
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- WinAPI
- deep learning
- motion matching
- 오블완
- Diffusion
- CNN
- multimodal
- userwidget
- dl
- 폰트생성
- 모션매칭
- BERT
- animation retargeting
- Few-shot generation
- 생성모델
- Generative Model
- Stat110
- 언리얼엔진
- ddpm
- NLP
- WBP
- ue5.4
- cv
- UE5
- RNN
- Unreal Engine
- Font Generation
- 디퓨전모델
- 딥러닝
- GAN
Archives
- Today
- Total
Deeper Learning
DeBERTa: Decoding-enhanced BERT with Disentangled Attention 본문
AI/Deep Learning
DeBERTa: Decoding-enhanced BERT with Disentangled Attention
Dlaiml 2022. 7. 2. 16:17Pengcheng He, Xiaodong Liu, Jianfeng Gao, Weizhu Chen, [Microsoft Research, Microsoft Dynamics 365 AI] (2020.06)
Abstract
- 두 새로운 테크닉으로 BERT, RoBERTa를 향상한 새로운 모델 아키텍처 **DeBERTa(Decoding-enhanced BERT with disentangled attention)**을 제시
- 첫 번째 테크닉은 disentangled attention mechanism
- 각 단어는 content와 position을 각각 encode하는 2개의 벡터로 표현
- 단어끼리의 attention weight 또한 content, relative position 각각에 disentangled matrices를 사용하여 계산
- 두 번째 테크닉은 enhanced mask decoder
- decoding layer의 absolute position을 포함하여 모델 pre-train 단계에서 masked token을 예측
- 새로운 virtual adversarial training를 사용하여 fine-tuning 하여 모델의 일반화 성능 향상
- 제시한 테크닉들을 사용하여 모델의 pre-training 효율과 natural language understand(NLU), natural language generation(NLG) downstream task에서 성능을 향상
- RoBERTa-Large보다 MNLI에서 0.9%, SQuAD 2.0에서 2.3%, RACE에서 3.6% 높은 점수를 기록
- 48 Transformer layers, 1.5B parameters로 DeBERTa를 scale up하여 SuperGLUE marcro-average score 기준 처음으로 human performance를 넘어섬 (DeBERTa: 89.9, Human level performance: 89.8)
- DeBERTa 모델을 앙상블 한 결과, 2021년 1월 6일 기준 human baseline을 상당한 차이로 능가하며 SuperGLUE 리더보드 최상위를 차지 (ensembled DeBERTa: 90.3, HLP: 89.8)
- pre-trained DeBERTa 모델과 source code를 공개 https://github.com/microsoft/DeBERTa
GitHub - microsoft/DeBERTa: The implementation of DeBERTa
The implementation of DeBERTa. Contribute to microsoft/DeBERTa development by creating an account on GitHub.
github.com
1. Introduction
- 이전 SOTA PLM(pretrained Language Model)을 개선한 새로운 Transformer 기반 neural language model DeBERTa(Decoding enhacned BERT with disentangled attention)을 제시
- Disentangled attention
- BERT는 input layer에서 각 word가 content embedding + position embedding으로 표현됨
- DeBERTa에서는 각 word가 content embedding, position embedding 2개의 벡터로 표현됨
- attention weight도 content, position에 따라 disentangled된 matrices를 사용하여 계산
- word pair의 attention weight는 content 뿐만 아니라 두 word의 relative position에도 영향을 받는다는 실험 결과에서 영감을 얻음
- 예시로 deep, learning 이라는 두 단어는 연속적으로 위치할 경우 더 강한 dependency를 보임
- Enhanced mask decoder
- disentanlged attention은 context word의 content와 relative position을 고려하지만 absolute position은 고려하지 않음
