
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- dl
- 오블완
- 폰트생성
- multimodal
- Few-shot generation
- deep learning
- ue5.4
- cv
- 딥러닝
- 생성모델
- 언리얼엔진
- RNN
- GAN
- WBP
- WinAPI
- userwidget
- 디퓨전모델
- 모션매칭
- Generative Model
- Font Generation
- NLP
- Stat110
- CNN
- motion matching
- ddpm
- BERT
- animation retargeting
- UE5
- Unreal Engine
- Diffusion
Archives
- Today
- Total
Deeper Learning
T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer 본문
AI/Deep Learning
T5: Exploring the Limits of Transfer Learning with a UnifiedText-to-Text Transformer
Dlaiml 2022. 6. 18. 23:00Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J. Liu [Google] (2019.10)
Abstract
- Transfer learning은 NLP에서 강력한 기술로 부상하였다
- 모든 text 기반 language 문제를 text-to-text 형식으로 바꾸는 unified framework을 제시하여 NLP에서의 transfer learning에 대해 탐구
- 논문의 체계적인 연구는 pre-training objectives, 아키텍처, unlabeled 데이터셋, transfer approach 등 요인들을 여러 language understanding tasks에서 비교
- scale에 대한 탐구로 얻은 인사이트와 새롭게 선보인 데이터셋 “Colossal Clean Crawled Corpus”(C4)를 사용하여 summarization, question answering, text classification 등 많은 tasks에서 SOTA를 달성
- NLP에서 transfer learning 연구를 장려하기 위해 dataset, pre-trained model, code를 공개
1. Introduction
- 현대 머신러닝에서 모델은 auxiliary task를 통해 text를 이해할 수 있는 지식을 습득
- 최근 NLP는 scalability를 가진 모델을 large unlabeled data로 pre-train 시키는 방식을 사용
