
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- BERT
- WBP
- RNN
- motion matching
- 오블완
- CNN
- GAN
- 언리얼엔진
- Unreal Engine
- WinAPI
- ddpm
- animation retargeting
- ue5.4
- Diffusion
- deep learning
- dl
- userwidget
- Few-shot generation
- Stat110
- 폰트생성
- NLP
- multimodal
- Generative Model
- 디퓨전모델
- UE5
- Font Generation
- 생성모델
- 모션매칭
- cv
- 딥러닝
- Today
- Total
Deeper Learning
Diffusion Models Beat GANs on Image Synthesis 본문
Prafulla Dhariwal, Alex Nichol, (2021.05) [OpenAI]
Abstract
- Diffusion 모델이 현재 SOTA 생성 모델을 뛰어넘는 샘플 이미지 퀄리티를 달성할 수 있음을 본 논문에서 소개
- unconditional image 생성에서는 Ablation study를 통해 찾은 더 나은 아키텍처를 적용하였고 conditional image 생성에서 classifier의 gradient를 활용하여 더 좋은 샘플 퀄리티와, fidelity & diversity trade-off를 조정할 수 있는 classifier-guidance를 제시
- Diffusion 모델의 장점은 distribution coverage를 유지한 채 25 forward step만으로도 BigGAN-deep과 동일한 FID를 달성
- classifier-guidance를 upsampling diffusion(256, 512)에 사용하였을 때 더 좋은 FID를 달성
1. Introduction
GAN은 현재(2021.05) 이미지 생성에서 FID, Inception Score, Precision 측면에서 SOTA이지만 likelihood-base 모델이 diversity 측면에서 더 성능이 좋다는 것이 연구를 통해 밝혀졌다. 게다가 GAN은 학습이 매우 어려우며 세심한 hyperparameter tuning을 요구한다.
Diffusion 모델은 최근 likelihood 기반 모델 중 하나로 scalability, static training objective, distribution coverage의 장점을 가지며 뛰어난 샘플 퀄리티를 가지고 있다. CIFAR-10과 같은 간단한 데이터셋에서는 Diffusion 모델이 SOTA를 달성하였지만 ImageNet, LSUN과 같은 어려운 데이터셋에서는 기존 SOTA인 BigGAN-deep을 넘지 못하였다.
저자는 이 차이가 GAN은 많은 연구로 모델이 최적화 되었고 diversity, fidelity trade-off 조절이 가능하기(truncation trick)지만 Diffusion 모델들은 그렇지 않다는 것에서 기인하였을 수 있다고 가설을 세웠다. 저자는 Diffusion 모델의 모델 아키텍처를 개선하고 fidelity, diversity trade-off 방식을 연구하여 여러 metric, dataset에서 GAN의 성능을 뛰어넘게 하였다.
2. Background
DDPM, Improved-DDPM, DDIM 관련 내용 (생략)
정석적이며 fidelity와 diversity를 모두 커버하는 metric인 FID를 default metric으로 사용
3. Architecture Improvements
아래 항목에 대한 실험을 진행하였다.
- width 대비 depth 늘리기 (모델 사이즈는 유지)
- Attention heads 늘리기
- 16x16 resolution 뿐만 아니라, 32x32, 8x8 resolution에서도 Attention 적용
- upsampling, downsampling에 BigGAN residual block 사용
- residual connection을 1√2로 rescaling
이번 섹션의 모든 실험은 ImageNet 128x128, 256 batch size, 250 sampling steps 세팅하에 진행하였다.

[Table 1]을 보면 rescaling residual block을 제외한 모든 modification이 성능 향상으로 이어졌음을 확인할 수 있다.
[Figure 2]를 보면 depth를 늘리는 것이 성능 향상에 도움이 되지만 width를 늘린 모델과 같은 성능을 달성하는데 더 많은 시간이 걸리는 것을 볼 수 있다. 저자는 width 대비 depth 늘리기를 사용하지 않기로 결정하였다.
