
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- ue5.4
- CNN
- Diffusion
- cv
- multimodal
- Font Generation
- UE5
- 모션매칭
- Unreal Engine
- NLP
- 생성모델
- 언리얼엔진
- dl
- WinAPI
- motion matching
- deep learning
- BERT
- Stat110
- ddpm
- animation retargeting
- GAN
- 딥러닝
- RNN
- 디퓨전모델
- WBP
- 오블완
- userwidget
- Few-shot generation
- 폰트생성
- Generative Model
Archives
- Today
- Total
Deeper Learning
RoBERTa: A Robustly Optimized BERT Pretraining Approach 본문
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov, Facebook AI, (2019.07)
Abstract
- 언어모델 사전학습은 큰 성능향상을 가져오지만 여러 접근법에 대한 비교가 어려움
- BERT의 여러 주요 hyperparameters, training data size의 효과를 정밀하게 측정한 replication study를 제시
- BERT가 undertrained 되었고 성능향상의 여지가 있음을 확인
- 저자가 제시한 모델은 GLUE, RACE, SQuAD에서 SOTA를 달성
1. Introduction
- ELMo, GPT, XLM, XLNet과 같은 Self-training 모델은 큰 성능향상을 가져왔지만 어떤 method가 contribute 하였는지 분석이 매우 어려움
- private data 사용, 많은 학습 비용으로 인해 여러 training approach의 contribute를 정확히 측정이 쉽지 않음
- BERT가 상당히 undertrained 되었다는 것을 발견했고 BERT 모델 학습의 개선된 레시피를 제시하고 그것을 RoBERTa로 이름붙임
- 저자의 modifications은 간단
- model을 더 큰 batch로, 더 많은 데이터로, 더 길게 학습
- NSP(Next sentence prediction)을제거
- longer sequences로 학습
- masking 패턴을 변경
- 다른 privately data size에 견줄만한 새로운 large dataset인 CC-NEWS를 수집
- RoBERTa는 BERT의 GLUE, SQuAD에서의 성능을 뛰어넘었으며 추가 데이터를 사용하여 길게 학습할 때 RoBERTa는 public GLUE leaderboard에서 88.5점을 달성 (이전 SOTA인 XLNet은 88.4)
- MNLI, QNLI, RTE, STS-B 총 9개의 GLUE task 중 4개에서 SOTA를 달성
- SQuAD와 RACE에서도 SOTA 달성
- BERT의 masked language model의 학습 목표를 XLNet의 perturbed autoregressive language modeling과 같은 최신 기법과 경쟁 가능하도록 개선
Contribution
- BERT의 downstream task의 성능을 높이기 위한 design choices, training strategies를 제시
- CC-NEWS 데이터셋을 pre-training에 사용하여 성능 향상
- masked language model을 사용한 pre-training이 알맞은 design choice하에서는 다른 최신 pre-training method에 견줄만한 효과를 가짐을 제시
2. Background
BERT background
Masked Language Model (MLM)
- input sequence의 몇몇 token은 special token [MASK]로 대체
- masked token을 predict하고 cross-entropy loss로 학습
- input token의 15%를 선택하고 그중 80%를 [MASK]로 10%를 random vocabulary token으로 10%를 그대로 둔다
Next Sentence Prediction (NSP)
- 두 segment가 original text에서 연속되는 segment인지를 이진 분류
- negative examples은 다른 document에서 추출한 segment로 생성
- NSP는 Natural Language Inference와 같이 두 sentence pair의 관계에 대한 reasoning이 필요한 downstream task의 성능 향상을 위해 디자인되었다
Data
- BERT는 Bookcorpus (Zhu et al., 2015)와 English Wikipedia 데이터로 총 16GB의 text로 학습되었다
3. Experimental Setup
- $\beta_2=0.98$, Adam epsilon term, large batch로 학습 안정성을 증가
- original BERT(Devlin et al., 2019) 는 학습 속도 향상을 위해 초기 90%의 model update에는 512가 아닌 128 max sequence length를 사용, 그 후 10%의 학습에 512 sequence length 설정을 적용하여 positional embedding을 학습
- RoBERTa에서는 위와 달리 512 max sequence length로 초기부터 끝까지 학습
- Bookcorpus, CC-News, OpenWebText, Stories dataset을 사용하여 총 160GB의 데이터로 학습
4. Training Procedure Analysis
BERT base와 동일한 model 아키텍처를 사용 (L=12, H=768, A=12, 110M params)
4.1. Static vs. Dynamic Masking
- BERT는 data 전처리 과정에서 masking을 적용하는 static masking, 매 epoch 같은 방식으로 masking된 문장이 주어지는 것을 방지하기 위해 하나의 데이터를 10개로 복사하고 random masking을 적용함
- static masking 방식의 문제는 40 epoch을 학습한다고 하면 같은 mask가 적용된 데이터가 학습 도중 4번 중복으로 주어지는 것
- Dynamic masking은 문장이 모델에 input으로 주어질 때 masking을 적용하는 형태로 larger datasets에서 많은 step pretraining 할 때 중요하다.