- NLP에서의 pre-training objectives, unlabeled data sets, benchmark, fine-tuning method에 대해 많은 연구가 있었음
- 빠르고 다양하게 연구되는 분야다 보니 여러 알고리즘, 새 contribution의 분석이 어려움
- NLP 분야에 대한 보다 철저한 이해를 위해, 체계적으로 다양한 approaches를 비교하고 한계를 끌어올릴 수 있게 해주는 unified transfer learning approach를 제시
- basic idea는 모든 text 문제를 text-to-text 문제로 여기는 것

- 본 연구의 목적은 새로운 method의 제시가 아닌 분야의 현주소에 대한 종합적인 관점을 제공하는 것
- 연구된 여러 method들은 scaling up에서 한계가 있다는 것을 실험을 통해 확인
- 웹에서 스크랩한 수백기가의 cleaned English text dataset인 **Colossal Clean Crawled Corpus(C4)**를 소개
2. Setup
2.1 Model
- original Transformer와 거의 비슷한 아키텍처를 사용
- Layer Norm bias 제거
- layer normalization을 residual path 밖으로 옮김
- positional embedding schema 수정
2.2 The Colossal Clean Crawled Corpus
- Common Crawl 데이터셋이 발전한 dataset
- 약 750GB를 수집, TF Dataset을 통해 쉽게 접근 가능
2.3 Downstream Tasks
- GLUE, SuperGLUE text classification, CNN/Daily Mail, SQuAD, WMT 성능을 측정
2.4 Input and Output Format
- 단일 모델로 여러 tasks를 처리하기 위해 text-to-text 형식을 취함
- MNLI, text classification에서 모델은 target label의 index가 아닌 target label의 word를 predict (label에 없는 word를 prediction하면 오답으로 간주, 하지만 학습된 모델에서 그런 경우는 발견되지 않음)
- summarization task에는 document 끝에 TL;DR을 붙이는 등 prefix를 활용
- STS-B와 같은 regression task는 label이 의미있는 크고 작음을 가지기 때문에 label은 모두 소수점 아래 둘째 자리에서 반올림, prediction word는 float으로 변환하여 loss를 산출
- multi-task 학습 중 dataset 간 data leakage 위험으로 인해 WNLI는 average GLUE score에서 제외