Transformer 아키텍처에 대한 연구도 진행하였는데 attention heads 숫자를 조절하거나 head 마다 담당하는 channels의 수를 조절하며 실험을 하였다. 128 base channels, resolution 마다 2 res blocks, multi-resolution attention, BigGAN up/downsampling 세팅으로 700K iterations 동안 학습하고 결과를 비교하였다.
[Figure 2], [Table 2]는 해당 실험의 결과로 heads 수를 고정하면 heads가 많아질수록 성능이 좋아졌으며 channels에 따라 heads의 수를 조절할 때는 마찬가지로 heads마다 담당하는 channels의 수가 작을수록(heads가 많을수록) 성능이 좋아졌다. 학습 시간 기준 성능으로는 64 channels per head가 가장 좋았기에 해당 세팅을 최종 FID를 구할 때 사용하였다.
3.1. Adaptive Group Normalization
연구진은 Adaptive group normalization(AdaGN)을 사용하여 class embedding, timestep의 정보를 각각 residual block에 전달하는 AdaIN, FiLM 비슷한 방식도 실험하였다. h 가 residual blocks의 activations이고 y=[ys,yb] 는 timestep, class embedding의 linear projection으로 얻은 값일 때, AdaGN(h,y)=ys(GroupNorm(h))+yb 으로 AdaGN 연산이 이루어진다.
AdaGN은 이미 diffusion 모델에서 성능이 검증되어서 기본 세팅으로 사용하였고 대신 Ablation study를 진행하였다. Addition + GroupNorm보다 AdaGN을 사용한 정보 통합 방식이 더 좋은 성능을 기록하였다.
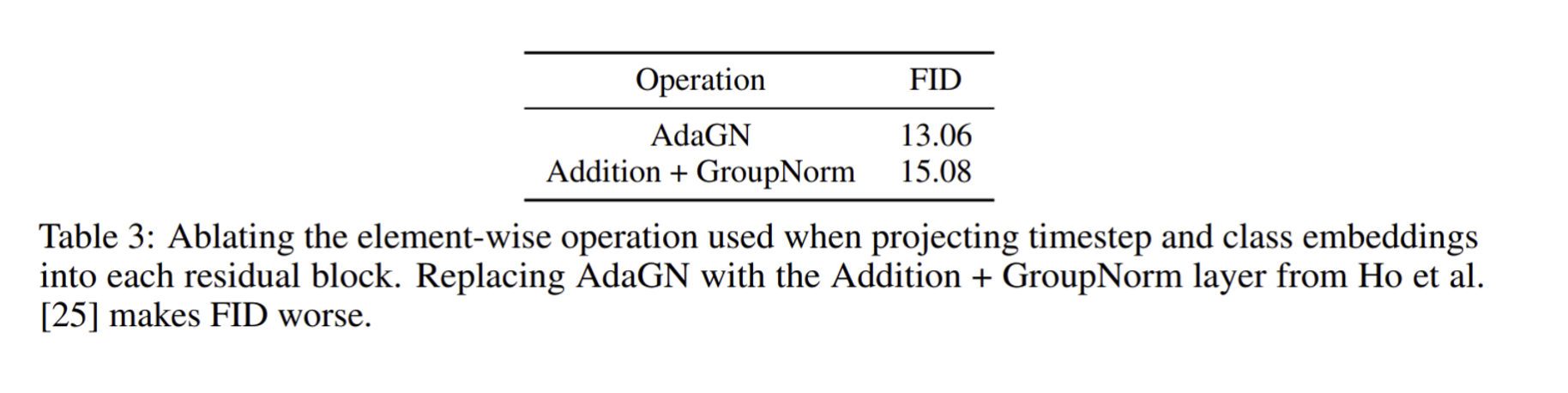
실험을 통해 최종 세팅을 기본 세팅으로 사용하기로 하였다
- 2 residual blocks per resolution
- multiple heads, 64 channels per head
- attention 32, 16, 8 resolutions
- BigGAN residual blocks for up/down sampling
- Injecting timestep, class embeddings using AdaGN
4. Classifier Guidance
GAN의 conditional 생성에서는 Discriminator가 Classifier의 역할을 간접적으로 하며 class label을 활용한다. 이에 영감을 받아 저자는 Classifier를 Diffusion에서도 활용하여 생성 퀄리티를 높이는 방식을 제시하였다.
