

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- deep learning
- NLP
- Few-shot generation
- CNN
- Generative Model
- WinAPI
- inductive bias
- ddpm
- Stat110
- Font Generation
- 모션매칭
- RNN
- animation retargeting
- cv
- multimodal
- UE5
- 언어모델
- 언리얼엔진
- 생성모델
- dl
- motion matching
- 디퓨전모델
- GAN
- Diffusion
- WBP
- 폰트생성
- ue5.4
- BERT
- userwidget
- 딥러닝
- Today
- Total
Deeper Learning
XLNet: Generalized Autoregressive Pretraining for Language Understanding 본문
XLNet: Generalized Autoregressive Pretraining for Language Understanding
Dlaiml 2021. 5. 8. 01:55XLNet
XLNet은 구글 연구팀이 발표한 모델로 당시 SOTA를 여러 자연어 처리 태스크에서 달성하였다.
Transformer-XL을 개선한 모델로 eXtra Long Network로 트랜스포머 모델보다 더 긴 문맥을 볼 수 있다.
AE방식의 언어모델인 BERT의 장점과 AR방식의 언어 모델인 GPT의 장점을 갖춘 Permutation language modeling을 사용함.
BERT에는 몇가지 한계가 존재한다.
- MASK 토큰이 독립적으로 예측됨
- Token 사이의 관계 학습이 불가능하다 ( 서로 독립적이라는 가정하에 있음 )
- Embedding length의 제한으로 Segment 간 관계 학습 불가능
예를 들어 New York is the city 라는 시퀀스에서 New York 두 토큰이 [MASK] 토큰으로 대체될 경우 [MASK] [MASK] is the city에서
BERT는 is the city의 정보를 가지고 New , York를 독립적으로 예측한다. 하지만 만약 먼저 New를 예측한 경우, York를 예측할 때 이미 앞서 예측한 New의 정보를 활용한다면 York의 확률 분포는 전과 크게 달라진다.
GPT는 단방향 학습의 한계를 가진다.

AR방식의 LM은 다음 시퀀스의 분포를 예측하며 Text generation에 강점을 가지고 AE방식의 pre-trained LM은 양방향으로 MASK를 예측하며 학습이 이루어져 전체적인 문맥 파악에 강점을 가진다.
Permutation language modeling을 사용하여 XLNet은 두 방식의 장점을 모두 지닌다.
Permutation language modeling

모든 token을 가능한 순열 조합에 대해 모두 학습이 이루어지기 때문에 문맥 전체의 정보를 파악하는 AE LM의 장점을 가지며, 다음 token의 예측은 순차적으로 AE방식으로 이루어져 token 간 관계의 학습이 가능하다.
Permutation language model의 학습에서 유의할 점은 아래와 같다.
- (좌상단) 3->2->4->1 순열에서 처음 3번 토큰을 예측할 때는 3번 토큰의 정보를 사용하지 않는다.
- (우상단) 2->4->3->1 순열에서 3번째로 3번 토큰을 예측하는데 이 때 앞서 등장한 2, 4번 토큰의 정보만을 사용한다.
- 나머지 아래 행의 그림도 위와 같은 방식


실제 학습과정에서 Permutation은 input token을 뒤섞는 것이 아닌 attention mask를 조정하여 이루어진다.
3->2->4->1 순으로 순열 조합이 생성되면
X O O O
X X O X
X X X X
X O O X
모양으로 마스킹이 이루어진다. 첫 번째 행인 token 1은 3, 2, 4의 정보를 참고할 수 있으며, token 2는 3의 정보, token 4는 2,3의 정보, 첫 번째로 예측이 이루어지는 token 3은 과거 메모리 정보 만을 사용하여 예측이 이루어진다.
위 그림에서 빨간 세로선은 AR방식 학습을 위해 추론하여야 할 부분을 나누는 선으로 hyperparemeter K로 조정이 가능하다.
permutation 이후 예측을 통한 학습과정에서 다음으로 예측해야할 토큰이 몇 번째 토큰인지 알 수 없다는 문제가 있다. ( Permutation이 없다면 다음으로 예측해야 할 토큰은 전 토큰의 position + 1 )
1 2 3 4 토큰이 3 4 1 2, 3 4 2 1로 permutation 변환되면 모델은 두 시퀀스에서 동일하게 3 4의 정보를 가지고 다른 1 2의 예측을 해야한다.
위의 모순을 해결하기 위해 Two Stream Self Attention을 사용한다.
Two-Stream Self-Attention for Target Aware Representation
Query와 Key, Value에 대해 다른 Masking 기법을 사용하는 Two-Stream Self-Attention for Target Aware Representation을 논문에서 제시하였다.
Two Stream Self Attention은 Query Stream과 Content Stream으로 나누어 다른 2개의 Masking 기법을 적용한다.