3. Experiments
3.1 Baseline
(상세한 실험 설정은 논문 참고)
3.1.1 Model
- 실험 결과 generation, classification task에서 성능이 더 좋았던 standard encoder-decoder Transformer를 사용
- Bert Base의 설정을 따랐으나 2 layer stack을 사용하여 약 2배의 parameters 보유
3.1.2 Training
- max_sequence_length=512, hidden_dim=768
- inverse square root learning rate scheduling 사용
- lr=1/√max(n,k)
- n = 현재 #iterations, k = warm-up steps
- fine-tuning 때는 fixed learning rate 0.001 사용
3.1.3 Vocabulary
- SentencePiece를 사용하여 text를 WordPiece로 변환
- 영어, 독일어, 프랑스어, 루마니아어를 10:1:1:1 비율로 학습
- 약 32,000개의 wordpiece vocab
3.1.4 Unsupervised objective

- Masked language modeling을 사용
- 15%의 token을 masking, 연속되는 masked token은 하나의 MASK token으로 변환
- mask token의 경우 unique한 id를 부여 (모두 다르게 취급)
3.2 Archietectures
3.2.1 Model structures

- Fully-visible
- Causal
- output(y)는 이전 시점의 input token(x)와 attention 연산
- Causal with prefix
- output은 이전 시점의 input token, prefix와 attention 연산

- Standard Encoder-Decoder
- encoder는 Full-visible attention, decoder는 causal attention 사용
- Language model
- causal attention 사용, Transformer의 decoder 사용
- Prefix LM
- causal with prefix attention 사용, Transformer의 decoder 사용
- input text(x)이 full-visible attention을 수행하는 prefix가 되는 구조
- 위 3가지 아키텍처 디자인을 비교
3.2.4 Result

- Encoder-decoder 구조 / Denoising objective가 가장 좋은 결과를 기록
- encoder, decoder의 parameter sharing은 적은 성능 하락으로 parameters를 효과적으로 줄일 수 있었음
