
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 오블완
- Generative Model
- 폰트생성
- 모션매칭
- Unreal Engine
- Stat110
- dl
- motion matching
- cv
- userwidget
- 생성모델
- Font Generation
- BERT
- deep learning
- RNN
- WinAPI
- Few-shot generation
- ue5.4
- animation retargeting
- WBP
- UE5
- Diffusion
- multimodal
- ddpm
- NLP
- 언리얼엔진
- CNN
- GAN
- 딥러닝
- 디퓨전모델
Archives
- Today
- Total
Deeper Learning
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 본문
AI/Deep Learning
BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
Dlaiml 2022. 6. 14. 23:26Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, Luke Zettlemoyer [Facebook AI] (2019.10)
Abstract
- sequence-to-sequence model을 사전학습시키기 위한 denoising autoencoder BART를 제시
- BART는 text를 임의의 noise 함수로 corrupt시키고 모델은 corrupted text를 다시 original text로 재구성하는 방식으로 학습
- 기본 Transformer 기반 neural machine translation 아키텍처를 사용한 단순한 구조임에도 BERT, GPT 등 여러 최근 사전학습 방식들의 일반화 형태로 볼 수 있음 (임의의 noise function의 적용이 가능하기 때문)
- 문장의 순서를 랜덤하게 섞고 임의의 텍스트들을 단일 mask token으로 대체하는 것이 실험 결과 효과적이었음
- BART는 text 생성에 특히 효과적이나 comprehension task에도 뛰어난 성능
- 같은 학습 리소스 기준 RoBERTa와 GLUE, SQuAD에서 비슷한 성능을 기록하였으며 abstract dialogue, question answering, summarization tasks에서 SOTA를 달성
- BART는 target language 사전학습만으로 기존의 기계번역의 back-translation system보다 1.1 BLUE의 성능향상 성공
- BART 프레임워크 내에서 다른 사전학습 방식을 모방하는 ablation study로 어느 factor가 end-task 성능 향상에 가장 큰 영향을 미치는지 알아보았음
1. Introduction
- Self-supervised 방식은 넓은 NLP task에서 놀라운 성공을 거두었다
- 대부분 denoising autoencoder인 masked language models의 변형
- 이전 연구들은 더 좋은 분포의 masked token / masked token prediction 순서 / masked token을 대체할 context 선정 등의 방식으로 접근하였으나 이들은 특정 타입의 end-task에 집중하여(span prediction, generation, etc.) 적용성에 한계가 존재
- BART (Bidirectional and Auto-Regressive Transformer)를 제시

- BART의 Bidirectional encoder의 input은 Autoregressive Decoder의 input과 같지 않아도 되며 따라서 임의의 noise function의 적용이 가능
- text에 임의의 noise function을 적용하고 다시 model이 이를 reconstruction하는 BART의 장점은 noising flexibility에 있다
- 실험을 통해 랜덤하게 원래 문장의 순서를 섞고 임의의 길이(0 포함)의 text를 하나의 mask token으로 대체하는 방식이 가장 성능이 좋은 것을 발견
