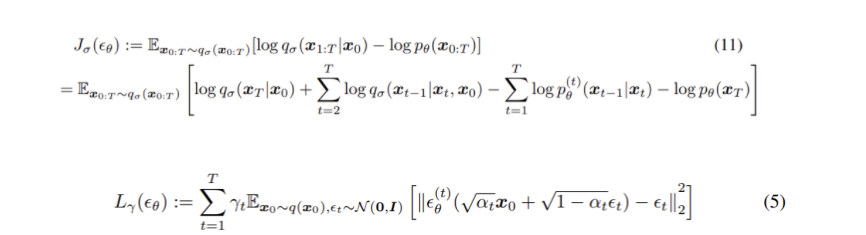
Training objective Jσ 는 다양한 σ 에 따라 정의된 다양한 모델에서의 training objective를 말하는데, Jσ 는 특정 γ 에서 Lγ 와 동일하다는 성질이 있다.

모델 ϵ(t)θ 의 parameter θ 가 다른 timestep에 대해 공유되지 않고 있으면 ϵθ 의 최적해는 weights γ 에 의존적이지 않게 되고 (global optimum이 각각 term을 최대화하는 방식으로 구해지기 때문에 weights γ는 최적화 과정에서 개입이 없음)Lγ 는 special 하다.
L1 은 DDPM의 variational lower bound의 surrogate objective function으로 쓰일 수 있으며 Theorem 1에 따라 Jσ 는 어떤 Lγ 과 동일하기 때문에 Jσ 의 optimal solution은 L1 의 optimal solution과 같다.
따라서 parameter가 t에 따라 공유되고 있지 않으면, DDPM의 L1 objective를 그대로 Jσ 의 surrogate objective로 사용할 수 있다.
3. Sampling from Generalized Generative Process
L1 objective를 사용하면 DDPM의 Markovian inference process 뿐만 아니라 σ 에 따른 많은 non-Markovian forward process도 학습하게 된다. 그러므로 DDPM의 학습 objective를 사용하고 σ 를 바꿔가며 sampling을 하는 것이 가능하다.
3.1. Denoising Diffusion Implicit Models
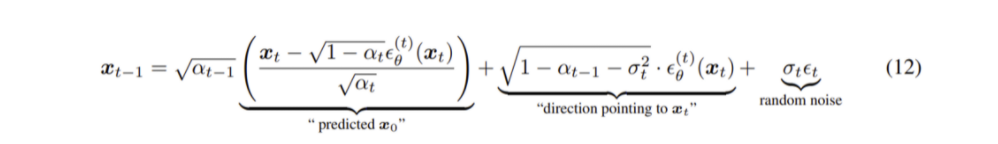
ϵt 는 xt 와 독립인 standard Gaussian noise고 α0:=1.
pθ(x1:T) 를 보면 xt 에서 xt−1 을 sampling 할 수 있다.
모델을 다시 학습시킬 필요 없이 σ 를 바꾸면서 sampling이 가능한데 σ 가 모든 t에 대해√(1−αt−1)/(1−αt)√1−αt/αt−1 이면 forward process는 Markovian이 되며 generative process는 DDPM의 그것과 동일해진다. (DDIM은 DDPM의 일반화 버전)
σt 가 모든 t에 대해 0이면 forward process는 t=1일 때를 제외하고 random noise가 들어간 항이 0으로 고정되어 deterministic 성질을 가지게 된다.
이때, 모델은 samples이 stochastic 하지 않은 과정을 거쳐 나온 latent variables(x0:T)에 의해 생성되는 implicit probabilistic model이 된다.
저자는 이를 DDPM obejctive로 학습된 implicit probabilistic 모델이기 때문에 DDIM(Denoising Diffusion Implicit Model)로 이름 붙였다.
3.2. Accelerated Generation Processes
generative process는 reverse process를 모델이 근사한 것으로 forward process가 T번 진행되기 때문에 sampling에서도 T번이 강제된다.
qσ(xt|x0) 가 고정된다면 forward process를 횟수 T번을 줄일 수 있어 generative process 또한 step이 줄어들어 sampling이 빨라지게 된다.
x1:T 전체가 아닌 subset {xγ1,...,xγS} 에 대해서만 forward, generative process가 진행되는데,
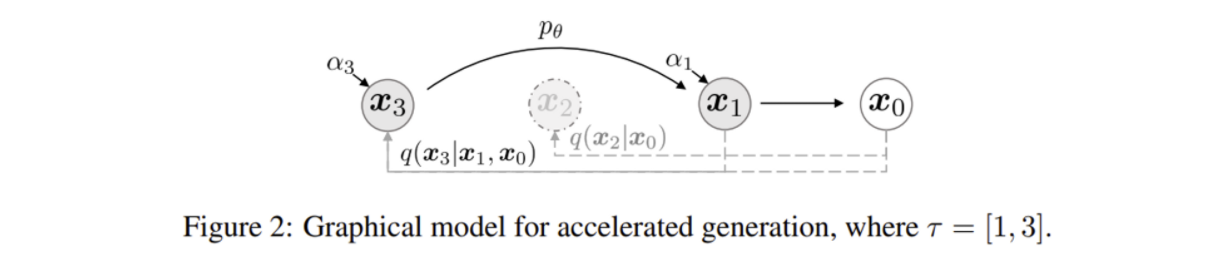
위 그림과 같은 형태로 이제 reverse process는 sampling trajectory(sampling 대상 subset)에서만 이루어지므로 계산량이 크게 줄어들게 된다.