3.3 Unsupervised Objectives
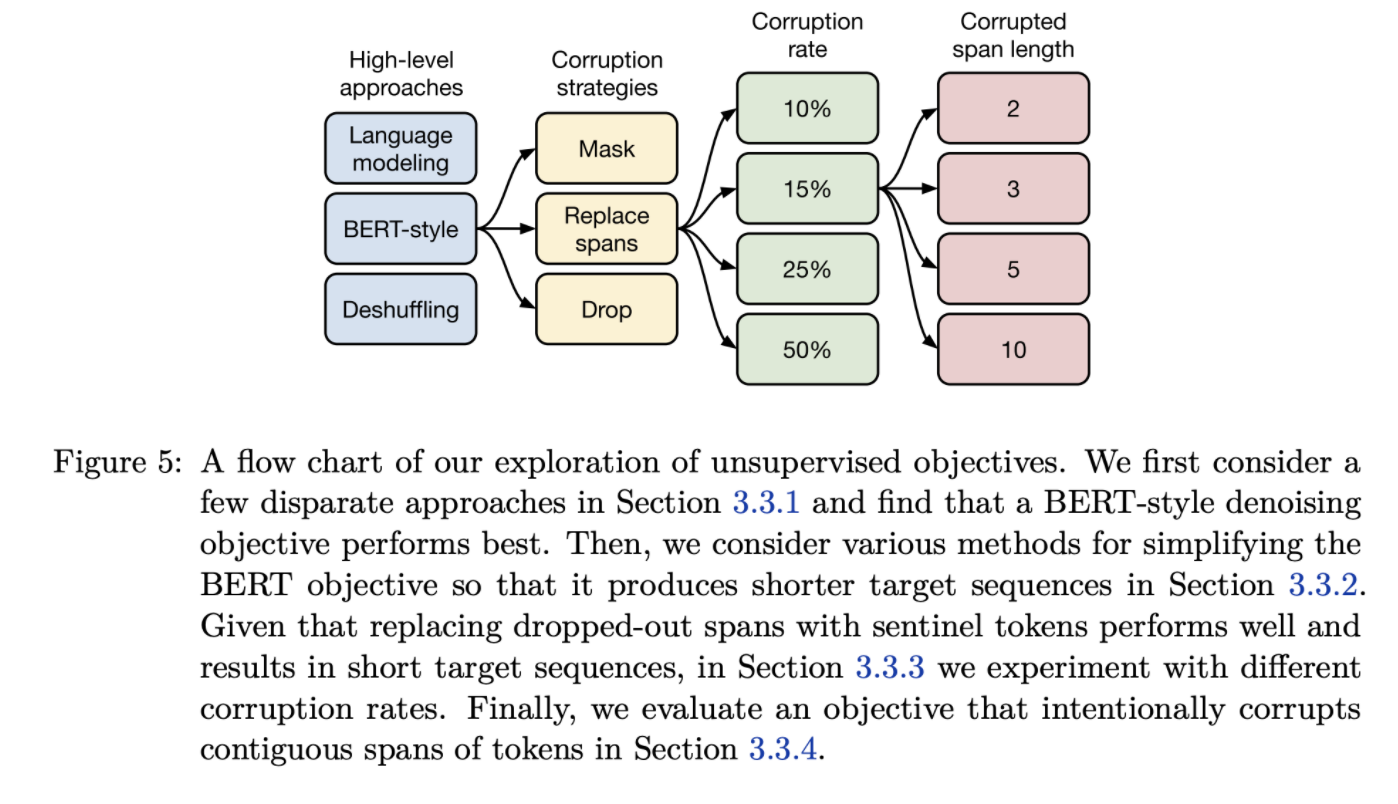
- Greedy하게 Coarse to fine으로 여러 objective와 하위 설정에 대한 실험

- Prefix language modeling / BERT-style / Deshuffling 중 BERT-style의 성능이 가장 뛰어났음

- 연속된 corrupted tokens을 하나의 mask token으로 대체하는 Replace corrupted spans, long sequence에서 attnetion을 피하기 위한 Drop corrupted tokens으로 BERT-style의 masking 설정에 대한 실험
- Replace corrupted spans의 성능이 가장 좋았음
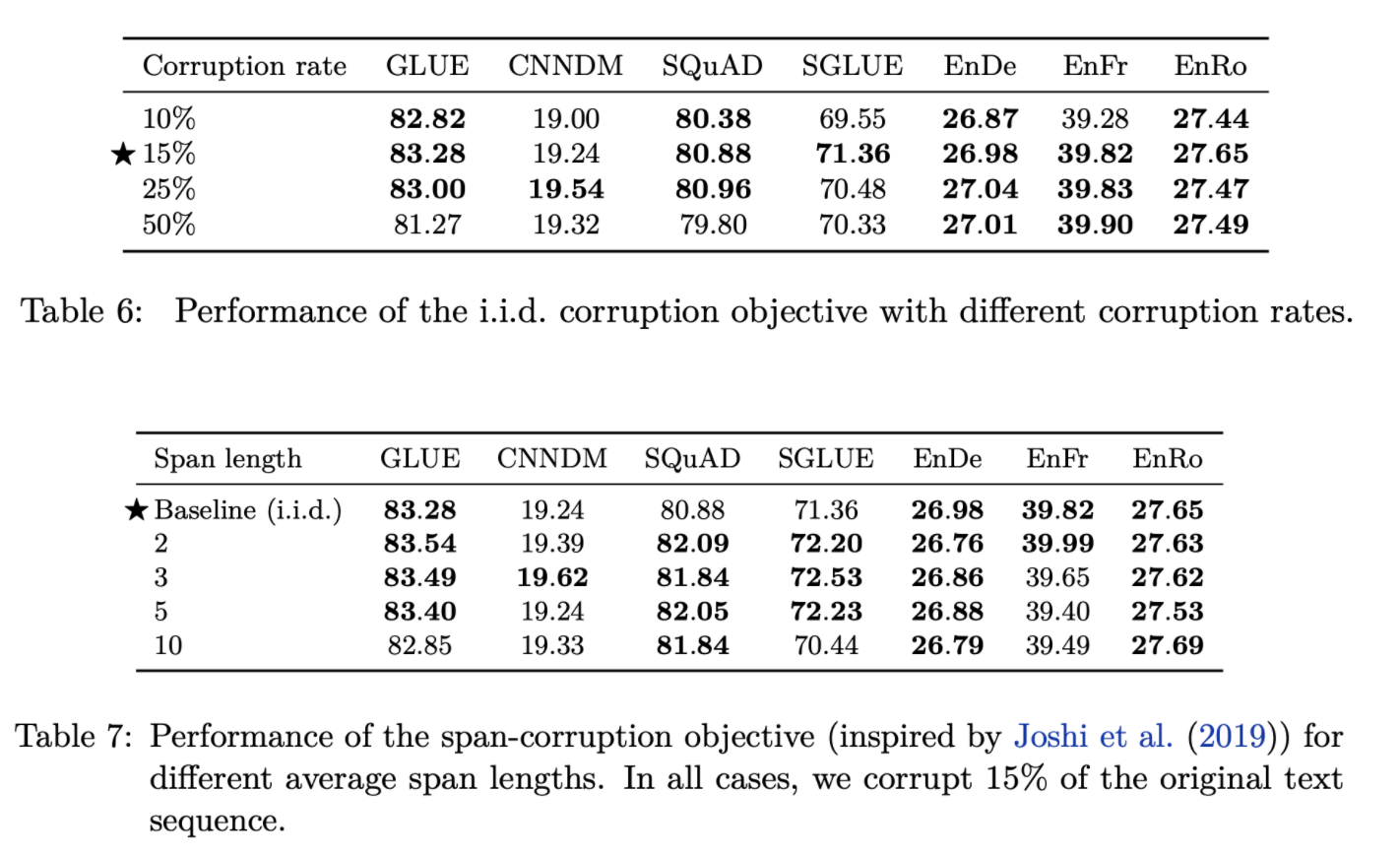
- Corruption rate, Span length에 대한 실험 (Table 6,7)
- 15%, Baseline(span length 제약 없이 i.i.d corruption)의 성능이 최고
3.4 Pre-training Data set

- unlabeled dataset 들의 성능을 비교
- in-domain 데이터셋의 경우 해당 downstream task에서 좋은 성능을 기록

- C4 dataset의 크기를 줄여가며 실험, 예상과 같이 dataset의 크기가 작을 경우 모델이 pre-training dataset을 외워서 training loss가 감소하며 valid set에서 성능이 하락
3.5 Training Strategy
3.5.1 Fine-tuning method
- Adapter layers
- dense-ReLU-dense로 구성된 blocks을 Transformer의 feed-forward network 뒤에 추가하는 방식
- Gradual unfreezing
- encoder, decoder의 top layer 부터 한 층씩 unfreeze
- All parameters

3.5.2 multi-task learning
- T5의 unified text-to-text framework는 모든 tasks가 test-to-text 형식으로 구성되어 있어 데이터셋을 섞는 것이 곧 multi-task와 같다
- Examples-proportional mixing
- 각 dataset의 크기에 비례하여 샘플링
- 너무 큰 dataset의 크기는 가상의 datasize limit K로 제한
- Equal mixing
- 모든 task에서 동일한 수의 데이터를 샘플링
- Temperature-scaled mixing
