
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- cv
- 모션매칭
- Generative Model
- RNN
- motion matching
- Few-shot generation
- 생성모델
- WBP
- NLP
- dl
- ue5.4
- multimodal
- Diffusion
- deep learning
- BERT
- Unreal Engine
- 폰트생성
- 언리얼엔진
- 딥러닝
- ddpm
- GAN
- 오블완
- animation retargeting
- WinAPI
- UE5
- userwidget
- CNN
- 디퓨전모델
- Font Generation
- Stat110
Archives
- Today
- Total
Deeper Learning
Longformer: The Long-Document Transformer 본문
Iz Beltagy, Matthew E. Peters, Arman Cohan [Allen Institute for Artificial Intelligence, Seattle, WA, USA] (2020.04)
Abstract
- Transformer 기반 모델은 sequence 길이에 따라 quadratic 하게 증가하는 계산 복잡도를 가지는 self-attention 연산으로 인해 긴 sequence를 처리하지 못하였다
- sequence length에 따라 선형적으로 계산량이 증가하여 수천 개 이상의 토큰을 처리할 수 있는 Longformer를 제시
- Longformer의 attention 메커니즘은 drop-in replacement, local windowed attention
- text8, enwik8에서 SOTA를 달성
- 다양한 downstream task에서 fine-tuning 하여 RoBERTa를 long document tasks에서 뛰어넘고 SOTA를 달성 (WikiHop, TriviaQA)
- long document 생성 seq2seq task를 위해 Longformer를 변형한 Longformer-Encoder-Decoder(LED)를 제시
1. Introduction
- Transformer는 문맥 정보를 파악하는 self-attention을 사용하여 NLP에서 좋은 성능을 내지만 sequence length에 따라 증가하는 계산량과 메모리가 문제
- long document를 사용하는 QA, classification 등 task는 BERT style의 512 token limit에 의해 중요 정보가 손실되어 성능이 저하되곤 한다

- Transformer를 개선하여 long sequence 처리를 시도한 최신 연구들은 autoregressive language modeling에만 집중하였고 transfer learning에 대한 연구는 아직 진행되지 않았음
- Longformer는 windowed local-context self-attention과 task에 대한 inductive bias를 encode 하는 end task motivated global attention의 조합
- 먼저 Longformer를 windowed + dilated attention을 사용하여 autoregressive character-level LM을 학습하여 32K character의 sequence를 학습에 대해 평가
- text8, enwik8 데이터셋 벤치마크 SOTA 달성
- long document 모델링에 대한 Longformer의 성능 증명
- 후에 기존 학습된 모델의 full self-attention을 Longformer가 대체할 수 있다는 것을 보이기 위해 RoBERTa에 checkpoint에 이어서 추가 pretrain
- fine-tuning 하고 RoBERTa와 document-level nlp task에 대한 결과를 비교
