
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
- 폰트생성
- deep learning
- 생성모델
- Diffusion
- WBP
- ue5.4
- Generative Model
- 딥러닝
- ddpm
- Unreal Engine
- Stat110
- BERT
- 오블완
- dl
- 디퓨전모델
- Font Generation
- UE5
- cv
- GAN
- motion matching
- NLP
- multimodal
- 언리얼엔진
- CNN
- userwidget
- Few-shot generation
- animation retargeting
- RNN
- WinAPI
- 모션매칭
- Today
- Total
Deeper Learning
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators 본문
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Dlaiml 2022. 6. 9. 01:25Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning, [Google Brain] [Stanford University] (2020.03)
Abstract
- Masked language modeling (MLM)은 input의 몇몇 token을 [MASK] token으로 바꾸고 원래 token을 재구성하는 방식으로 학습
- MLM으로 학습한 모델은 downstream NLP task에 전이학습 하였을 때 성능 향상이 있었으나 효과를 보기 위해서는 많은 계산량을 요구한다 (비효율적인 sampling)
- 대안으로 저자는 sample-efficient pre-training task인 replaced token detection을 제시한다
- token을 masking하지 않고 작은 generator network을 사용하여 샘플링한 실제같은 대안 token으로 대체한다
- 모델은 MLM처럼 원래 token을 맞추는 것이 아니라 discriminative model로 token이 generator network에서 생성한 것인지 판별한다
- 오직 masked out된 token만 판별하는 MLM보다 모든 input token에 대한 판별이 필요한 pre-training task인 replaced token detection이 더 효율적이라는 것을 실험을 통해 증명하였다 (같은 모델 size, data, 연산량 조건에서 BERT 보다 좋은 결과를 보임)
- 1개의 GPU에서 4일 동안 학습하여 GLUE NLU benchmark 기준 GPT(30x more compute)의 점수를 능가
- 1/4의 계산량으로 RoBERTa, XLNet과 비슷한 성능을 보여주었으며, 같은 계산량 기준으로 그들의 성능을 뛰어넘는 ELECTRA는 scalability 또한 가지고 있음
1. Introduction
- 2020년 3월 representation learning 방식의 SOTA는 denoising autoencoders (Vincent et al., 2008)학습 이라고 할 수 있다
- denoising autoencoders는 input sequence의 subset을 고르고, 고른 tokens 자체를 masking 하거나 (=BERT) 그 tokens의 attention을 masking(=XLNet)하고 원래 token을 복구하도록 network를 학습시킨다
- bidirectional representation을 학습할 수 있어 전통적인 언어모델 pre-training보다 효과적이지만 MLM은 하나의 example에 대해 15%의 token으로만 학습하기 때문에 대체로 많은 계산량을 요구한다
- 이를 해결하기 위해 저자는 진짜 input token과 생성된 대체 token을 구분하는 replaced token detection을 제시한다
- replaced token detection은 BERT의 fine-tuning downstream task에서는 볼 수 없지만 pre-training에만 존재하는 인위적인 [MASK] token 문제를 해결
- replaced token detection에서 모델은 모든 token을 real input token인지 대체된 token인지 판별하는 discriminator의 역할
- MLM에서 모델은 masking된 token을 보고 원래 token을 예측해야 하는 generator의 역할
- discriminative task의 주요한 장점은 모델이 maksed-out된 input tokens의 subset이 아닌 모든 input tokens에서 학습하기 때문에 연산 측면에서 효율이 좋다는 점