Unconditional reverse noising process를 pθ(xt|xt+1) 라고 하고 class label y, classifier parameter set ϕ 를 사용하여 Conditional reverse noising process를 식으로 나타내면 아래와 같다.
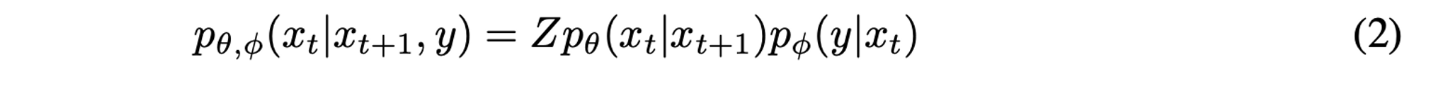
Z는 normalizing constant, 수식을 정리하면 아래와 같이 classifier가 추가된 reverse process도 mean shifted Gaussian noise로 근사할 수 있는 것을 볼 수 있다. (자세한 전개는 생략, 논문 Section 4.1. 참고)

4.1. Scaling Classifier Gradients
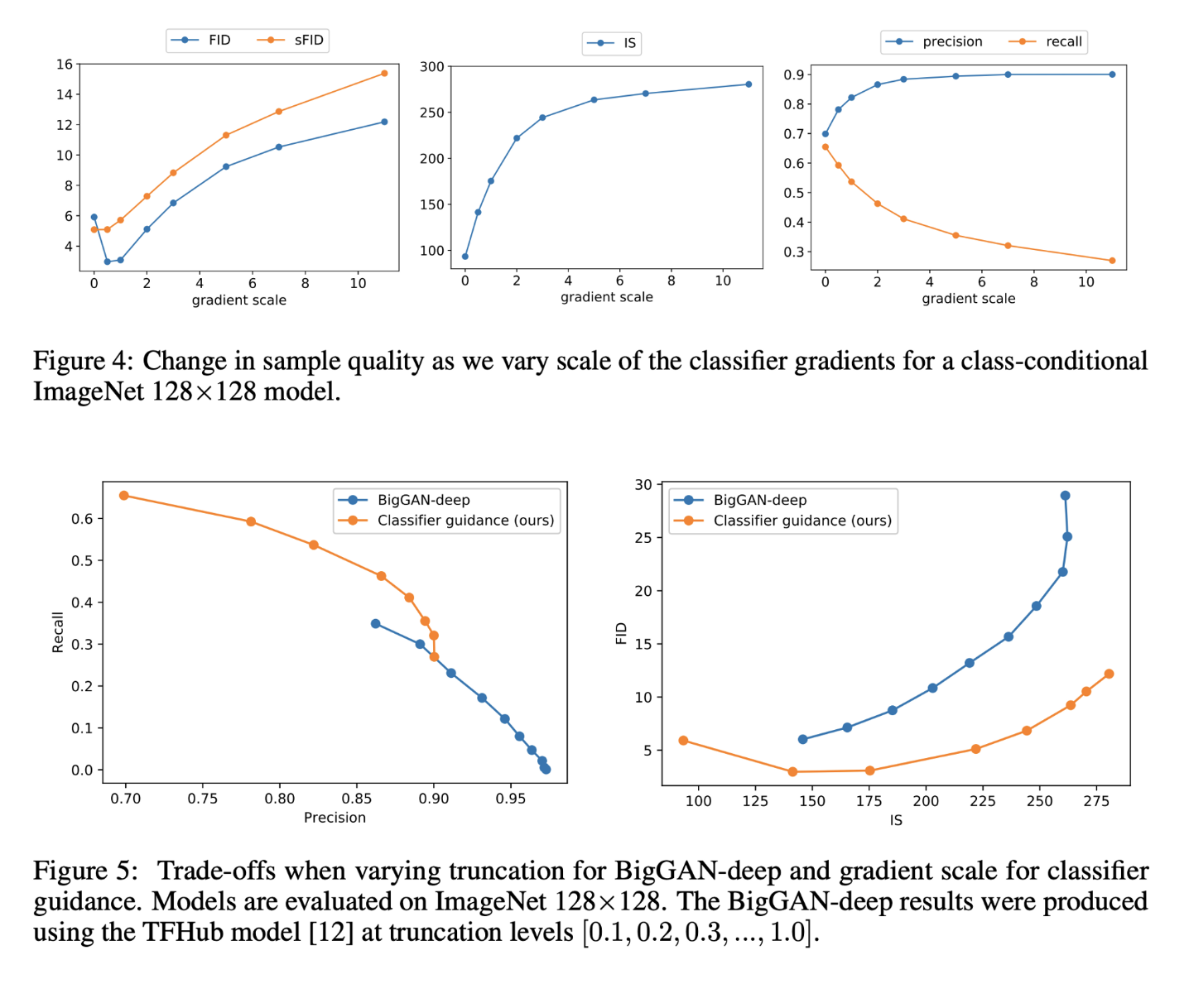
실험을 통해 classifier gradient의 scale을 1로 설정하면 50% 정도의 class에 알맞은 샘플을 생성하는 것을 확인하였으며 scale을 높일수록 class에 맞는 샘플을 생성하는 것을 발견하였다. [Figure 3]