- “a new store opened beside the new mall” 문장에서 store, mall이 masking 되었다고 하면 두 단어의 local context는 매우 비슷하나 문장에서 다른 문법적 역할을 담당 (store는 주어)
- 문법적 뉘앙스는 단어의 절대적인 position에 크게 의존하기 때문에 language modling 과정에서 단어의 absolute postiion을 다루는 것이 중요함
- DeBERTa는 softmax layer 바로 앞에서 absolute word position embedding을 결합
- downstream fine-tuning을 위한 새로운 virtual adversarial training 방식을 제시하여 모델의 일반화 성능을 향상
- 실증적 실험으로 제시한 방식들이 pre-training의 효율과 downstream task에서 성능을 향상시킴을 확인
- RoBERTa-Large보다 MNLI에서 0.9%, SQuAD 2.0에서 2.3%, RACE에서 3.6% 높은 점수를 기록하고 scale up, ensemble을 통해 SuperGLUE benchmark에서 human performance를 처음으로 넘어섬
2. The DeBERTa Architecture
2.1 Disentangled Attention: A Two-Vector Approach to Content and Position Embedding
- i position의 token은 content vector Hi, relative position vector Pi|j로 표현할 수 있다 (j는 다른 token의 position)
- position i와 j의 token의 cross attention score는 아래와 같이 4개의 component로 나누어 계산할 수 있다

- 4개의 항은 순서대로 content-to-content, content-to-position, position-to-content, position-to-position
- relative position embedding을 사용하기 때문에 position-to-position은 많은 추가 정보를 제공하지 못하여 제거
- single-head self-attention은 수식은 아래와 같이 표현할 수 있음
- H∈RN×d, Wq∈Rd×d, A∈Rd×d, HN×do, N은 input sequence length, d는 hidden dimension
- k가 maximum relative distance일 때 i와 j position token의 relative distance는 아래 수식으로 계산 (δ(i,j)∈[0,2k))
- relative position bias를 사용하는 disentangled self-attention도 single-head self-attention을 표현했던 방식으로 표현해보면 아래와 같다
- Qc,Kc,Vc는 각각 projection matrices Wq,c,Wk,c,Wv,c∈Rd×d를 사용하여 계산
- P∈R2k×d는 모든 layers에서 공유하는 relative position embedding vectors
- ˜Ai,j는 attention matrix ˜A의 element로 token i와 token j의 attention score를 표현
- Qci는 Qc의 i번째 row, Qrδ(j,i)은 Qr의 relative distance δ(j,i) 번째 row

2.1.1 Efficient Implementation
- length N의 input sequence는 각 token의 relative position embedding을 저장하기 위해 space complexity O(N2d)를 요구
- 하지만 content-to-position을 보면 δ(i,j)는 2k 미만, 가능한 모든 relative position은 Kr∈R2k×d의 subset이기 때문에 모든 query에 대한 attention 계산에서 Kr을 재사용할 수 있다
- 모든 query에 relative position을 할당하지 않고 relative position embedding δ를 index처럼 활용하여 저자는 O(kd)로 space complexity를 줄일 수 있었다
2.2 Enhanced Mask Decoder Accounts for Absolute Word Positions
- 앞서 언급하였듯이 absolute position은 language model에 있어서 중요하다 (주어는 앞, 목적어는 뒤와 같이 absolute position을 통해 얻을 수 있는 정보가 있음)
- BERT는 absolute position을 input layer에서 다루고 (position embedding을 add) DeBERTa는 absolute position을 Transformer layers와 softmax layer 사이에서 다룬다
- DeBERTa는 relative position을 모든 Transformer layers에서 capture하고 absolute position은 masked word로 decoding할 때 추가 정보로 처리
- 저자는 DeBERTa의 decoding component를 Enhanced Mask Decoder(EMD)로 부름