- QA, text classification, coreference resolution task에 대해 2개의 데이터셋에서 SOTA를 달성
- Transformer의 encoder만 사용하는 Longformer를 변형하여 encoder-decoder 구조를 가지는 Longformer-Encoder-Decoder(LED)를 소개
2. Related Work
Long-Document Transformers
- left-to-right 접근법은 autoregressive language modeling 측면에서 성공적이었지만 양방향 context의 정보에서 이점을 얻는 몇몇 task에 대해 적합하지 않았음
- quadratic attention matrix multiplication을 피하기 위한 sparse attention
Task-specific Models for Long Documents
- 기존 방식은 truncating, chunking을 사용하여 정보 손실의 문제가 있었음
- Longformer처럼 local + global attention 방식을 시도한 ETC(Ainsile et al., 2020)
- relative position embedding 사용
- CPC loss 도입
- Longformer와 조금 다른 방식의 global attention
- GMAT(Gupta and Berant, 2020)도 global memory를 활용
- BigBird(Zaheer et al., 2020)
- Longformer 논문 v1 이후 v2 이전 공개된 논문 (2020.05)
- 계산량이 Longformer보다 많지만 4096 max-seq-len 기준 Longformer보다 좋은 성능을 보임
- Sparse Transformer가 sequence function의 universal approximators라는 것을 보임
3. Longformer
3.1. Attention Pattern
Sliding Window
- local context의 중요성을 고려해서 fixed-window attention을 사용
- 여러 layer를 쌓아 large receptive field
- input sequence length가 n, window size가 w일 때 O(n * w)의 계산 복잡도
- l개의 transformer layer를 쌓으면 w×l의 receptive field를 가짐
- 실제 사용할 때는 모델의 효율성과 receptive field trade-off를 w를 조절하여 조정
Dilated Sliding Window
- d 만큼의 간격을 두고 window를 sliding하는 방식
- l×d×w의 receptive field
- multi-headed attention에서 각 attention head에 다른 dilation 설정을 적용하면 d가 작을수록 local-context에 집중하고 d가 크면 더 긴 context에 집중하도록 하는 효과가 있어 성능향상
Global Attention
- BERT-style 모델의 방식
- dilated window attention의 경우 task에 알맞은 representation을 학습할 만큼 flexible하지 않아 추가로 지정한 input location에 global attention 정보를 추가로 제공
- sequence의 모든 token은 global attention 정보를 포함하도록 지정한 token에게 attention (Figure 2d 참고)
- classification task에서는 [CLS] token에 global attention 사용, QA task에서는 모든 question token에 사용
- task에 알맞은 inductive bias를 model attention 방식에 주입하는 비교적 쉬운 방식
