
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오블완
- UE5
- 딥러닝
- 디퓨전모델
- dl
- 생성모델
- 모션매칭
- ddpm
- BERT
- multimodal
- Font Generation
- WinAPI
- NLP
- 언리얼엔진
- cv
- Unreal Engine
- userwidget
- GAN
- 폰트생성
- Few-shot generation
- Diffusion
- Stat110
- RNN
- CNN
- deep learning
- Generative Model
- ue5.4
- animation retargeting
- motion matching
- WBP
- Today
- Total
Deeper Learning
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations 본문
M3AE: Multimodal Masked Autoencoders Learn Transferable Representations
Dlaiml 2022. 6. 11. 01:12Xinyang Geng, Hao Liu, Lisa Lee, Dale Schuurmans, Sergey Levine, Pieter Abbeel, [UC Berkeley, Google Brain] (2022.05.31)
Abstract
- 다양한 multimodal data를 학습하는 scalable 모델을 만드는 것은 아직까지 어려움이 많다
- vision-language data에서 주된 접근법은 modality 마다 separate encoder를 학습하는 contrastive learning
- contrastive learning은 효율적이지만, 사용한 data augmentation에 따른 sampling bias로 downstream task에서 성능이 감소하는 문제가 존재
- contrastive learning은 paired image-text만 사용가능하며 unpaired data를 사용할 수 없는 문제가 존재
- 특정 modality를 위한 encoder, contrastive learning을 사용하지 않고 downstream task로 전이가 가능한 representation을 masked token prediction으로 학습하는 방법을 제시
- masked token prediction를 통해 하나의 encoder로 vision, language data를 모두 학습하는 간단하고 scalable 네트워크 아키텍처인 **Multimodal Masked Autoencoder(M3AE)**를 제시
- 실험을 통해 M3AE를 large-scale image-text 데이터셋으로 학습시키면 일반화 가능한 representation을 학습할 수 있음을 발견 (downstream task에서 좋은 퍼포먼스)
- 놀랍게도 BERT는 15%의 masking ratio를 사용한 것과 달리 M3AE는 두 data modalities joint training으로 인해 높은 mask ratio(50~90%)에서 좋은 성능을 보였다
- M3AE가 image, language의 의미있는 정보를 포함하는 representation을 학습한 것을 분석하였음
- M3AE의 scalability를 larger model size, training time을 통해 입증
- M3AE는 paired image-text data로도 학습 가능한 flexibility 또한 가지고있음
1. Introduction
- neural 아키텍처, 하드웨어 성능의 빠른 발전으로 NLP, Vision에서 self-supervised pretraining은 엄청난 발전을 이루었다 (Masked autoencoders, Bert, Beit, Language models are few-shot learners)
- masked token prediction이라고 불리는 근본적인 아이디어는 간단하다
- data의 제거된 부분을 예측하도록 모델을 학습시킴
- Masked token prediction은 vision과 NLP에서 성공적인 pre-training을 가능케 하였다 (Transformer, GPT, BERT, MAE)
- Masked token prediction으로 학습된 pre-trained representations은 다양한 downstream task로의 일반화 성능이 뛰어남
- 이러한 성공의 초석은 많고 다양한 데이터를 훌륭하게 활용하는 것
- 실제로 data diversity, model capacity를 scale up 하여도 다양한 downstream task 성능에서 plateau가 나타나지 않았음
- image와 text로 구성된 다양하고 큰 multimodal 데이터셋으로 학습하여 visual representation 학습을 개선하는 데 관심이 쏠림