- 모델이 전체 sentence length에 대해 추론하고 더 큰 범위의 transformation을 하도록 강요함으로써 BERT의 word masking, next sentence prediction objectives를 일반화
2. Model
BART는 corrupted document를 original document로 매핑하는 denoising autoencoder, negative log likelihood를 사용하여 사전학습
2.1. Architecture
- 기본 seq2seq Transformer 아키텍처를 사용
- GPT를 따라 ReLU 대신 GeLU를 사용
- N(0, 0.02)로 parameters 초기화
- base model은 encoder, decoder에 각각 6 layers, large model은 각각 12 layers
- BERT 구조와 다른 점
- decoder의 각 layer는 encoder의 마지막 hidden layer와 cross-attention
- BERT는 word-prediction 하기 전 feed-forward network이 추가로 있지만 BART에는 없음
- BART는 같은 크기의 BERT model보다 10% 정도 많은 parameters를 가짐
2.2. Pre-training BART
- 일반적으로 denoising autoencoder는 noise를 주는 방식이 정해져 있지만 BART는 어떤 type의 corruption 모두 적용 가능
- 극단적으로 모든 정보를 masking하는 corruption을 적용하게 된다면, BART는 언어 모델과 같아진다 (Autoregressive Decoder만 의미 있음)
- 이전에 제시된 여러 transformations과 새로운 transformations으로 실험 (Figure 2), 대안 transformation를 탐색하는 후속 연구 제시
Token Masking
- BERT를 따름, 랜덤 tokens을 [MASK]로 대체
Token Deletion
- 랜덤 token을 input에서 삭제
- token masking과 다르게 모델은 missing inputs의 위치를 결정해야 함
Text Infilling
- λ=3의 포아송 분포로 span length를 결정하고 text spans을 정한 span length 만큼 샘플링하고 단일 [MASK] token으로 대체
- SpanBERT에서 영감을 받았으나 SpanBERT는 span length를 고정된 기하분포를 사용하여 얻으며 각 span이 단일 [MASK] token이 아닌 같은 길이의 [MASK] token sequence로 대체
- Text infilling은 span에서 얼마나 많은 tokens이 빠져있는지 예측하도록 모델을 학습시킨다
Sentence Permutation
- document는 마침표 기준으로 문장으로 나뉘며, 이 문장들의 순서를 랜덤하게 바꿈
Document Rotation
- Token 하나를 랜덤으로 고르고 해당 token을 document의 첫 토큰으로 선정
- 가나다라마.바사아.자차카. → 아.자차카.가나다라마.바사 (token “아”가 선정되었을 경우의 예시)
- 모델이 document의 시작점을 식별할 수 있도록 학습
3. Fine-tuning BART
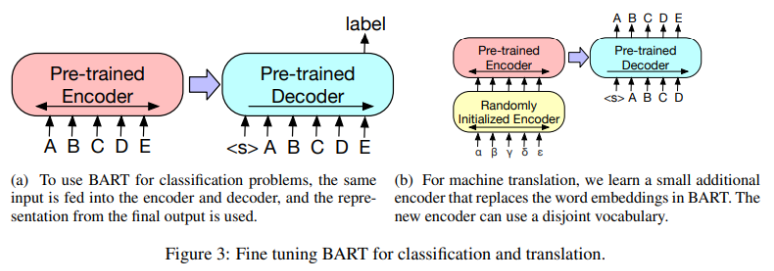
Sequence Classification Tasks
- encoder와 decoder에 같은 input이 들어감
- final decoder token의 final hidden state를 multi-class linear classifier에게 fed
- BERT의 CLS token과 비슷하나 가장 뒤쪽에 위치하도록 하여 AR decoder에서 모든 token에 attend 할 수 있도록 함
Token Classification Tasks
- SQuAD의 answer endpoint classification과 같은 task
- 전체 document를 encoder와 decoder에 feed
- 각 word의 top hidden state를 사용하여 token을 classify