수식을 통해 이를 설명할 수 있는데
s⋅∇xlogp(y|x)=∇xlog1Zp(y|x)s
Scale factor s를 높이는 것은 p(y|x)의 큰 값들을 지수적으로 증폭시키기 때문에 분포가 전체적으로 뾰족해진다. 즉, larger gradient scale을 사용하는 것은 classifier의 mode값에 focus하는 것으로 high fidelity, low diverse 샘플을 생성하도록 유도하는 것과 같다.
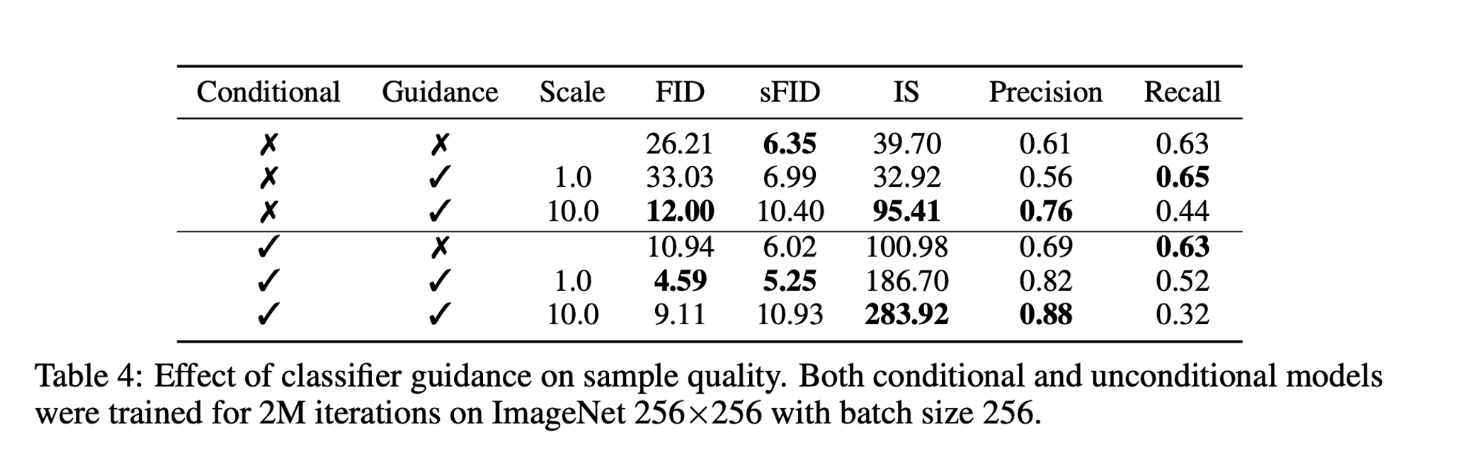
Classifier free guidance를 unconditional (AdaGN, concat 등으로 class label 정보를 전달하지 않은)모델에 적용하면 Conditional로 학습한 모델과 비슷한 성능을 낼 수 있음을 [Table 4]에서 볼 수 있으며, 하지만 여전히 class label 정보를 Unet에 전달하며 학습하는 Conditional 방식에 Guidance를 적용하는 것이 가장 성능이 좋음을 확인할 수 있다.
