
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- motion matching
- 언리얼엔진
- 폰트생성
- Few-shot generation
- GAN
- ue5.4
- Unreal Engine
- Stat110
- WBP
- userwidget
- animation retargeting
- 생성모델
- 디퓨전모델
- RNN
- 딥러닝
- ddpm
- Font Generation
- UE5
- Diffusion
- Generative Model
- BERT
- cv
- NLP
- CNN
- WinAPI
- multimodal
- 오블완
- dl
- deep learning
- 모션매칭
- Today
- Total
Deeper Learning
BERT (Bidirectional Encoder Representations from Transformers) 본문
BERT (Bidirectional Encoder Representations from Transformers)
Dlaiml 2021. 4. 18. 09:29BERT
BERT는 구글에서 개발한 언어 모델로 2018년 10월 논문 출시 후 다수의 NLP 태스크에서 SOTA를 기록하였다.
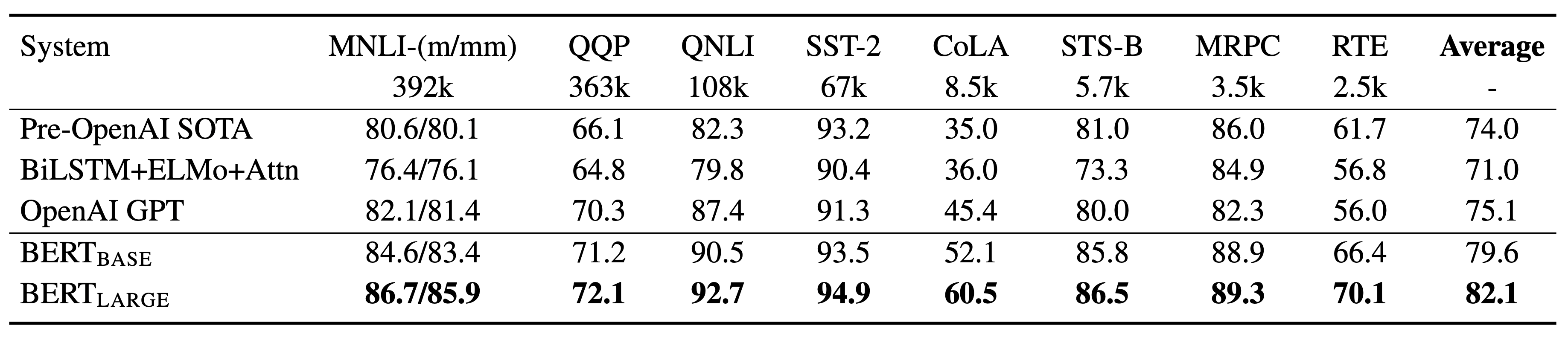

BERT는 Transformer 기반 모델로 Encoder 부분만을 사용한다.


Input은 두 개의 문장을 tokenizer를 사용하여 토큰화 시키고 문장의 시작에 special token인 [CLS]를 추가하고 두 문장 사이와 두 번째 문장의 끝에 [SEP] 토큰을 삽입한다.

BERT의 input embedding은 input sentence의 tokenizing 형태인 token embedding, 앞 문장, 뒷 문장을 0 or 1로 나타내는 Segment Embedding, RNN과 달리 poistiion정보가 내포되어있지 않기 때문에 이를 위해 추가한 Position embedding의 합이다.
Pre-training
기존의 left-to-right, right-to-left 학습이 가지는 한계를 극복하기 위해 논문에서 저자는 BERT를 Pre-training 하기 위한 2가지 unsupervised tasks를 제시하였다.
1. Masked LM (MLM)
Deep Bidirectional Model은 left-to-right, right-to-left 모델보다 강력하지만 학습하는데 큰 문제가 있다.
학습 과정이 양방향으로 이루어지기 때문에 각 단어가 prediction이 이루어지기 전에 모델에 이미 노출이 된다는 점이다. (see itself)
ex) I went to the shop에서 p(to | I, went, the, shop)에 대한 학습이 이루어지고 다음에 p( the | I, went, to, shop)을 추론할 경우 모델의 예측은 trivial 한 "the"가 될 것이다. to를 예측하는 첫 번째 단계에서 이미 "the"를 관찰했기 때문이다.
see itself 문제를 해결하기 위해 [MASK] 토큰을 랜덤한 토큰에 부여하여 모델이 기억에 의존한 자명한 해를 내지 못하도록 noise를 추가하였다.

Pre-training과 fine-tuning시 주어지는 입력이 다르기 때문에 (MASK 유무) 이를 어느 정도 완화하기 위해 아래와 같은 처리를 추가로 하였다.
Training 데이터에서 15%의 토큰을 예측해야할 값으로 선정하고, 그중 80%를 [MASK] 토큰으로 대체하고 10%는 랜덤 토큰 10%는 그대로 둔다. (논문 제시 값)
2. Next Sentence Prediction (NSP)
QA(Question Answering), NLI(Natural Language Inference)는 두 문장의 관계의 학습이 필요한 task다. 기존 Language Modeling은 이러한 관계를 사전학습을 통해 얻지 못한다.
아래 구조도의 첫 번째 output인 C는 NSP를 위한 토큰으로 label은 IsNext, NotNext로 BInary Classification이다.