- CC12M, YFCC100M과 같은 데이터셋은 ImageNet과 같이 label이 지정된 데이터셋보다 확장성이 좋으며 다양한 language 데이터는 더 일반화된 representation을 학습하기 위한 풍부한 supervision 제공
- CLIP과 ALIGN과 같은 cross-modal contrastive learning이 multimodel pre-training에서 주된 패러다임
- 거대한 paired image-text을 사용하고 cross-modal contrastive learning으로 학습한 모델은 다양한 downstream task에 일반화를 할 수 있지만, paired image-text data를 요구하고 unpaired data를 사용할 수 없는 문제 존재
- contrastive learning 기반 방식은 image와 text가 나누어진 다른 encoders를 사용하는데 이는 model이 다른 modalities에 동시에 접근하기 어렵게 하며 image와 text의 joint understanding을 방해하는 문제 존재
- 위의 문제를 해결하기 위해 modality-specific encoder, contrastive learning을 사용하지 않고 간단하며 확장성 있는 M3AE를 제시
- MAE(Masked Autoencoders)를 기반으로 하는 M3AE는 오직 masked token prediction으로만 학습
- image-text pair를 긴 image patches와 text로 이루어진 긴 token sequence로 여기고 input image의 random patches 또는 language token을 masking하고 모델은 이를 reconstruct 하도록 학습
- CC12M으로 pre-training한 M3AE는 ImageNet으로 pre-training한 MAE보다 ImageNet-1k linear classification benchmark에서 좋은 성능을 보임
- datasets 간 전이가능한 representations을 학습하기 위한 multimodal training의 일반화 측면에서 장점
- M3AE는 75%의 높은 mask ratio를 적용하였을 때 가장 좋은 성능을 보여주었으나 BERT와 같은 언어모델은 보통 15% 정도의 낮은 mask ratio를 사용하는데 이는 language data가 매우 semantic하고 information-dense하기 때문이다
- 저자는 높은 mask ratio가 vision과 language의 joint understanding을 강제하기 때문에 M3AE가 higher mask ratio에서 좋은 성능을 기록했을 것이라는 가설을 세움
2. Related work
- Self-supervised representation learning via reconstruction
- BERT, GPT, MAE
- Self-supervised representation learning via contrastive objectives
- SimCSE, SimCLR
- Joint learning for language and image
- CLIP, BLIP, SLIP, FLAVA, Perceiver, CoCa
3. MultiModal Masked Autoencoder (M3AE)
image와 language를 representation space로 매핑하는 encoder, representation에서 본래 image, language를 reconstruction하는 decoder로 구성된 multimodel masked autoencoder(이하 M3AE)를 소개

Image-language masking
- M3AE의 첫 단계는 image와 language를 하나의 sequence로 결합하는 것
- language는 nlp의 정석을 따라 discrete tokens으로 tokenize
- image는 ViT의 방식을 따라 겹치지 않는 image patches를 사용
- image patches와 text tokens을 concatenate하여 single sequence 구성
- patches와 tokens에 대해 uniform distribution에서 비복원 추출로 random subset을 샘플링하고 남은 것들을 masking
- high masking ratio를 text tokens과 image patches에 모두 적용
- 정보 중복을 제거
- 단순하게 이웃 patches나 tokens의 extrapolation으로 해결할 수 없는 어려운 task를 만들기 위함
M3AE encoder
- M3AE의 Encoder는 ViT, BERT의 구조를 따르는 large Transformer
- encoder는 unmasked tokens만 input으로 받음 (Figure 1 참고)