Sequence Generation Tasks
- abstractive question answering, summarization과 같은 task
- BART의 autoregressive decoder를 활용하여 fine-tune
- input의 정보를 근거로 생성하는 generation task는 denoising pre-training objective와 밀접한 연관이 있음
Machine Translation
- BART encoder의 embedding layer를 초기화된 encoder로 대체
- 새 encoder는 foreign words를 BART가 English로 de-noise 시킬 수 있는 형태로 매핑하도록 end-to-end 학습
- BART의 positional embedding, BART encoder의 first layer의 input projection matrix, 초기화된 source encoder만 학습시키고 후에 모든 모델 parameters를 적은 iter 학습시키는 방식 사용
4. Comparing Pre-training Objectives
4.1. Comparison Objectives
- 많은 pre-training objectives가 제시되었으나 공정한 비교가 어려웠음
- 저자는 이들을 구현하고 pre-training objectives와 무관한 차이들을 제어하고 비교를 실시
- Language Model
- GPT와 비슷하게 left-to-right Transformer 언어 모델을 학습
- cross-attention을 제거한 BART decoder와 동일
- Permuted Language Model
- XLNet을 따라, 1/6의 token을 autoregressive하게 random order로 generate
- XLNet의 relative positional embedding, attention across segment는 사용하지 않음
- Masked Language Model
- BERT를 따라 15%의 token을 [MASK]로 대체하고 독립적으로 original tokens을 학습하도록 함
- Multitask Masked Language Model
- UniLM을 따라 additional self-attention masks를 적용한 Masked Language Model을 학습
- 다음과 같은 비율로 self-attention mask를 랜덤하게 적용
- left-to-right: 1/6
- right-to-left: 1/6
- unmasked: 1/3
- 첫 50%의 tokens을 unmasked 나머지 50%에 left-to-right를 적용: 1/3
- Masked Seq-to-Seq
- MASS(MASS: Masked Sequence to Sequence Pre-training for Language Generation)를 따라 50%의 token을 포함하는 span을 masking 하고 seq2seq model로 masked tokens을 예측
- Permuted LM, Masked LM and Multitask Masked LM에는 XLNet의 two-stream attention을 사용
- 실험을 통해 source input이 encoder에 feed, target이 decoder의 output인 정석의 seq-to-seq 문제의 경우 BART가 다른 모델보다 성능이 좋았음
4.2. Tasks
- SQuAD: extractive question answering task, 모델은 token의 start, end index를 예측
- MNLI: bitext classification task, 한 문장이 다른 문장을 entails 하는지 판별, BART는 두 문장에 EOS token을 붙이고 이를 encoder와 decoder에 모두 feed
- ELI5: long-form abstractive question answering dataset, 모델은 document와 question을 보고 답을 생성
- XSum: abstractive news summarization