BERT는 사전학습을 끝내고 Fine-tuning을 적용하면 다중 태스크를 수행할 수 있다.

Korean BERT
토크나이저의 종류에 따라 성능의 차이가 나기 때문에 알맞은 토크나이저를 선정하는 것 또한 중요하다.


entity 정보를 BERT 모델에 전달하기 위해 추가로 speicial token인 [ENT], [/ENT]를 사용

추가로 input embedding에 Entitiy or not 정보를 가지고 있는 Entity embedding을 더하여 input embedding을 구성한 결과
KorQuAD dataset에서 BERT 모델의 성능이 향상되었다.
Vs GPT

AutoEncoder는 원래 이미지를 같은 차원의 output을 가지는 네트워크에 통과시켜 output과 input이 동일하도록 학습시킨다.
모델은 input을 더 작은 차원에서도 잘 표현할 수 있도록 압축된 형태의 feature를 학습하게 된다.
학습이 끝나면 해상도가 낮거나 모자이크가 있는 이미지 또한 복원이 가능하다.
BERT도 비슷한 관점으로 보면 원래 문장이 MASK에 의해 가려진 문장이 input이 되며 output은 가려진 부분의 단어이다.
원래 문장을 잘 표현할 수 있는 representation을 학습하는 것이다.
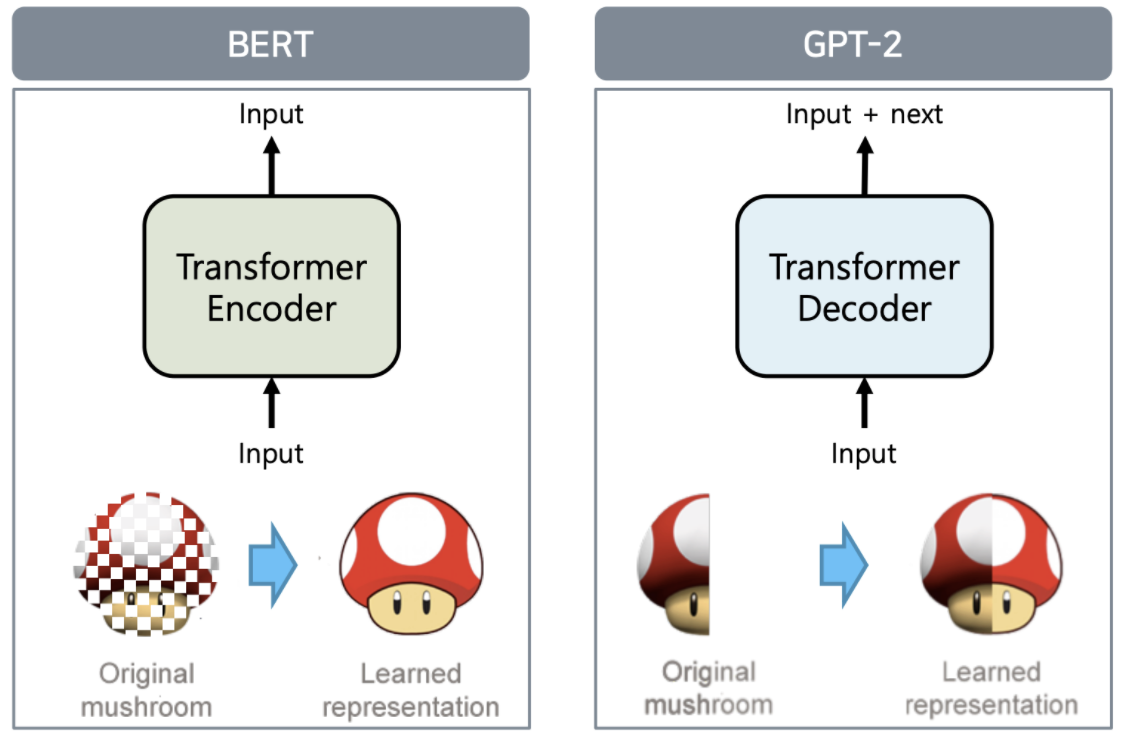
GPT-2는 BERT와 달리 단방향으로 학습이 이루어진다.
Reference
[1] Jacob Devlin et al. (2018). "BERT: Pre-training of Deep Bidrectional Transformers for Language Understadning". arXiv:181.004805 [cs.CL] url
[2] The Illustarated BERT, ELMo, and co. (How NLP Cracked Transfer Leanirng). Jav Alammar url
[3] Naver Boostcamp AI-Tech (Smilegate.AI 김성현 마스터)
'AI > Deep Learning' 카테고리의 다른 글
| Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN) (0) | 2021.07.27 |
|---|---|
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (0) | 2021.05.08 |
| Multimodal Learning (0) | 2021.03.17 |
| R-CNN, Fast R-CNN, Faster R-CNN (0) | 2021.03.14 |
| Semantic Segmentation (0) | 2021.03.12 |