- language token의 경우 embedding vectors로 변환하고 1D positional encodings을 적용 (BERT의 방식)
- image patches는 linear projection을 통해 language embedding과 같은 차원을 가지도록 하고 2D positional encodings을 적용 (MAE의 방식)
- modality를 구분하기 위해 modality type encodings을 추가
- 학습 가능한 CLS embedding 또한 sequence 가장 앞에 붙임
- input sequences가 매우 길지만 masking되지 않은 작은 subset에서만 연산이 이루어지기 때문에 효율적으로 large Transformer를 학습시킬 수 있다
M3AE decoder
- MAE를 따라 lightweight Transformer-based decoder를 사용
- M3AE decoder의 input은 encoded visible image patches, encoded visible text tokens, mask tokens으로 이루어진 sequence
- mask token은 모두 공유되는 학습 가능한 벡터
- mask token은 공유되는 벡터로 여러 mask token을 구분하기 위한 위치 정보를 positional embedding을 사용하여 제공
- encoder와 동일하게 modality type embedding을 추가
- decoder Transformer를 통과하고 난 후 reconstruction을 위해 2개의 linear projection output head를 적용
- image output head는 decoder output를 원래 image patches와 동일한 size로 project
- language output head는 decoder output을 token logits으로 project
Self-supervised training of M3AE
- M3AE는 pixel value와 token probabilities를 예측하여 input의 image와 language를 재구성
- image reconstruction은 pixel space의 mean squared error로 학습
- language reconstruction은 cross entropy loss로 학습 (image, text 모두 masked token에서만 loss 계산)
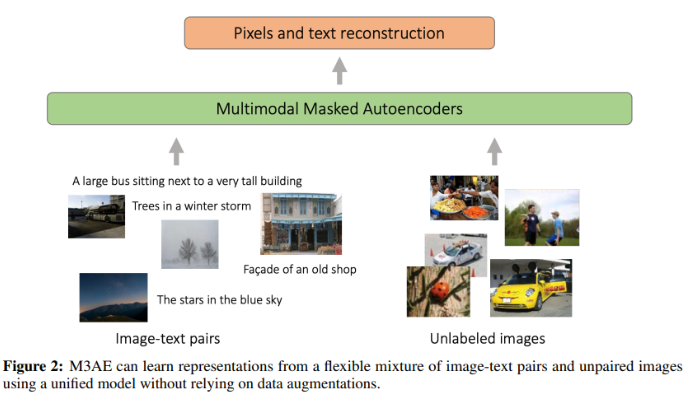
- unpaired data도 사용 가능
4. Experiments
4.1. Datasets
- Conceptual 12M(CC12M) 데이터셋을 사용하여 pre-training
- ImageNet에서 encoder의 transferability를 평가
- CIFAR-100, CIFAR-10에서 out-of-distribution detection을 평가
4.2. Experiments Setup
- ViT-B/16, Vit-L/16을 encoder로 사용
- 512 width의 8 blocks으로 이루어진 lightweight 모델 사용 (MAE를 따름)
- 나머지 자세한 세팅은 논문 Appendix에서 확인
4.3. Results
ImageNet Classification
- 마지막 classification layer를 제외하고 model의 weight는 freeze
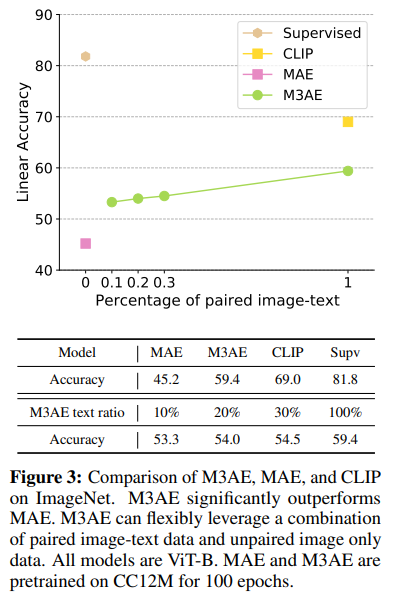
- 모델에게 visual, language 간 관계를 학습시킬 수 있는 paired data의 비율이 높을수록 성능이 좋음
- MAE보다 좋은 성능을 보였으며 CLIP보다 좋지 않은 성능을 보임
- M3AE는 paired & unpaired data를 모두 활용할 수 있어 CLIP보다 flexible
- ImageNet으로 pre-trained한 MAE보다 CC12M으로 pre-trained한 MAE의 성능이 크게 떨어지는 현상이 존재
- 저자는 두 데이터셋의 large domain gap을 성능 차이의 원인으로 지목
- M3AE가 MAE보다 transferable representation 학습에 뛰어남
4.4. Analysis
Model scaling and epochs scaling
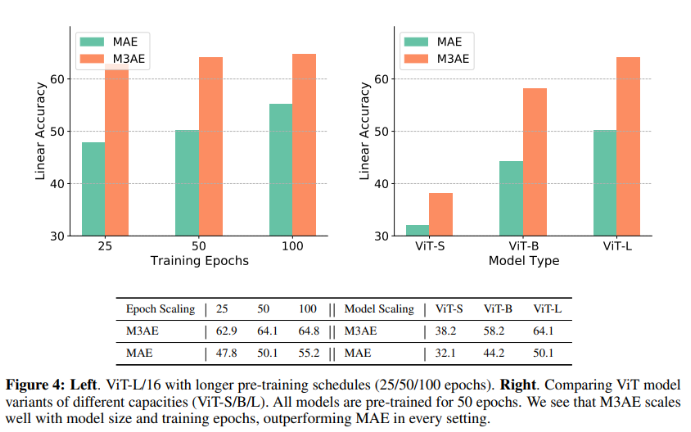
- M3AE가 MAE보다 longer training, larger models에서 좋은 결과를 보임
Out-of-distribution detection
- 이전 연구들은 self-supervised 학습이 OOD detection 성능을 크게 향상시켜준다는 것을 증명
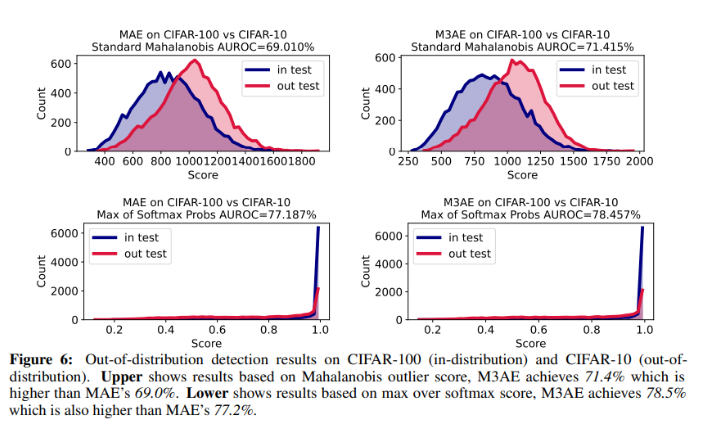