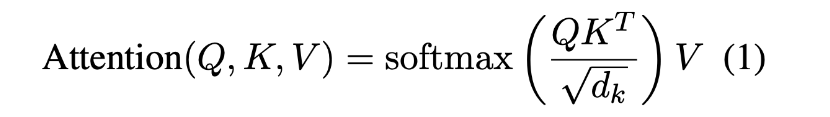
- original Transformer에서는 아래와 같이 attention score를 계산하지만 Longformer는 Qs,Ks,Vs로 sliding window attention score를 계산하고 Qg,Kg,Vg로 추가로 global attention score를 계산
3.2. Implementation
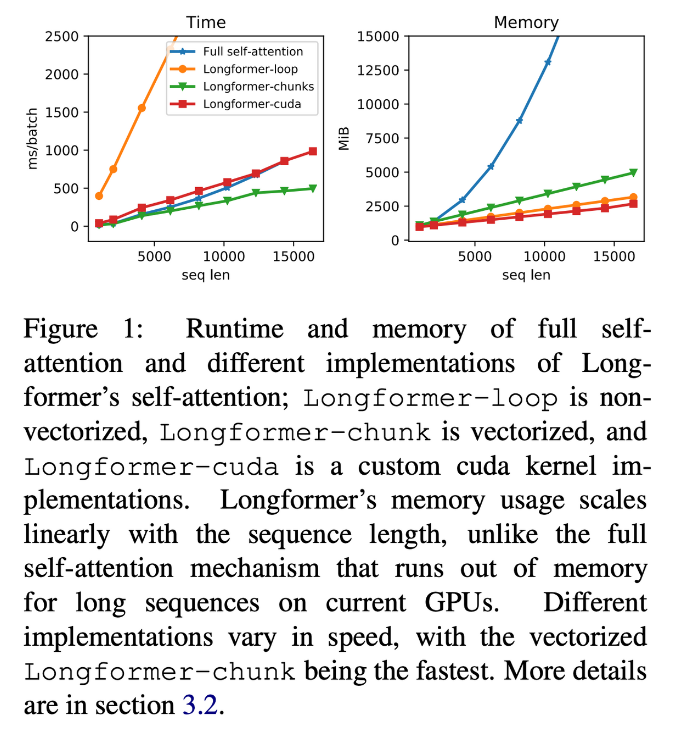
- Transformer에서 QKT 연산은 둘 다 길이가 sequence length n과 같아 quadratic 하게 메모리 사용량이 증가
- Longformer에서는 dilated window sliding을 사용하여 linear 하게 메모리 사용량이 증가 (Figure 1 참고)
- 하지만 TF, Pytorch 등 딥러닝 라이브러리에서 banded matrix multiplication을 지원하지 않기 때문에 여러 방식으로 구현하고 성능을 비교하였음 (자세한 구현은 Appendix A 참고)
- loop 방식은 메모리 효율적인 Pytorch 구현이지만 느리며 test에만 사용
- chunks 방식은 non-dilated case에만 적용 가능하며 pretraining/finetuning 모두 가능
- cuda 방식은 커스텀 TVM을 사용해 CUDA kernel을 적용
4. Autoregressive Language Modeling
4.1. Attention Pattern
- lower layer에 small window size, higher layer에 large window size로 세팅하여 초기 layer에서 local 정보를 top layer에서 전체 sequence의 고수준의 representation을 학습할 수 있도록 함
- lower layer에서는 local context를 즉각 학습하도록 dilated sliding window를 사용하지 않았으며 higher layer에서는 2개의 heads에만 점차 큰 dilation을 적용하여 모델이 local context를 희생하지 않으며 먼 token에 직접 집중할 수 있도록 함
4.2. Experimental Setup
- local context를 먼저 학습하기 위해 많은 gradient update가 필요해 sequence length와 window size를 stage 마다 2배로 늘리고 lr을 반으로 줄이며 학습하는 staged learning을 사용
- sequence length 2048으로 시작해서 sequence length 23040까지 학습 (자세한 설정은 Appendix B 참고)
- 평가는 마지막 512 tokens의 점수로 평가
4.2.1. Results
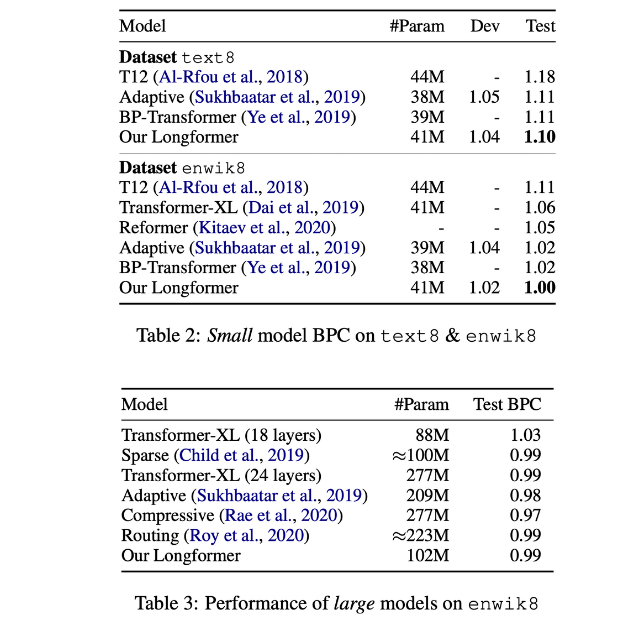
- Small model에서 text8, enwik8 요약 task 모두 SOTA 달성
- large model도 transformer-XL을 뛰어넘는 성능을 보임
- Adaptive Span, Compressive Transformer는 pretraining-finetuning 패러다임에 적합하지 않은 모델
4.2.2. Ablation Study

- bottom layer에서 top layer로 갈수록 window size를 증가시키는 세팅이 가장 좋은 성능을 보임
- 2개 head에 dilation을 적용하면 더 좋은 성능을 보임
5. Pretraining and Finetuning
- 많은 NLP task에서 pretrained 모델을 finetuning 하였을 때 가장 좋은 성능을 기록
- 4096 tokens까지 다룰 수 있는 Longformer를 Masked language modeling(MLM)으로 학습
- MLM pretraining은 비용이 크기 때문에 공개된 RoBERTa를 Longformer에 알맞은 설정을 추가하여 이어서 학습