Query Stream에서 Key와 Value는 Query의 시점인 t 이전의 정보를 활용하여 t 시점의 위치 정보와 random하게 초기화된 벡터를 사용한다.
Content Stream은 Transformer의 방식과 매우 유사하다. Content Stream은 t시점의 위치 정보와 토큰 임베딩 정보를 모두 사용한다.
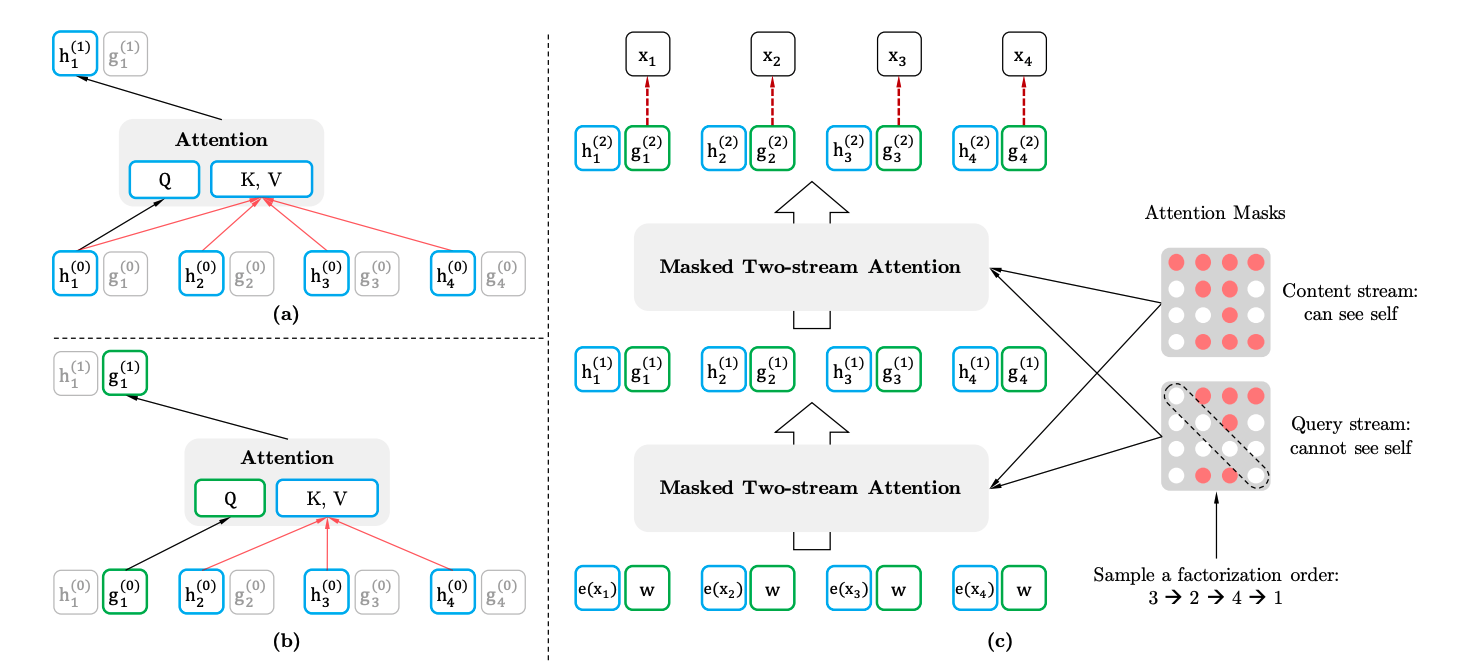
위의 그림 a)는 Content Stream, b)는 Query Stream으로 g는 토큰의 의미가 임베딩된 정보가 아닌 위치+랜덤 초기화 값을 가진다.
이렇게 2가지 방법으로 Attention이 구성되어 Two-Stream Self Attention이라는 이름을 가진다.
동일한 input을 받아 다른 output을 내야 옳게되는 모순은 이제 해결되었다.
위치정보를 추가로 활용할 경우 Permutation LM은 다음과 같이 동작한다.
New York is the city -> Permutation -> is city the York New
is, city, the의 정보를 가지고 다음 단어를 예측할 때 York와 New의 확률분포는 동일하게 학습된다.
주어진 정보가 is city the로 동일하고 다음 단어 York는 본래 문장의 2번째 토큰이었다는 정보가 g벡터에 들어있기 때문이다.
이제 is city the라는 정보가 주어졌을때 York, New의 확률분포는 달라지게 된다.
XLNet은 위 그림 (c)에서 볼 수 있듯이 마지막 g를 사용하여 예측을 한다.
Relative positional encoding & Segment Recurrent
Transformer-XL의 Relative positional encoding과 Segment Recurrent를 차용하였다. ( Transformer-XL 포스트에 작성 예정)
XLNet에서는 Relative positional encoding을 적용하여 token 간 상대적인 거리 정보를 포함하여 positional encoding이 이루어진다.