- 저자는 실험을 통해 EMD가 더 성능이 좋음을 확인
- 추가로 BERT의 이른 absolute position의 처리는 모델이 충분한 relative position 정보를 학습하는것을 방해한다는 추측을 하였음
3. Scale Invariant Fine-Tuning
- 새로운 가상의 adversarial training 알고리즘인 Scale-invariant-Fine-Tuning(SiFT)를 제시
- 이전의 virtual adversairal training은 word embedding에 perturbation을 주어 모델을 regularize하는 방식이었으나 embedding vector의 경우 모델과 word에 따라 값의 범위가 매우 다양하기 때문에 adversarial 학습을 불안정하게 하였음
- layer normalization에서 영감을 받아 normalized word embedding에 perturbation을 적용하는 SiFT는 학습의 안정성을 개선하였음
- downstream NLP task에 fine-tuning 할 때 word embedding vectors먼저 stochastic vectors로 normalize하고 perturbation을 적용
- 더 큰 DeBERTa 모델에서 성능 개선이 뚜렷하였으며 DeBERTa 1.5B SuperGLUE task에만 SiFT를 적용하였음
4. Experiment
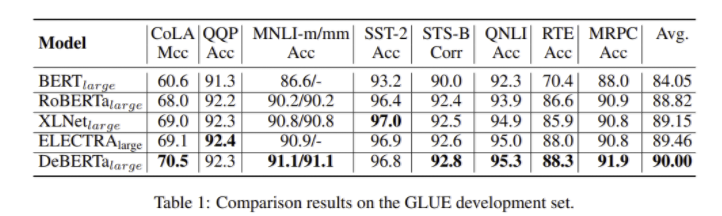
- RoBERTa의 BPE를 사용한 것을 제외하고는 Original BERT의 세팅을 따랐음
- Wikipedia, BookCorpus, OPENWEBTEXT, STORIES 데이터셋을 사용 (78G)
- XLNet, RoBERTa는 160GB의 데이터로 학습
- DeBERTa는 SOTA PLM을 뛰어넘는 성능을 달성

- SQuAD, RACE, ReCoRD, SWAG, CONLL 2003 NER 에서도 SOTA를 달성
- Base 모델 사이즈에서도 다른 모델보다 좋은 성능을 보임
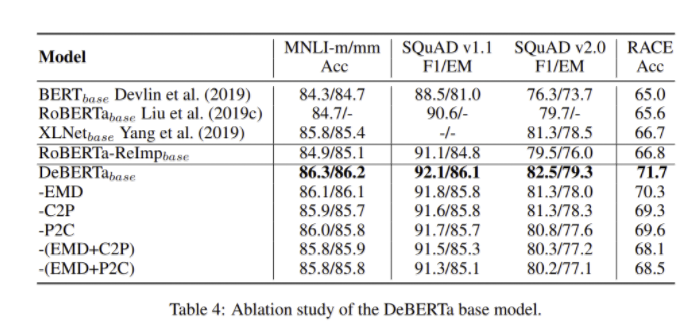
- C2P(content-to-position term), P2C(position-to-content term)을 제거할 경우 성능이 크게 하락
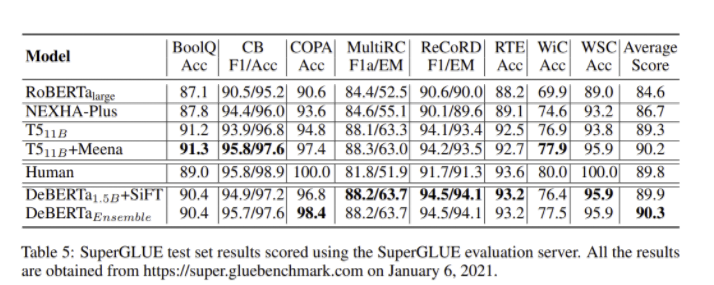
- DeBERTa 1.5B + SiFT는 SuperGLUE marco avg score 기준 Human performance를 넘어섬
5. Conclusions
- BERT와 RoBERTa를 2가지 새로 제시한 테크닉을 사용하여 개선한 DeBERTa를 제시
- content와 position을 각각 encoding하는 disentangled attention
- absolute position을 decoding layer에서 통합하는 enhanced mask decoder
- 새로운 virtual adversarial training method를 제시
- SuperGLUE에서 human performance를 능가하여 general AI로 향하는 중요한 마일스톤을 세움
- SuperGLUE에서 human level을 달성한 것이 human-level의 자연어 이해 지능을 가졌다는 것을 뜻하지는 않는다
- 인간은 여러 task에서 얻은 지식을 활용하여 task-specific demonstration이 거의 주어지지 않은 새로운 task를 해결하는데 매우 뛰어난 compositional generalization 특성을 가지고 있음
- 모델도 compositional generalization을 가지도록 structures를 개선하는 것을 NLP의 후속 연구로 제시
후기 & 정리
- content, position embedding을 명시적으로 분리하여 encoding하는 disentangled attention, absolute position을 softmax layer이전에 feed하는 enhanced mask decoder를 사용하여 BERT, RoBERTa를 개선한 DeBERTa를 제시
- normalized word embedding에 perturbation을 적용하는 SiFT를 제시
- DeBERTa 1.5B+SiFT는 SuperGLUE에서 Human level performance를 능가
- 새롭게 제시한 테크닉과 그에 대한 설명이 자세하게 되어있어서 재미있었던 논문
- absolute position의 중요함을 예시를 들어 설명한 부분, Conclusion에서 인간의 NLU 능력에 대해 설명하며 이를 기반으로 Future work을 제시한 것이 매우 흥미로웠음
- T5 11B를 능가한 DeBERTa 1.5B. T5 다음으로는 더 큰 모델이 나와야 SOTA를 달성할 수 있을 것이라 생각하였는데 의외였음 (하지만 최근 연구는 초거대모델인 280B Gopher, 540B PaLM)
Reference
[0] Pengcheng He et al. (2020). "DeBERTa: Decoding-enhanced BERT with Disentangled Attention". https://openreview.net/forum?id=XPZIaotutsD
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more