Attention Pattern
- window size 512
Position Embeddings

- RoBERTa는 최대 512 position의 absolute position embedding을 사용
- 4096 position을 커버하기 위해 pretrained RoBERTa의 position embedding을 복사하여 4096 position을 채움
- BERT 논문에서 position embedding이 local context에 집중하도록 학습되는 강력한 bias가 있다는 것을 보여주었기 때문에 이를 활용하기 위해 경계를 제외하고 pretrained position embedding을 그대로 사용
- 간단하게 pretrained position embedding을 그대로 가져왔음에도 수렴이 매우 빨라지는 효과를 볼 수 있음
Continued MLM Pretraining
- 4096 max sequence length, batch size 64로 학습
- 500 step linear lr warmup, 3 제곱의 polynomial decay 사용
- sliding window attention과 longer context를 활용하여 RoBERTa를 이어 학습한 Longformer의 성능이 향상되었음
Frozen RoBERTa Weights
- RoBERTa의 weight를 고정하고 position embedding만 학습하였을 경우, 모든 layer의 weight를 학습한 것보다 성능 향상 정도가 적었음
6. Tasks
6.1. Question answering
- WikiHop, TriviaQA, HotpotQA 사용
- question과 answer를 이어서 sequence 구성
- global attention은 question token과 answer candidates에 사용
6.2. Coreference Resolution
- OntoNotes 사용
- global attention을 사용하지 않음
6.3. Document Classification
- IMDB, Hyperpartisan news detection 사용
- [CLS] token에 global attention 사용
6.4. Results

- 모든 데이터에서 RoBERTa-base보다 좋은 성능을 보임
- 긴 문맥 파악이 필요한 WikiHop, Hyperpartisan에서 성능 향상이 두드러짐
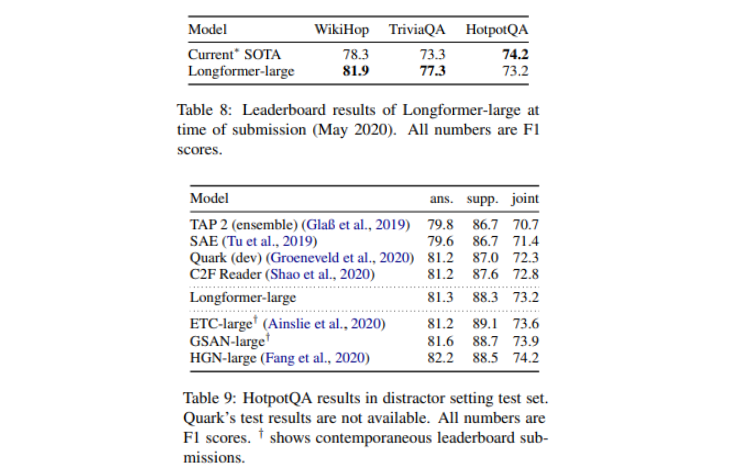
- Longformer-large는 WikiHop, TriviaQA에서 SOTA를 달성
- HotpotQA에서는 강한 task specific inductive bias가 주입된 graph 구조의 HGN을 넘지 못함
6.5. Ablations on WikiHop
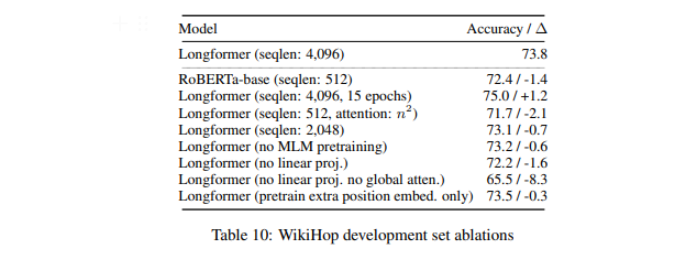
- RoBERTa와 같은 seqlen, attention으로 학습하면 오히려 성능 저하가 된 것을 보아 Longformer의 성능 향상이 단순히 더 긴 학습에서 기인한 것이 아니라는 것을 증명
- position embedding만 학습시켜도 나쁘지 않은 성능으로 task specific fine-tuning 통해 long range context를 활용하는 법을 배운다는 것을 알 수 있음
7. Longformer-Encoder-Decoer (LED)
- seq2seq에서 long sequence를 처리할 수 있도록 Longformer의 변형 LED를 제시
- encoder decoder에 모두 Longformer의 효율적인 local+global attention 패턴을 사용
- decoder는 encoded token 전체에 full self-attention 연산
- LED는 BART의 pretrained parameters에서 시작