- 제시한 방식이 GAN의 discriminator의 학습을 연상시키지만, GAN을 text에 적용하기는 어렵고, ELECTRA는 maximum likelihood로 corrupted token을 생성하는 generator를 학습하기 때문에 adversarial 하지 않음
- 제시한 접근법을 ELECTRA: Efficiently Learning an Encoder that Classifies Token Replacements Accurately라고 명명
- 사전연구로 pre-train Transformer text encoders에 적용시키고 여러 번의 ablation study을 통해 모든 input tokens에서 학습하는 것이 ELECTRA의 학습이 BERT보다 훨씬 빠른 이유임을 발견, 또한 학습이 완료되면 downstream task에서 ELECTRA가 더 높은 정확도를 기록
- 더 많은 연산으로 pre-training하면 거의 항상 downstream accuracy가 증가하기 때문에 효율적인 연산은 매우 중요
- GLUE NLU benchmark, SQuAD QA benchmark로 실험
- ELECTRA는 MLM-based method인 BERT와 XLNet을 같은 model size, data, 연산량 기준 더 좋은 성능을 보임
- ELECTRA-Small은 GPU 1개로 4일 학습하여 GPT, BERT를 뛰어넘었으며 ELECTRA-Large도 RoBERTa, XLNet보다 적은 parameter와 연산량으로 그들을 뛰어넘었음
- ELECTRA는 ALBERT보다 GLUE 에서 좋은 성능을 보였으며 SQuAD 2.0에서는 SOTA를 달성
- language representation learning에서 real token과 대체된 token을 판별하는 discriminative task는 현존하는 generative 접근법보다 compute-efficient, parameter-efficient 함을 논문에서 보임
2. Method
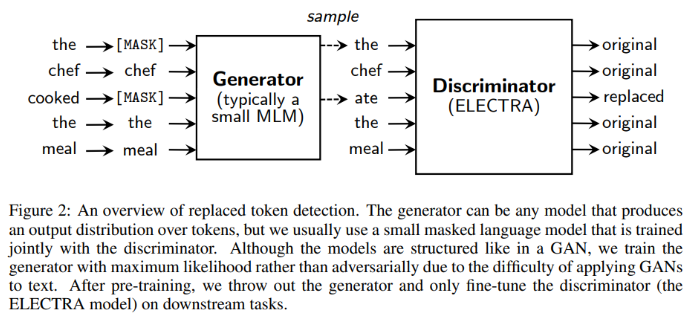
- Generator와 Discriminator는 input tokens $x = [x_1, ..., x_n]$ 을 contextualized vector representation인 $h(x) = [h_1,...,h_n]$으로 매핑한다
- $x_t$=[MASK]인 position t에서 generator는 softmax layer를 사용하여 생성 가능한 tokens에 대한 확률을 output으로 함 (e는 token embedding)

- discriminator는 sigmoid를 사용하여 token $x_t$가 generator에서 온 것인지 real data에서 온 것인지 판별

- Generator는 input sequence에서 tokens을 고르고 masking하고 masking 되기 전 token을 추측하는 MLM의 역할을 한다
- 아래 수식들로 전체 과정을 정리할 수 있다

- masking할 k%의 token position을 고름 ($m_i$, 보통 k는 15%)
- 위에서 고른 position의 token을 [MASK]로 대체 ($x^{masked}$)
- generator를 사용하여 [MASK] tokens의 본래 token을 예측하고 대체 ($x^{corrupt}$, MLM과 다른 부분)
- generator는 [MASK] token의 본래 tokens을 정확히 예측하도록 maximum likelihood로 학습
- discriminator는 generator가 정확히 본래 token으로 [MASK] token을 대체하였으면 real로 판별, 그렇지 않을 경우 fake로 판별하도록 학습
3. Experiments
3.1. Experimental Setup
- General Language Understanding Evaluation(GLUE) benchmark, Stanford Question Answering(SQuAD) dataset에서 평가
- BERT와 동일한 Wikipedia, BooksCorpus의 3.3B tokens으로 학습
- Large model의 경우 XLNet과 동일하게 ClueWeb, CommonCrawl, Gigaword 데이터를 추가로 사용하여 33B tokens으로 학습
- GLUE fine-tuning을 위해 ELECTRA 최상단에 간단한 linear classifier를 추가
- SQuAD에서는 XLNet의 question answering module을 ELECTRA 최상단에 추가
3.2. Model Extensions
Weight Sharing
- Generator와 Discriminator의 크기가 동일하다면 모든 weight를 sharing 가능