Gradient scale을 조정함으로써 GAN에서의 truncation과 같이 recall과 precision의 trade-off를 관리할 수 있다. [Figure 5]
5. Results
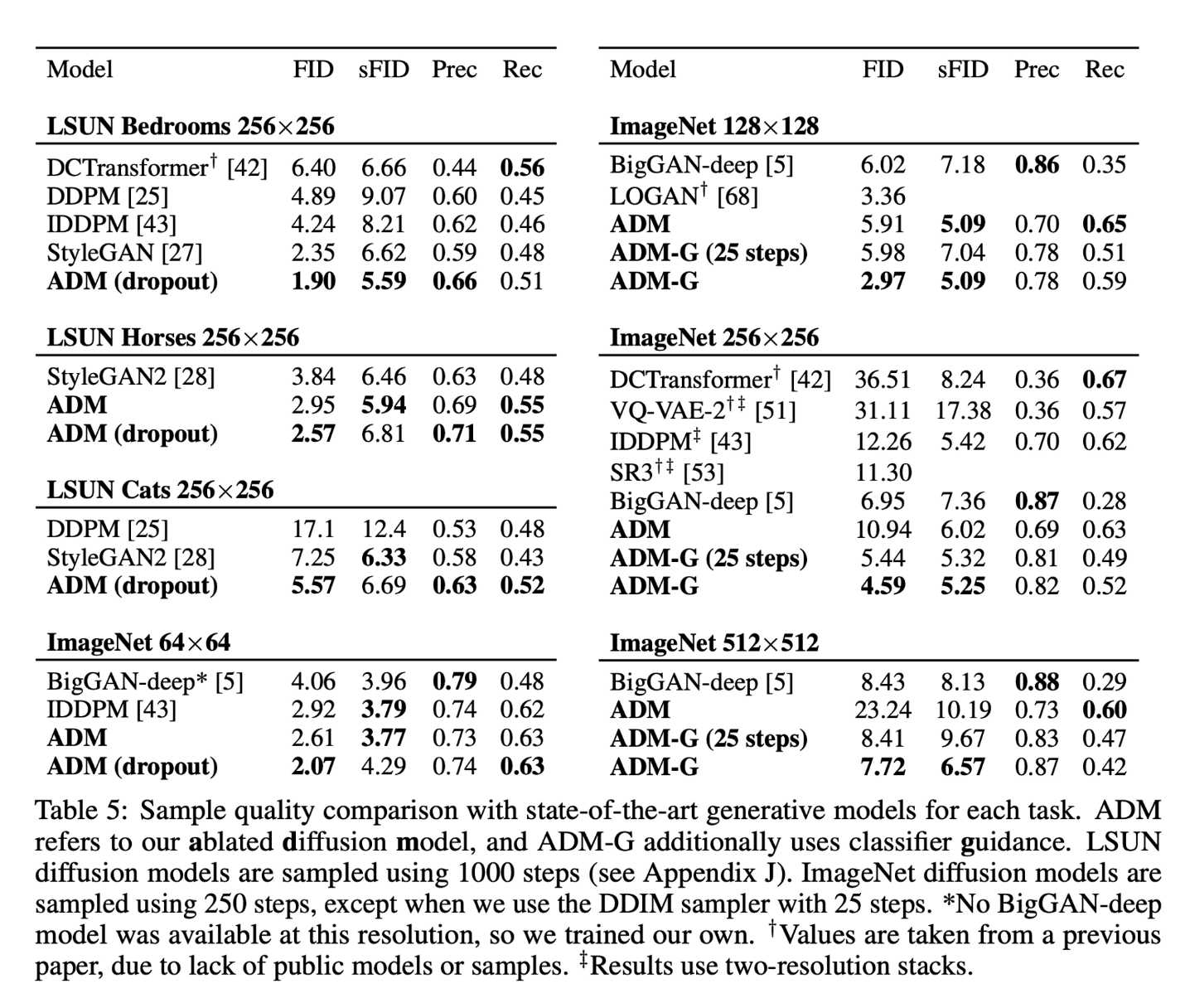
Ablated Diffusion Model(ADM)은 높은 FID를 보통 기록햇으며, Guidance가 추가되면 더 높은 FID, 낮은 Recall을 기록하였다. Upsampling에서는 128 res Diffusion에 Guidance를 적용하고 이를 interpolation하여 512 Diffusion에 condition으로 사용하는 Cascaded 방식이 가장 성능이 좋았다.
6. Limitations and Future Work
- 생성 속도에 대한 한계 여전히 존재
- labeled dataset에 한정된 Classifier Guidance 방식
- image label 뿐 아니라 text prompts 등에 사용
7. Conclusion
- GAN을 뛰어넘는 성능을 가진 Diffusion 모델을 Classifier Guidance, Model 아키텍처 수정으로 얻어냄
- Classifier Guidance로 GAN의 truncation과 같은 FID, IS trade-off 조절 능력을 갖추게 함
- Guidance를 upsampling에 사용하여 고화질 이미지 생성에서 샘플 퀄리티를 크게 끌어올림
후기 & 정리
- Classifier Guidance를 여러 세팅을 최적화하여 아키텍처를 개선한 Diffusion 모델에 사용하여 GAN의 FID를 뛰어넘는 성능을 달성
- Classifier Guidance는 auxiliary classifier과 같이 번거롭기 때문에 이후 나온 Classifier-free Guidance가 더 상용화 되었으나 제시한 모델 아키텍처는 이후로도 많이 참고되었음
- 발표되었을 때 제목이 흥미로워서 그런지 많은 사람들이 관심을 보였던 논문
- 최근에 Improved-DDPM, DDPM, ADM을 동일 데이터셋으로 특정 성능을 달성하는데 까지 wall-clock time을 측정해보았는데 ADM이 가장 우수하였음. (multi-resolution attention과 같은 연산으로 one iteration time은 증가)
Reference
[0] Prafulla Dhariwal, Alex Nichol, (2021), "Diffusion Models Beat GANs on Image Synthesis", https://arxiv.org/abs/2105.05233
Diffusion Models Beat GANs on Image Synthesis
We show that diffusion models can achieve image sample quality superior to the current state-of-the-art generative models. We achieve this on unconditional image synthesis by finding a better architecture through a series of ablations. For conditional imag
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| Score-Based Generative Modeling through Stochastic Differential Equations (0) | 2023.05.27 |
|---|---|
| Score-based Generative Models과 Diffusion Probabilistic Models과의 관계 (0) | 2023.05.16 |
| Improved-DDPM: Improved Denoising Diffusion Probabilistic Models (0) | 2023.04.19 |
| DDIM: Denoising Diffusion Implicit Models (0) | 2023.04.14 |
| Diffusion Model 수식 정리 (0) | 2023.04.08 |