- M3AE는 Mahalanobis outlier score, max over softmax score에서 MAE를 뛰어넘음
Ablation on text mask ratio
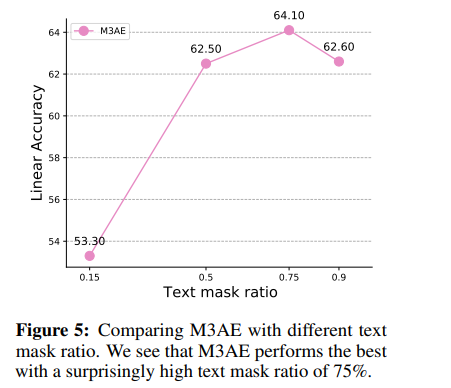
- 주로 15%의 masking ratio를 사용하는 BERT와 달리 M3AE는 높은 text mask ratio에서 가장 좋은 결과를 얻음
Visualization of cross-modal attention weights

- text token과 모든 image patches 사이의 attention을 visualization
- Figure 7을 보면 “elephant” token은 코끼리가 있는 image patches와 attention score가 높은 것을 볼 수 있음
- Figure 8의 오른쪽 사진에서 천장의 균열 부분의 patch는 roof, leak, ceiling이라는 token에 집중하고 있음
- 저자는 M3AE가 유의미한 개념을 image, text에서 학습하였기 때문에 두 modality 개념의 관계에 대한 추론을 할 수 있었다고 주장
Clustering analysis of representation
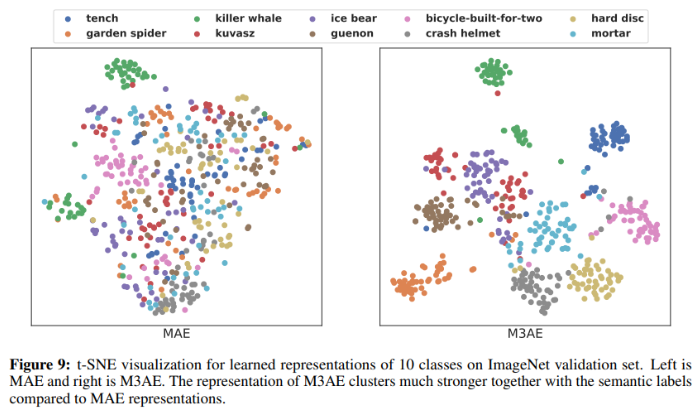
- ImageNet의 10개 클래스에 대해 MAE와 M3AE의 t-SNE 시각화를 비교
- M3AE가 MAE보다 같은 class가 강하게 모여있는 것을 볼 수 있음
Reconstruction visualization

5. Conclusion, Limitation and Future Work
- contrastive objectives 없이 image, language의 multimodal representation을 학습하는 간단하고 효과적인 모델 M3AE를 제시
- M3AE가 downstream task에서 일반화 성능이 뛰어난 shared representation을 학습할 수 있음을 실험을 통해 보임
- M3AE는 flexibility, scalability가 뛰어나 large-scale datasets을 학습하기에 적합
- pre-trained M3AE가 visual reasoning, dialog system, language guided image generation등 downstream task에 적용될 수 있다고 생각
후기 & 정리
- contrastive learning, separate encoder를 사용하지 않으며 unpaired data를 사용할 수 있는 flexibility를 갖추었으며 scalability 또한 뛰어난 네트워크 아키텍처 Multimodal masked autoencoders: M3AE를 제시
- BERT의 pretext task인 masking 방식을 vision, language multimodal로 확장한 M3AE
- vision에서 self-supervised learning, meta-learning의 최근 Trend에 대해 알고 싶어 읽은 논문
- Attention visualization의 경우 논문에 제시한 예시가 너무 적어 신뢰가 가지 않음(Attention visualization cherry pick 논문에 다수 존재)
- vision에서도 self-supervised learning이 빠르게 발전하여 인터넷에 존재하는 많은 unlabeled data를 활용할 수 있기를 희망
Reference
[0] Xinyang Geng et al. (2022), "Multimodal Masked Autoencoders Learn Transferable Representations". https://arxiv.org/abs/2205.14204
Multimodal Masked Autoencoders Learn Transferable Representations
Building scalable models to learn from diverse, multimodal data remains an open challenge. For vision-language data, the dominant approaches are based on contrastive learning objectives that train a separate encoder for each modality. While effective, cont
arxiv.org
[1] Kaiming he et al. (2021). "Masked Autoencoders Are Scalabel Vision Learners". https://arxiv.org/abs/2111.06377
Masked Autoencoders Are Scalable Vision Learners
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we
arxiv.org