- multilingual BERT에서 사용한 방식으로 mixing rate rm을 (1T)2로 설정하고 renormalize하여 합이 1이되도록 함
- T=1이면 Examples-proprotional mixing과 동일, T가 증가하면 equal mixing과 비슷한 형태(모두 같은 비율)
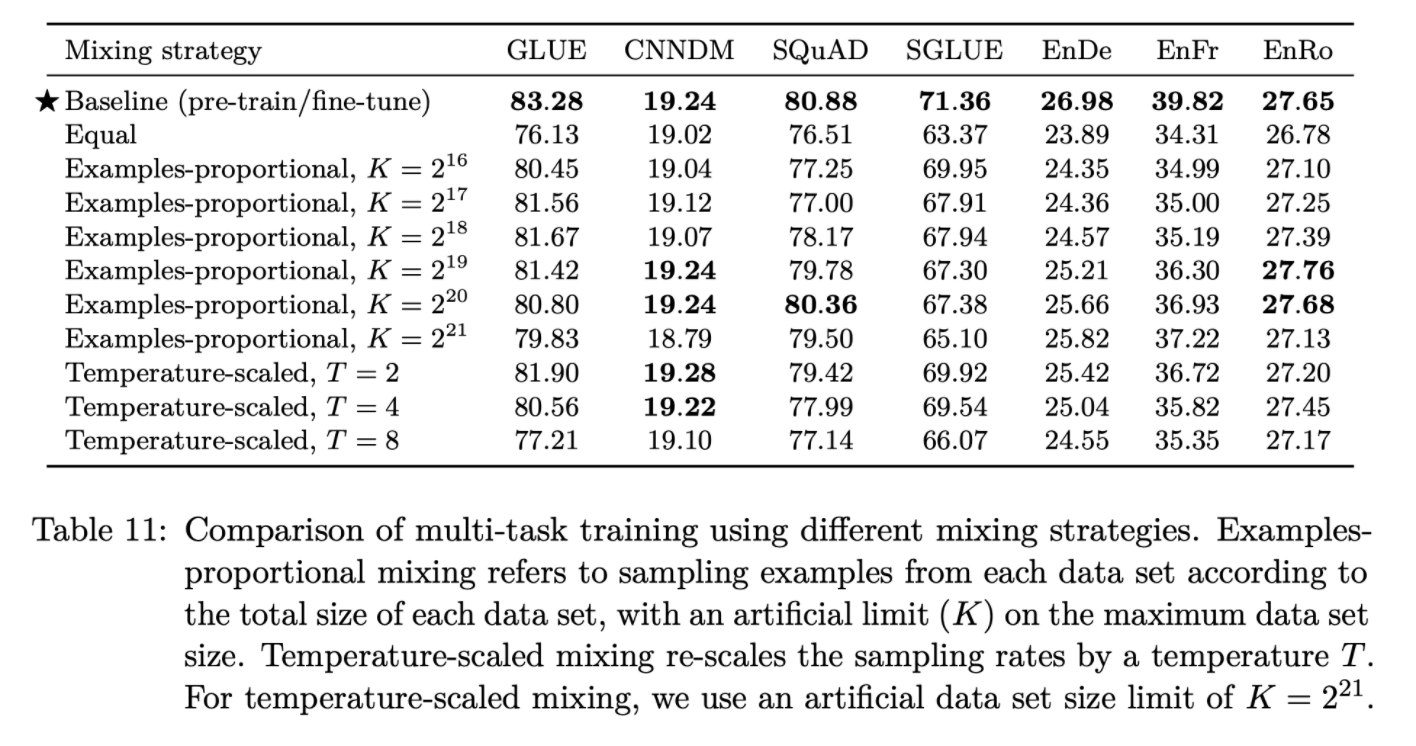
- 새로 설계한 method 대부분 성능 저하 결과
3.5.3 Combining multi-task learning with fine-tuning
- 위 실험의 결과로 자연스럽게 fine-tuning에서의 multi-task learning으로 이동
- leave-one-out
- 하나의 task를 빼고 pre-training 후, 해당 task를 fine-tune
- supervised multi-task pre-training
- K=219, examples-proportional mixture를 사용하여 supervised training
- Multi-task training, Multi-task pre-training + fine-tuning
- MT-DNN에서 제시한 방식
- unsupervised objective와 supervise task의 결합

- Unsupervised pre-training + fine-tuning이 가장 좋은 성능을 보임
3.6 Scaling

- 예상대로 larger model size, longer training, larger batch size 모두 일관적으로 성능을 향상시킴
3.7 Putting It All Together
- 지금까지 수행한 체계적인 실험 결과를 모아 NLP benchmark를 얼마나 끌어올릴 수 있는지 테스트
- Objective
- i.i.d denoising objective (span length 3, 15% corruption)
- Longer training
- Model size
- Base(220M parameters), Small(60M parameters), large(770M parameters), 3B(3B parameters), 11B(11B parameters)
- Multi-task pre-training
- MT-DNN에서 제시한 방식 사용
- training 도중에도 multi-task에서 성능을 관찰할 수 있는 장점 존재
- Fine-tuning on individual GLUE and SuperGLUE tasks
- Beam Search(beam width=4, length penalty alpha=0.6) for WMT, CNN/DM
- Test set
- 각 데이터셋의 validation set이 아닌 test set의 결과 report