Summary
XLNet은 언어모델에 적합한 AR 방식으로 pre-train이 이루어지면서 BERT의 문맥 파악 능력까지 갖춘 모델이다.

같은 문장을 BERT와 XLNet으로 학습할 경우 XLNet은 BERT에서 불가능한 New와 York token의 의존성에 대한 학습이 가능하다.
BERT는 마스킹된 토큰을 독립적으로 추론하기 때문이다.
BERT는 또한 실제 fine-tuning 데이터와 pre-training 데이터 사이의 간극( MASK 토큰 )이 있다.
XLNet에서는 GPT와 같은 AR방식의 pre-traning method를 사용하여 이를 해결하였다.

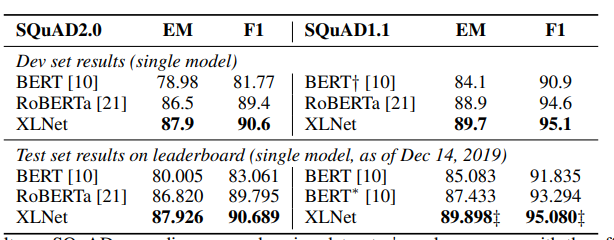
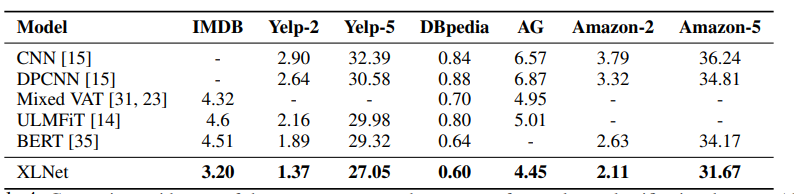
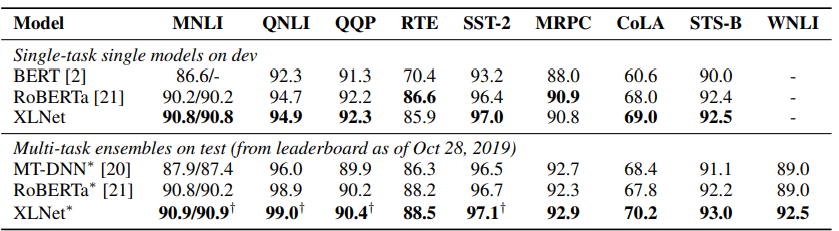
그 결과 여러 NLP 태스크, 여러 데이터셋에서 SOTA를 기록하였다.
Reference
[1] Peter Shaw. (2019). "Self-Attention with Relative Positional Encoding". arXiv:1803.02155 [cs.CL] url
[2] ratsgo.github.io/natural%20language%20processing/2019/09/11/xlnet/
[3] ai-information.blogspot.com/2019/07/nl-041-xlnet-generalized-autoregressive.html
'AI > Deep Learning' 카테고리의 다른 글
| cGANs with Projection Discriminator (0) | 2021.08.07 |
|---|---|
| Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN) (0) | 2021.07.27 |
| BERT (Bidirectional Encoder Representations from Transformers) (0) | 2021.04.18 |
| Multimodal Learning (0) | 2021.03.17 |
| R-CNN, Fast R-CNN, Faster R-CNN (0) | 2021.03.14 |