- Dynamic masking을 적용할 경우 조금의 성능 향상이 있었기 때문에 dynamic masking을 사용
4.2. Model Input Format and Next Sentence Prediction
- original BERT는 두 sequence를 같은 document에서 50%, 서로 다른 document에서 50% 추출하여 전자를 positive example, 후자를 negative example로 labeling하고 NSP loss를 적용
- SEGMENT-PAIR+NSP (BERT)
- input은 pair of segments (multiple natural sentences)
- combined length는 최대 512 tokens
- SENTENCE-PAIR+NSP
- segment보다 작은 단위인 sentence pair가 input
- 512 tokens 보다 combined pair의 token이 적은 경우가 많아 batch size를 늘려 이를 보완
- FULL-SENTENCES
- NSP loss를 사용하지 않음
- input은 한 개 또는 그 이상의 documents에서 연속적으로 샘플링된 full sentences
- total length는 최대 512 tokens
- document가 끝나면 다음 document에서 샘플링하고 extra separator token을 배치
- DOC-SENTENCES
- input은 FULL-SENTENCES와 비슷하나 cross document가 아님
- document의 끝 부분에서 샘플링된 문장의 경우 512 tokens보다 작기 때문에 이를 보완하기 위해 batch size를 늘려 FULL-SENTENCES와 비슷한 token lengths를 만들었음
- NSP loss를 사용하지 않음
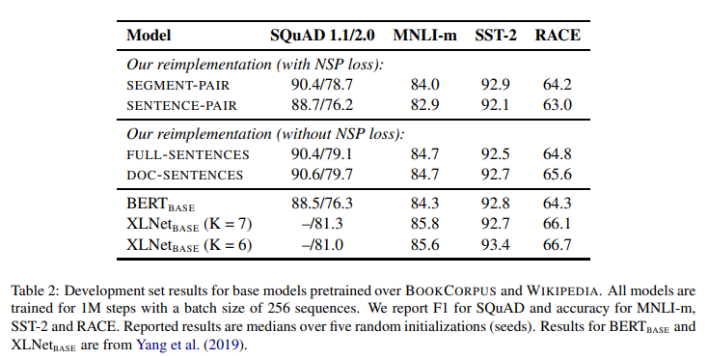
- SENTENCE-PAIR의 점수가 SEGMENT-PAIR의 점수보다 낮은데 이에 저자는 model이 long-range dependencies를 학습할 수 없기 때문이라는 가설을 세웠다
- NSP loss를 제거할 경우 성능 하락이 있다고 주장하던 BERT 논문과 달리 NSP loss를 제거한 method의 점수가 조금 대체로 높은데 이는 original BERT에서는 SEGMENT-PAIR의 input format을 사용하면서 NSP loss를 제거했기 때문이라고 추측된다
- DOC-SENTENCES의 점수가 조금 더 높은데 batch size를 일정하게 유지하기 위해 FULL-SENTENCES를 앞으로 실험에 사용
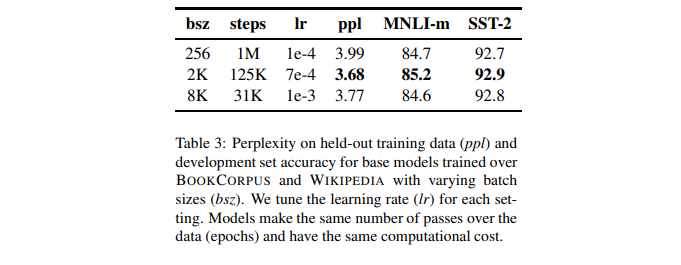
4.3. Training with large batches
4.4. Text Encoding