- ConvAI2: context와 persona를 보고 dialogue response를 생성하는 task
- CNN/DM: news summarization dataset, 요약 label은 source sentences와 가깝게 연관되어있음
4.3. Results
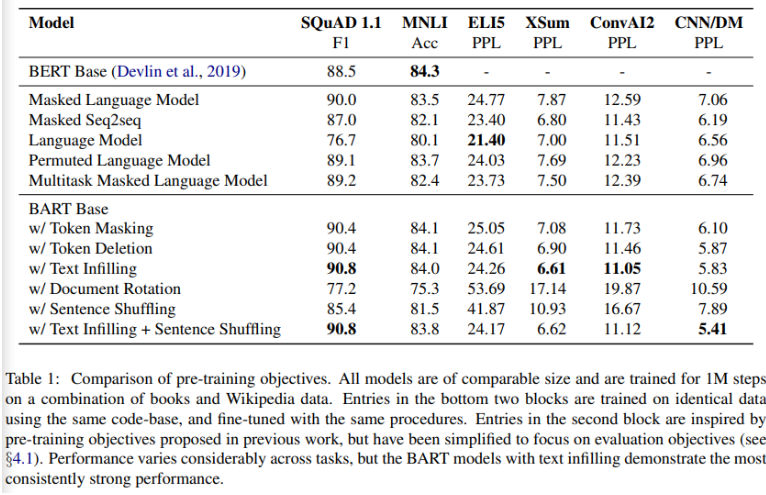
- pre-training method의 영향은 task에 따라 크게 다름
- Document Rotation, Sentence Shuffling의 경우 단독으로 사용하였을 때 성능 저하가 있었으며 Token Masking, Deletion의 성능이 좋았음
- Left-to-right auto-regressive language modeling을 포함하지 않는 Masked Language Model과 Permuted Language Model은 generation task에서 낮은 성능을 기록
- 뒷 시점의 context가 중요한 SQuAD에서 bidirectional encoder는 중요한데 BART는 절반의 bidirectional layers로 비슷한 성능을 내는데 성공
- Permuted Language Model의 경우 relative-position embedding, segment-level recurrence 등의 부재로 XLNet보다 낮은 성능을 보임
- text-infilling을 사용한 BART는 ELI5를 제외한 모든 tasks에서 가장 좋은 성능을 기록
5. Large-scale Pre-training Experiments
Experimental Setup
- RoBERTa model과 같은 scale로 BART를 학습
- encoder decoder 12 layers, 1024 hidden size, 8000 batch size
- 500,000 steps 학습
- GPT-2의 byte-pair encoding 사용
- text infilling, sentence permutation 사용 (30%의 tokens을 masking, 모든 sentences permute)
- fianl 10% steps에는 dropout 제거
- RoBERTa와 동일한 160Gb 데이터 사용
Results
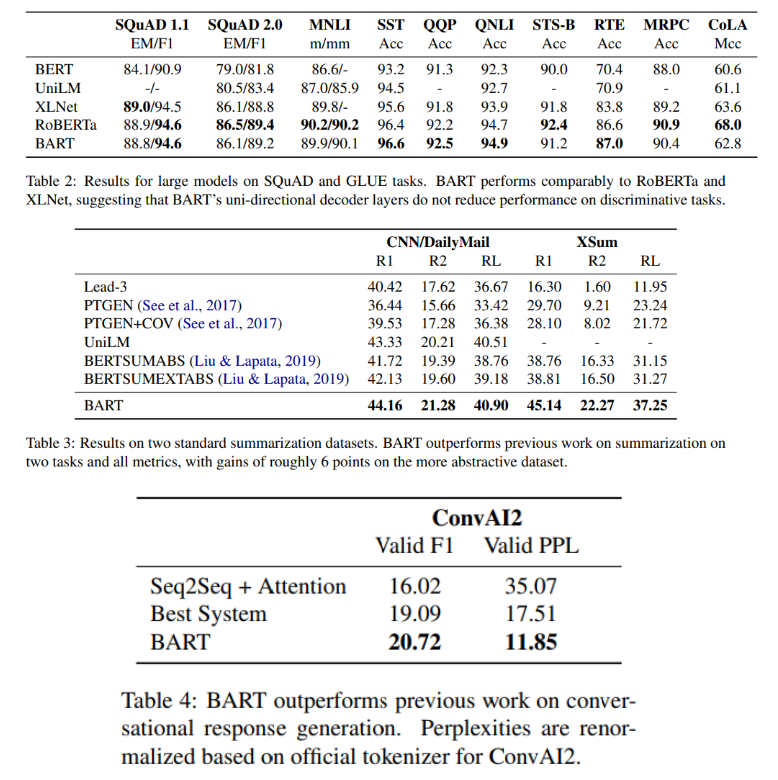
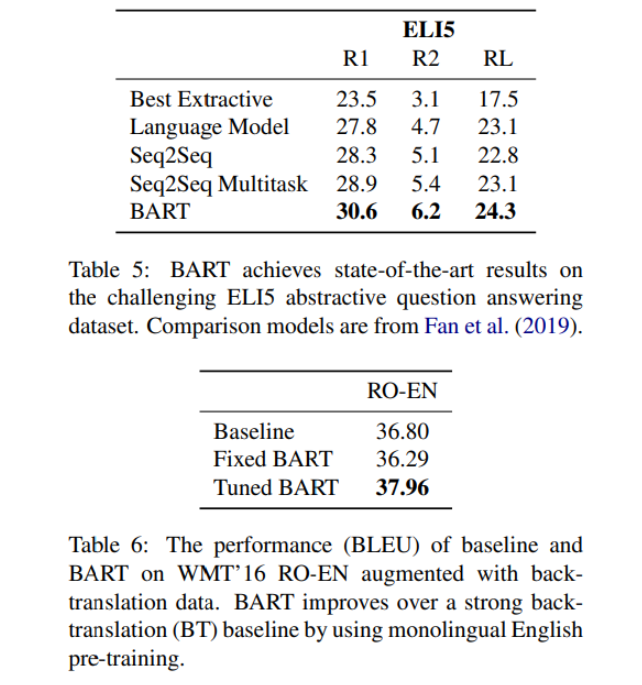
6. Conclusions
- corrupted document를 reconstruct하는 pre-training approach BART를 제시
- BART는 discriminative task에서는 RoBERTa와 비슷한 성능을 보였으나 몇몇 text generation task에서 SOTA를 달성
- 새로운 document corrupting 방식 탐색을 future work으로 제시
후기 & 정리
- seq-to-seq 모델의 denoising autoencoder 형식의 사전학습 방식 BART를 제시
- encoder의 input에 임의의 noise function을 적용할 수 있음
- 비슷한 컴퓨팅 자원, 데이터, 모델 크기 기준 generative tasks에서 RoBERTa를 뛰어넘으며 SOTA를 달성
- 기본 Transformer의 Encoder, Decoder 구조를 사용한 모델로 임의의 noise function을 적용할 수 있는 denoising autoencoder의 concept을 가지기 때문에 이전에 발표되었던 많은 pre-training method를 BART framework의 “Denoising”으로 재구현이 가능
- BART framework 내에서 여러 pre-training method를 구현하고 여러 task에서의 성능을 비교하는 부분이 흥미로웠음
Reference
[0] Mike Lewis et al., (2019). "BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension". https://arxiv.org/abs/1910.13461
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more