- 하지만 discriminator보다 작은 size의 generator가 효율적인 것을 실험으로 발견하였기 때문에 작은 size의 generator를 사용
- token embedding, positional embedding만 sharing
- weight sharing strategy에 따른 GLUE scores
- no tying: 83.6
- token embeddings tying: 84.3
- all weights tying: 84.4 (generator와 discriminator의 크기가 같아야 한다는 제약이 성능을 저해)
- discriminator는 input sequence에 주어진 token 또는 generator가 대체한 token만 update 하지만, generator는 softmax를 통해 모든 token embedding을 densely update하기 때문에 저자는 tied token embedding이 ELECTRA의 성능을 향상시킨다는 가설을 세움 (MLM에 효과적)
Smaller Generators
- generator와 discriminator의 크기가 같다면 MLM의 2배의 연산을 마쳐야 1 step 학습
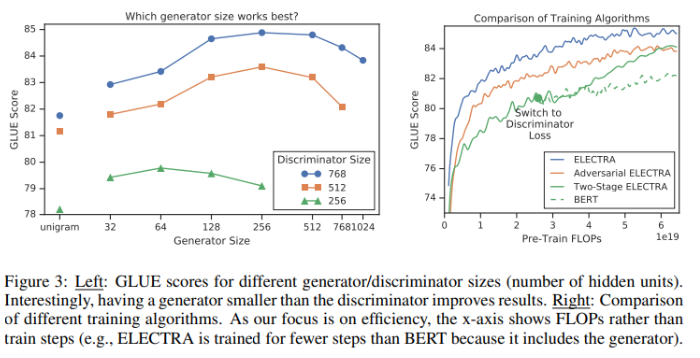
- generator의 layer size가 discriminator의 1/4 ~ 1/2 일 때 대체로 좋은 성능을 보이는데 이는 generator, discriminator의 balance 문제와 관련이 있다
- large generator의 경우 discriminator에게 너무 어려운 task를 제시하여 학습에 차질이 생길 수 있음
Training Algorithms
joint training, adversarial training, two-stage training 등 여러 학습 방식을 실험
two-stage training 방식
- generator를 $L_{MLM}$으로 n steps 학습
- discriminator의 weight를 generator의 weight로 initialize, generator를 freeze 시키고 $L_{disc}$로 discriminator를 n steps 학습
강화학습을 사용하여 generator에서 sampling하는 방식으로 Adversarial training을 하였으나 GANs for text(Caccia et al., 2018)에서 언급한 문제로 좋은 성능을 보이지 못하였음( low-entropy output distribution, MLM과 adversarial의 조합)
위 Figure 3의 오른쪽 표를 보면 joint training이 가장 좋은 성능을 보이는 것을 알 수 있음
3.3. Small Models
- 연구의 목표는 pre-training의 효율을 증가시키는 것이기 때문에 single GPU에서도 빠르게 학습할 수 있는 작은 모델로 실험
- BERT-Base 세팅에서 시작하여 sequence length를 512에서 128, batch size를 256에서 128, hidden dimension size를 768에서 256으로, token embedding을 768에서 128로 줄였다
- 공정한 비교를 위해 BERT-Small을 같은 hyperparameters setting으로 함께 학습

- ELECTRA-Small은 같은 parameters 수를 가진 BERT-Small 보다 좋은 성능을 보임, 훨씬 큰 모델인 GPT 보다도 좋은 성능
- ELECTRA-Base는 GLUE score 기준 BERT-Base, BERT-Large의 성능을 넘어섬
3.4. Large Models
- replaced token detection pretraining task의 효과를 측정하기 위해 큰 ELECTRA model을 학습
- 400k steps 학습한 ELECTRA-400K (RoBERTa의 1/4 연산량), 1.75M steps 학습한 ELECTRA-1.75M (RoBERTa와 비슷한 연산량)
- batch size 2048, XLNet pretraining data(RoBERTa data와 비슷) 사용
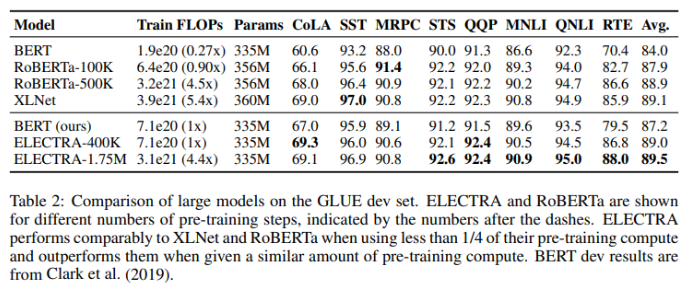
- ELECTRA-400K는 RoBERTa-500K, XLNet 보다 4~5배 적은 연산으로 비슷한 성능을 기록
- ELECTRA-1.75M은 RoBERTa-500K, XLNet과 비슷한 연산기준 더 좋은 성능을 보임
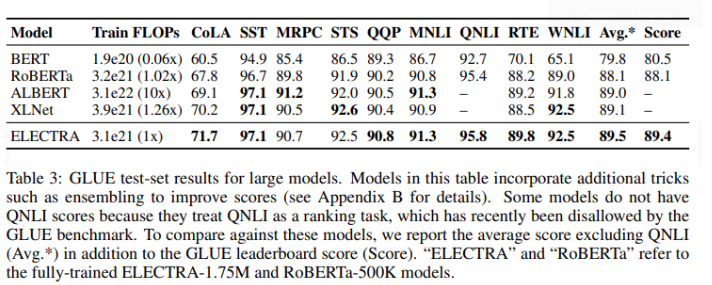
- 여러 fine-tuning skills을 적용하고 비교한 결과
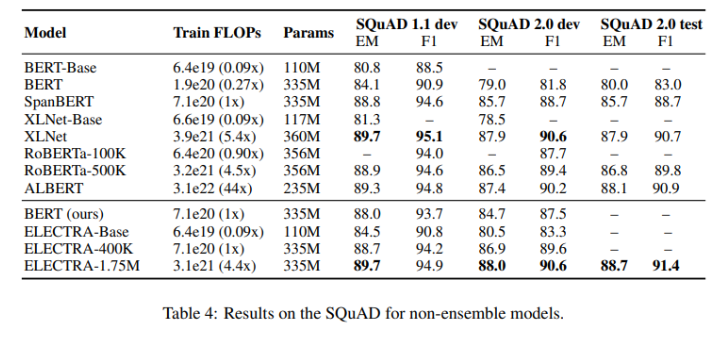