- BPE(Byte-pair encoding)은 학습 corpus에 따라 sub-word unit으로 text를 나눈다
- BERT는 학습 corpus에 휴리스틱 하게 토크나이징을 하고 character-level의 BPE를 학습 (30k vocab)
- RoBERTa는 GPT의 byte 단위 BPE를 학습하였고 50k의 vocab size를 사용
- Byte 단위의 경우 성능이 end-task performance가 조금 떨어졌지만 universal-encoding scheme의 장점이 적은 성능 차이보다 중요하다고 생각하여 byte-level BPE를 채택
5. RoBERTa
- Robustly optimized BERT approach(RoBERTa)
- dynamic masking 사용
- FULL-SENTENCES without NSP loss
- large mini-batches
- larger byte-level BPE
- 160GB 데이터로 pretraining (BERT=16GB)
- 기존 연구들에서 중요하게 다뤄지지 않은 2개의 요소에 대한 조사
- pretraining data의 중요성
- number of training passes through the data (training longer)
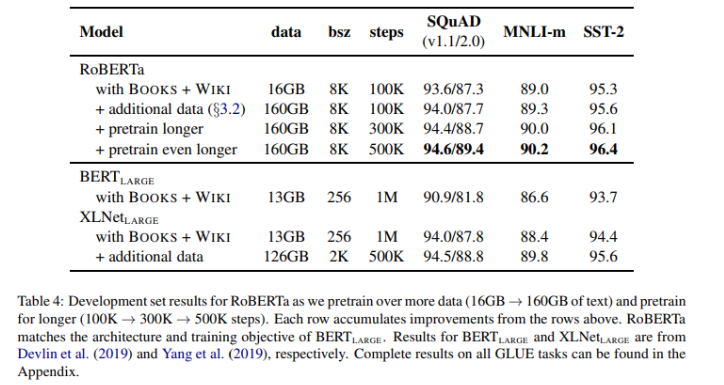
- 데이터셋을 추가함에 따라 성능이 모든 downstream task에서 향상되는 것을 관찰하여 pretraining에서 data size와 diversity의 중요성을 검증
- 500K step까지 길게 학습일 시켰음에도 불구하고 overfitting이 나타나지 않았으며 추가 학습으로 인한 성능 향상을 관찰
GLUE Results
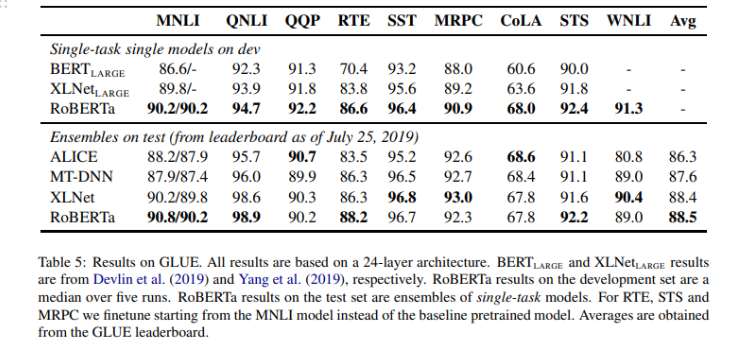
- 9개 중 4개의 task에서 SOTA를 달성, 전체 task 평균 점수도 SOTA
SQuAD Results
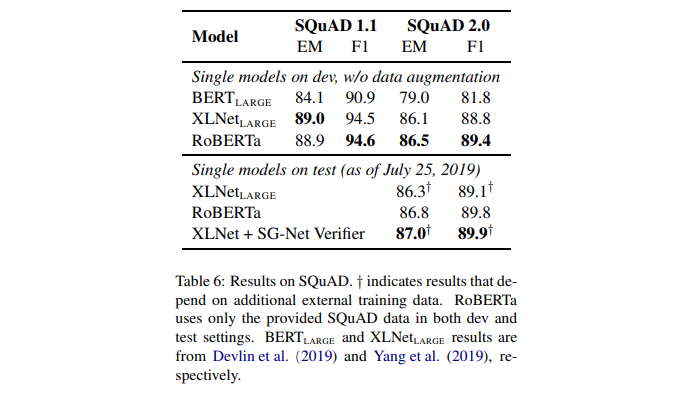
- SQuAD 1.1v에서는 XLNet과 비슷한 점수를 달성하였고 SQuAD 2.0v에서 extra 데이터를 추가로 사용하지 않았음에도 매우 좋은 성능을 보임
RACE Results
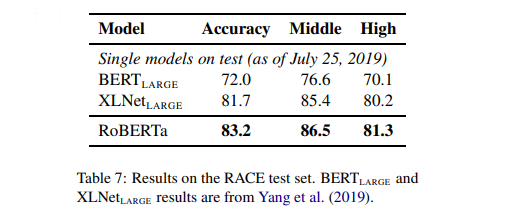
- RoBERTa SOTA 달성
6. Conclusion
- 더 길게 학습, 더 큰 batch size로 학습, NSP loss를 제거, 더 긴 sequence로 학습, dynamic masking 적용으로 original BERT의 성능을 끌어올린 RoBERTa를 제시
- GLUE, RACE, SQuAD에서 SOTA를 달성 (multi-task finetuning, additional data를 사용하지 않음)
- BERT에서 간과한 design decision의 중요성을 보여줌