- SQuAD는 test set benchmark server 문제로 valid set 사용
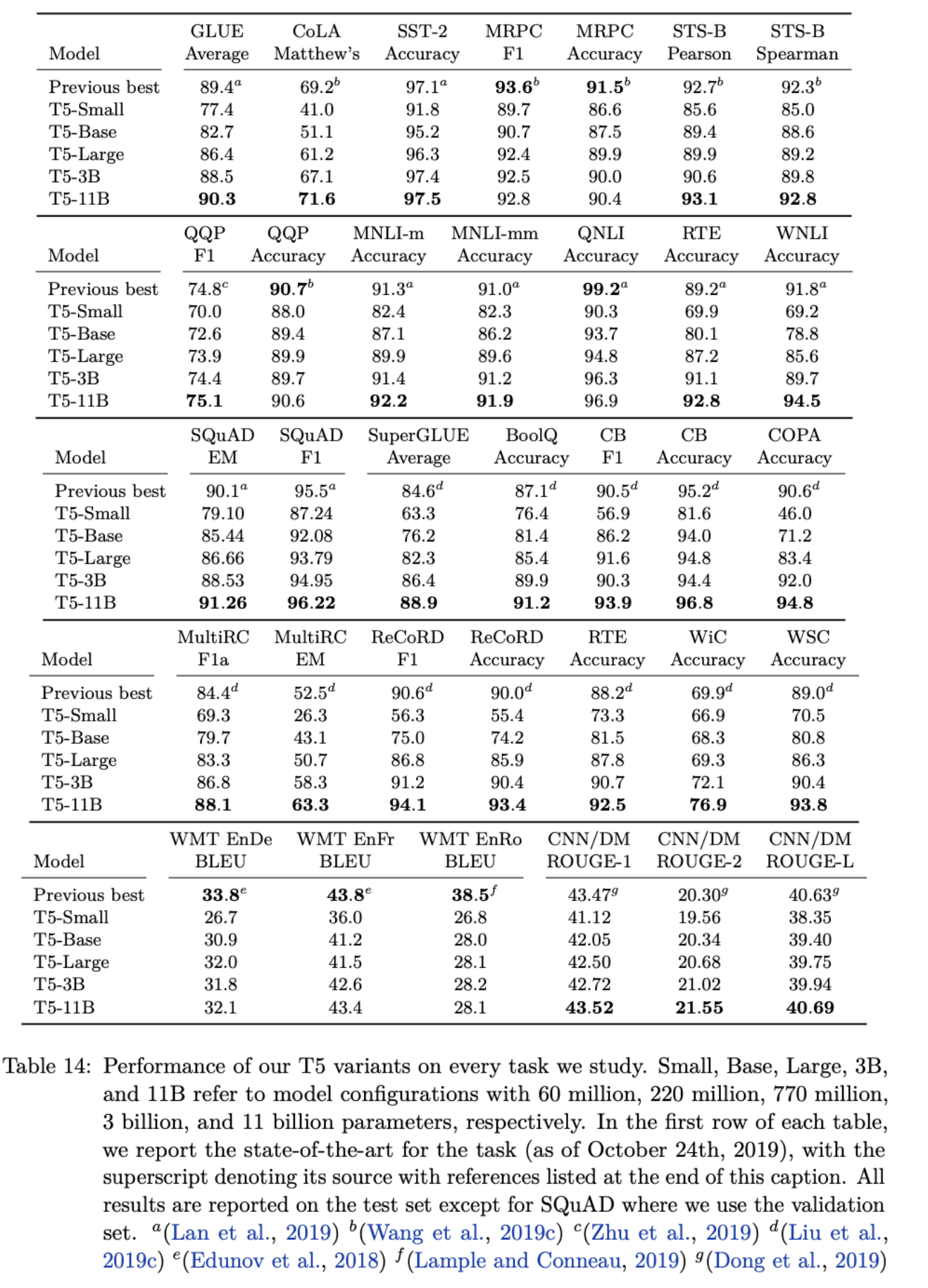
- 24개 task 중 18개 task에서 SOTA를 달성
- 예상과 같이 11B 모델이 가장 좋은 성능을 보임
4. Reflection
4.1 Takeaways
- Text-to-Text
- 간단한 encoder-decoder 구조로 test-specific한 아키텍처와 비슷한 성능을 보여줌
- scale up을 통해 SOTA까지 달성한 디자인
- Architectures
- encoder-decoder 아키텍처는 text-to-text framework에서 encoder-only, language model 아키텍처보다 좋은 성능을 보여줌
- encoder와 decoder의 parameter sharing은 성능을 조금 낮추지만 효과적으로 parameter 수를 줄일 수 있음
- Unsupervised learning
- 대부분 denoising objectives가 text-to-text에서 비슷한 성능을 보임
- 따라서 short target sequence를 사용하는 denoising objective를 선정하여 computational cost를 줄이는 것이 좋음
- Data sets
- C4를 제시
- 작은 dataset이 pre-training 도중 여러 번 반복되면 모델의 성능이 Overfitting으로 인해 하락
- Training strategies
- 여러 tasks로 pre-training 하고 fine-tuning 하는 것은 unsupervised pre-training에 견줄만한 성능을 보임
- 하지만 task mixing 비율에 대해서는 연구가 더 필요
- Scaling
- scale up, ensemble 모두 효과적
- Pushing the limits
- 얻은 인사이트를 결합하고 충분히 큰 모델(11B)에서 학습한 결과 많은 benchmark에서 SOTA를 달성
4.2 Outlook
- The inconvenience of large models
- 가볍고 성능 좋은 모델을 만들어야 한다 (Distillation, parameter sharing, etc)
- More efficient knowledge extraction
- corruped span을 denoise하는 task가 general-purpose knowledge를 모델에게 가르치기 위해 충분하지 않을 수 있음
- real & machine generation text를 구분하는 이전 연구와 같은 새로운 접근이 필요
- Formalizing the similarity between tasks