- SQuAD에서도 GLUE에서와 마찬가지로 ELECTRA는 동일한 연산량 기준 MLM based method보다 높은 점수를 기록
- ELECTRA-1.75M은 SOTA를 기록
3.5. Efficiency Analysis
ELECTRA의 성능에 기여한 정확한 design이 무엇인지 확인하기 위한 실험 진행
- ELECTRA 15%
- ELECTRA와 동일하나 discriminator loss가 15%의 tokens에서만 발생
- Replace MLM
- MLM과 동일하나 [MASK] token으로 바꾸지 않고 generator의 output으로 대체
- fine-tuning에 존재하지 않는 [MASK] token을 pretraining에서도 제거한 것의 효과만을 확인하기 위함
- All-Tokens MLM
- Replace MLM과 동일하나 model은 masked out된 tokens만이 아닌 모든 tokens의 본래 token을 예측
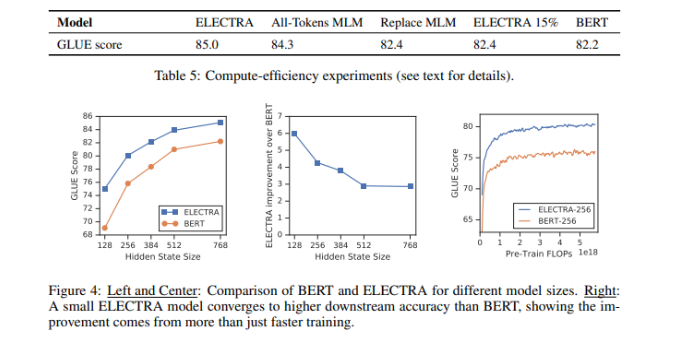
- ELECTRA 15%는 ELECTRA에 비해 성능이 크게 떨어졌는데, 모든 input tokens에 대해 loss가 발생하는 모델 디자인이 효과적이었음을 알 수 있음
- Replace MLM이 BERT보다 성능이 살짝 좋은데 이는 [MASK] token의 pre-training, fine-tuning에서의 mismatch 문제가 BERT의 성능을 해쳤음을 알 수 있음 (BERT는 masked out된 token의 10%를 masking하지 않고 그대로 두어 이 문제를 해결하려 하였으나 완벽히 해결하지 못하였음)
- All-Tokens MLM의 경우 BERT와 ELECTRA의 성능 차이의 대부분을 메꾸는데 이는 BERT와 ELECTRA의 차이는 대부분 all token 에서의 학습이 차지하며, pre-train, fine-tune mismatch가 나머지 작은 부분을 차지함을 뜻함
- 저자는 ELECTRA는 BERT와 다르게 각 position에서 모든 possible tokens에 대한 distribution을 모델링하지 않기 때문에 더 parameter-efficient 할 것이라고 추측
4. Conclusion
- language representation 학습을 위한 새로운 self-supervised task replaced token detection을 제시
- key idea는 text encoder를 small generator network가 만든 실제 같은 negative-samples와 real token을 알맞게 구분하도록 학습시키는 것
- MLM보다 연산 효율이 좋으며 downstream task에서 성능이 좋았음
- 컴퓨팅 자원이 없는 연구자와 실무자들도 pre-trained text encoders를 사용할 수 있기를 희망
- downstream task에서 성능도 중요하지만 효율성에 대한 연구도 중요하며 이를 future work으로 제시
- evaluation metrics 뿐만 아니라 parameter 수, compute usage를 기록하기를 원함
후기 & 정리
- MLM과 달리 generator, discriminator 구조를 사용한 모델로 pre-training하는 replaced token detection을 제시
- replaced token detection은 masked out된 tokens에서만 학습하는 것이 아닌 모든 input tokens에 대해 학습하기 때문에 효율적인 샘플링으로 인해 학습이 빠름
- 비슷한 연산량 기준 ELECTRA는 BERT, XLNet, RoBERTa보다 GLUE, SQuAD에서 좋은 점수를 기록
- 점점 NLP에서 거대 언어모델, 많은 데이터, 많은 컴퓨팅 리소스의 중요성이 부각되던 시점에 compute-efficient에 집중한 논문
Reference
[0] Kevin Clark et al. (2020). "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators". https://arxiv.org/abs/2003.10555
ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
Masked language modeling (MLM) pre-training methods such as BERT corrupt the input by replacing some tokens with [MASK] and then train a model to reconstruct the original tokens. While they produce good results when transferred to downstream NLP tasks, the
arxiv.org