- BERT의 pretraining objective가 최근 제시된 대안들과 견줄만하다는 것을 보여줌
- 새로운 데이터셋인 CC-News를 소개
- RoBERTa의 finetuning, pretraining code를 공개 (https://github.com/facebookresearch/fairseq)
정리 & 후기
- BERT를 개선한 RoBERTa를 제시하였고 GLUE, RACE, SQuAD에서 SOTA를 달성
- 더 길게 학습
- 더 큰 batch size로 학습
- NSP loss를 제거
- 더 긴 sequence로 학습
- dynamic masking 적용
- 더 많은 데이터로 사전학습
- downstream task에서 성능을 끌어올리기 위해서는 pretraining 모델의 scale도 중요하지만 여러 design choice와 pretraining objective, pretraining data 또한 중요하다는 것을 알 수 있음
- BERT에서 NSP를 제거하면 성능이 하락한다는 것을 BERT 논문에서 보았을 때 NSP objective가 중요하다고만 생각을 하였는데 input format을 segment pair로 유지하면서 NSP를 제거하였기 때문에 성능 하락이 있었을 것이라는 저자의 가설이 합리적이라고 생각함
Reference
[0] Yinhan Lui et al. (2019). "RoBERTa: A Robustly Optimized BERT Pretraining Approach". https://arxiv.org/abs/1907.11692
[1] Jacob Devlin et al. (2019). "BERT: Pre-training of deep bidirectional transformers for language understanding". https://arxiv.org/abs/1810.04805
'AI > Deep Learning' 카테고리의 다른 글
| ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators (0) | 2022.06.09 |
|---|---|
| ALBERT: A Lite BERT for Self-supervised Learning of Language Representations (0) | 2022.06.05 |
| VQ-VAE: Neural Discrete Representation Learning (0) | 2022.04.14 |
| f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization (0) | 2022.04.07 |
| GAN: Generative Adversarial Nets (0) | 2022.03.28 |
'AI/Deep Learning' Related Articles
more




Comments