전체 training step을 이용하지 않고 sampling이 가능하기 때문에 sampling 시간, 연산량 제약 없이 training step을 증가시킬 수 있고 또는 t를 continuous time variable로도 설정할 수 있는데 이를 future work으로 제시
ODE 관점에서 보면 DDIM은 DDPM과 달리 observation의 encoding을 구하는 데 사용할 수 있음.
4. Experiments
DDIM이 DDPM보다 10배~100배 빠르면서 이미지 생성 퀄리티 또한 뛰어나다는 것을 실험으로 보임
DDIM은 latent space에서 interpolation이 가능하고, latent code에서 reconstruction이 가능하도록 encoding 또한 가능
전체 timestep T는 1000으로 γ 는 1로 설정 (DDPM의 training objective 사용)
sampling trajectory를 결정하는 τ 를 바꿔가며 sampling 퀄리티와 속도의 trade-off 조절
σ 를 조절하기 편하도록 아래와 같은 식으로 표현 η 가 0이면 DDIM이며 η 가 1이면 DDPM
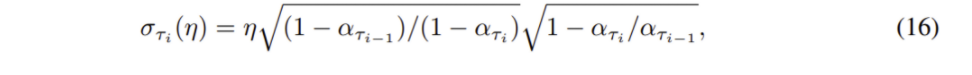
DDPM 논문에서 사용한 sigma는 ˆσ:ˆστi=√1−ατi/ατi−1 로 표기
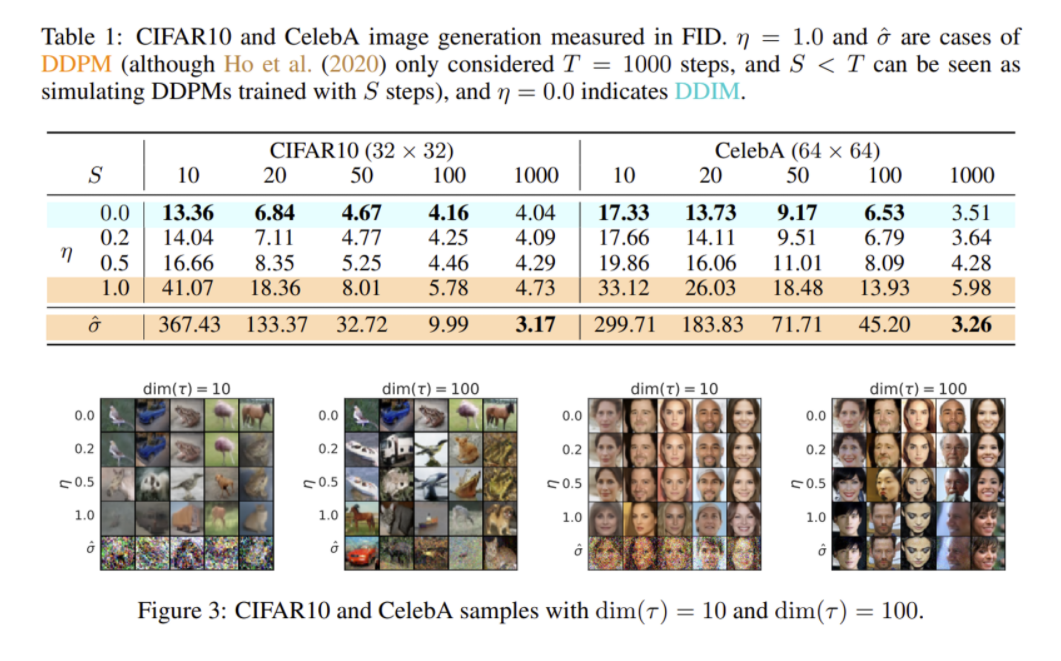
sampling 대상 step의 수인 τ 의 dimension이 커질수록 생성 결과의 퀄리티가 좋아지는 것을 관찰, τ 의 dim을 조절해 가며 연산량과 샘플 퀄리티의 trade-off를 조절 가능
전체 step을 사용하였을 때는 (τ=1000) 오히려 DDPM(η =1, ˆσ)의 성능이 더 좋았지만 DDPM은 τ 에 따른 결과의 variance가 큰 것을 볼 수 있다.
DDIM은 결과 퀄리티가 일관성 있으며 적은 sampling step인 상황에서는 더 좋은 퀄리티를 기록하였음.
[Figure 3]을 보면 DDPM은 τ 가 달라지면 결과가 달라지고 sampling trajectories가 짧으면 노이즈를 제대로 제거하지 못하는 결과를 보인다.
DDIM은 비교적 더 일관성 있는 결과물을 내는 것을 볼 수 있다.