- BART와 다른 설정은 1K token에서 16K token에 대응하도록 position embedding을 16번 복사하여 확장
- arXiv summarization dataset에서 요약 성능 평가
- LED의 encoder는 window size 1024 tokens, 첫 <s> token에 global attention 사용
- LED의 decoder는 encoder 전체와 decoder의 직전 position에 full attention
- inference에 beam search 사용
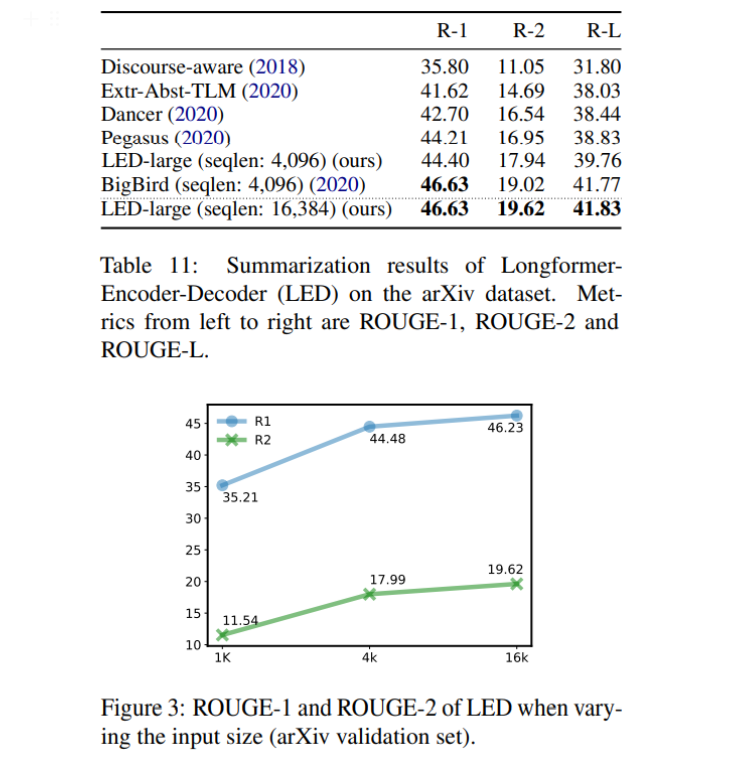
- arXiv에서 BigBird를 뛰어넘으며 SOTA 달성 (v2)
- BigBird는 4K sequence length 학습이 가능하며 summarization을 위해 학습된 Pegasus에 이어 학습한 모델
- Figure 3은 long sequence를 처리할 수 있으면 arXiv에서 성능이 증가한다는 것을 보여주는 그림
8. Conclusion and Future Work
- chunking, shortening 없이 long document의 정보를 처리할 수 있고 scalable한 간단한 transformer 기반 모델 Longformer를 제시
- local, global 정보를 조합하는 attention pattern 사용하여 sequence length에 따라 복잡도가 선형적으로 증가
- text8, enwik8에서 character-level LM SOTA 달성
- RoBERTa에 이어 학습하여 WikiHop, TriviaQA에서 SOTA 달성
- seq2seq task를 위한 Longformer인 LED를 제시
- LED는 arXiv long document 요약 task SOTA를 달성
- 다른 pretraining objectives, sequence length 늘리기, Longformer로 성능이 향상하는 다른 task 탐색을 future work으로 제시
후기 & 정리
- 기존 Transformer base 모델은 연산, 메모리의 한계로 long document 처리를 하기 쉽지 않았음
- local, global 정보를 조합하는 attention 패턴을 사용, sequence length에 따라 선형적으로 scaling이 가능한 Longformer를 제시
- text8, enwik8, WikiHop, TriviaQA에서 SOTA 달성
- seq2seq task를 위한 LED 제시
- 아이디어도 간단하고 여러 long context가 필요한 task의 경우 성능 향상 또한 성공
- 다른 downstream task에서도 long context를 다룰 수 있는 Longformer가 좋은 성능을 기록할지 궁금함
- 추후에 BigBird도 다시 정독하고 비교할 계획
Reference
[0] Iz Beltagy et al.(2020)."Longformer: The Long-Document Transformer".https://arxiv.org/abs/2004.05150
Longformer: The Long-Document Transformer
Transformer-based models are unable to process long sequences due to their self-attention operation, which scales quadratically with the sequence length. To address this limitation, we introduce the Longformer with an attention mechanism that scales linear
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more




Comments