- unlabeled in-domain data로 해당 domain의 downstream task 성능 향상이 가능
- pre-training data 또한 downstream task에 맞춰 선택할 수 있음
- Language-agnostic models
- English-only pretraining으로 번역에서 SOTA 달성 실패
- general language understanding model 연구를 후속 연구로 제안
정리 & 후기
- text-to-text framework, standard Transformer, denosing objective, scaling으로 SOTA를 달성한 t5를 제시
- 새로운 method의 제시가 아닌 활발하게 연구되던 NLP의 unsupervised learning을 정리하고 전체적인 관점을 제시한 논문
- 많은 실험으로 섬세하게 여러 모델 구조, 학습 방식을 선정 + Scaling으로 SOTA를 달성
- 오랜만에 읽은 Appendix 제외 44페이지의 긴 논문
- SOTA 달성, Human level-performance 근접도 물론 흥미롭지만 기존 연구 흐름을 정리하고 여러 작은 실험들(training obejctive, fine-tuning method, multi-task pre-training)이 흥미로웠던 논문
- dataset, pre-training obejective, model architecture, fine-tuning method, data sampling, model size 등 NLP에서 중요하게 다루는 여러 주제를 모두 다룬 논문
Reference
[0] Colin Raffel et al. (2019). "Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer". https://arxiv.org/abs/1910.10683
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
Transfer learning, where a model is first pre-trained on a data-rich task before being fine-tuned on a downstream task, has emerged as a powerful technique in natural language processing (NLP). The effectiveness of transfer learning has given rise to a div
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
'AI/Deep Learning' Related Articles
more