Figure 4는 적은 step으로도 DDIM이 결과를 잘 생성해 낸다는 것을 보여주며 Figure 5는 DDIM이 sampling trajectories에 관계없이 일관성 있는 결과를 만든다는 것을 보여줌 (xT 가 encoded latent의 역할)
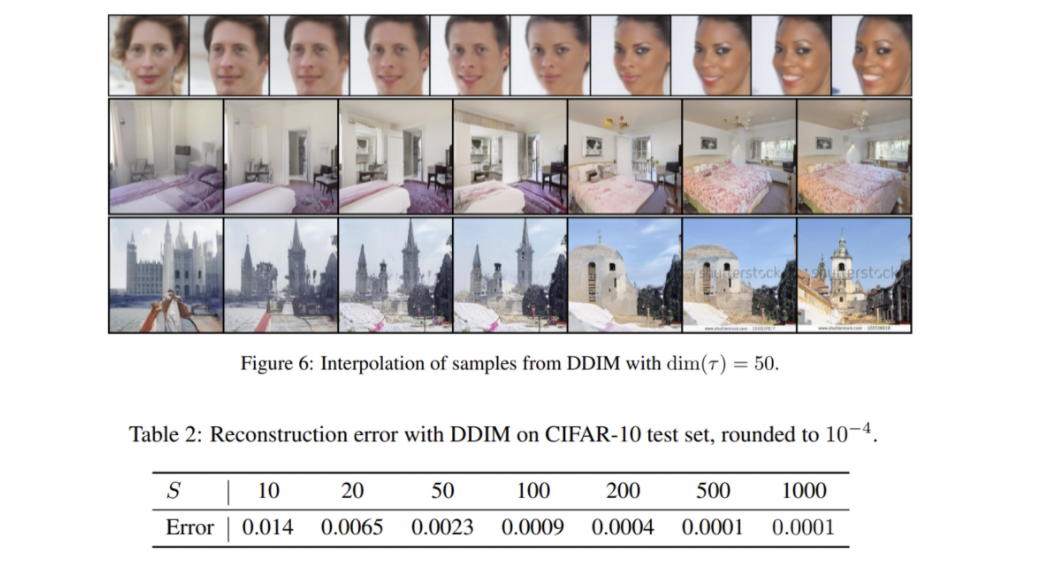
image encoder의 성질을 가지기 때문에 xT 에서 interpolation이 가능하고 latent space에서 reconstruction이 가능
5. Discussion
- DDPM, NCSN보다 효율적이고 고품질의 이미지를 생성할 수 있으며 latent space에서 meaningful interpolation이 가능한 DDIM을 제시
- Diffusion과 다르게 non-Markovian forward process에서는 Gaussian 외의 다른 연속적인 분포 사용의 사용이 가능
- Appendix에서 multinomial forward process discrete case에 대해 증명하였고 다른 경우에 대한 연구, neural ODE 관점에서의 추가 연구, DDIM과 다른 implicit models과의 차이점 연구를 future work으로 제시
후기 & 정리
- 저자는 DDPM을 non-Markovian diffusion process의 class로 일반화하면서 DDPM과 동일한 training objective를 유지하면서 빠른 샘플링이 가능한 DDIM을 제시
- 여러 sigma family의 training objective는 surrogate function의 최적해와 동일한 최적해를 가져 DDPM training objective로 학습된 모델에서 DDIM의 샘플링을 사용할 수 있었음
- 아이디어와 그 아이디어를 수식에 녹여내는 과정이 설명되어 있어서 좋았던 논문
- DDPM 수식을 최근에 정리해서 익숙한 수식이 많았음
- 코드를 작성하고 사용해 보니 샘플 퀄리티 차이는 거의 느끼지 못했고 sampling 속도가 빨라져 유용했던 method
Reference
[0] Jiaming Song et al. (2020). “Denoising Diffusion Implicit Models”. https://arxiv.org/abs/2010.02502
Denoising Diffusion Implicit Models
Denoising diffusion probabilistic models (DDPMs) have achieved high quality image generation without adversarial training, yet they require simulating a Markov chain for many steps to produce a sample. To accelerate sampling, we present denoising diffusion
arxiv.org
[1] https://dlaiml.tistory.com/entry/Diffusion-Model-수식-정리
Diffusion Model 수식 정리
prerequisite: Diffusion Model에 대한 기초적인 이해 Diffusion Model T = 전체 Timesteps 수 xT = forward process를 T 번 적용한 마지막 Timestep T 에서의 이미지 x0 = 원본 이미지 Forward Process $$ q(x_t|x_{t-1}) = N(x_
dlaiml.tistory.com
'AI > Deep Learning' 카테고리의 다른 글
| Diffusion Models Beat GANs on Image Synthesis (0) | 2023.05.05 |
|---|---|
| Improved-DDPM: Improved Denoising Diffusion Probabilistic Models (0) | 2023.04.19 |
| Diffusion Model 수식 정리 (0) | 2023.04.08 |
| DDPM: Denoising Diffusion Probabilistic Models (0) | 2023.01.20 |
| SGCE-Font: Skeleton Guided Channel Expansion for Chinese Font Generation (0) | 2022.12.10 |



