
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- UE5
- dl
- motion matching
- Diffusion
- Stat110
- RNN
- NLP
- ddpm
- BERT
- Generative Model
- WBP
- CNN
- 모션매칭
- Few-shot generation
- 폰트생성
- 오블완
- ue5.4
- userwidget
- cv
- GAN
- 생성모델
- animation retargeting
- Unreal Engine
- WinAPI
- 딥러닝
- multimodal
- 언리얼엔진
- deep learning
- Font Generation
- 디퓨전모델
Archives
- Today
- Total
Deeper Learning
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN) 본문
AI/Deep Learning
Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization (AdaIN)
Dlaiml 2021. 7. 27. 22:03Abstract
- 기존 neural style transfer의 경우 느린 iterative optimization process를 거친다.
- 리얼타임으로 동작하기에 너무 느린 속도
- Adaptive instance normalization (AdaIN) layer는 content feature를 style feature의 분포와 맞춰준다.
- x는 content feature, y는 style feature를 의미한다.
Introduction
- 주어진 이미지 x를 weight로 취급하여 gradient descent를 통해 반복적으로 업데이트하는 기존의 neural style transfer는 content, style 퀄리티가 뛰어나나 시간이 오래걸린다는 문제가 있으며
- feed-forward method는 하나의 스타일만 적용할 수 있다는 한계가 있다.
- flexibility-speed 딜레마를 해결하기 위한 AdaIN 방식을 제시하겠다.
- instance-normalization (IN)은 feed-forward 방식의 style transfer에서 뛰어난 효과를 보였다.
- AdaIN은 content input과 style input을 받아서 단순하게 content input의 분포 (mean, var)를 style input에 맞게 조정한다.
- content의 feature statistics을 style input의 통계량으로 변화시키면 content와 style이 결합됨을 실험을 통해 확인하였다.
- Decoder network은 AdaIN output을 다시 image space로 전환시켜 stylized image를 만들어낸다.
- 기존 Gatys의 Neural Style Transfer는 feature map의 second-order 통계량인 Gram matrix를 matching 시키는 것으로 style을 match 시켰다.
Background
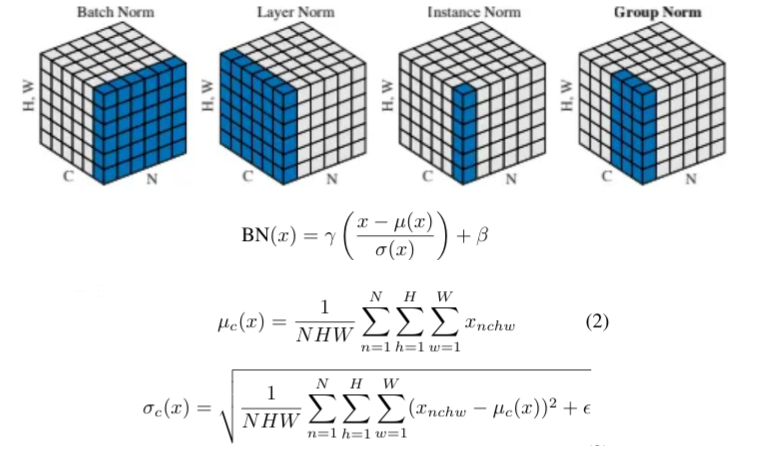
- Batch Normalization (이하 BN)
- BN layer는 본래 feed-forward 네트워크에서 feature map을 normalizing 시켜 빠른 학습을 가능케 하도록 사용되었다.
- 하지만 이미지 생성 모델에서 좋은 효과를 가지는 것이 실험을 통해 관찰되었다.
- 각 채널에서 전체 배치를 기준으로 normalize 한다.
- BN layer는 모집단의 통계량을 사용하여 계산하기 때문에 domain shift의 문제를 완화시키는 효과가 있다.
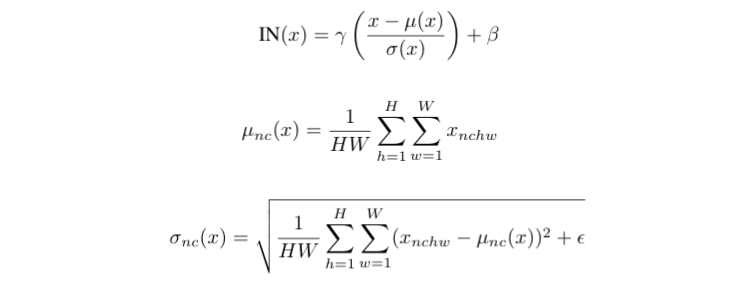
- Instance Normalization (이하 IN)
- D.UIyanov et al. - Improved texture networks: Maximizing quality and diversity in feed-forward stylization and texture synthesis. 에서 단순하게 BN을 Instance Normalization layer로 교체하였는데 성능의 향상이 있었다
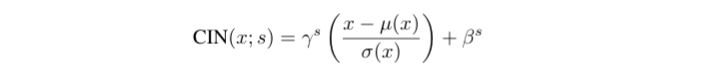
- Conditional Instance Normalization
- affine parameters gamma와 beta를 1개씩 학습하는 기존의 BN, IN과 달리 Conditional Instance Normalization (CIN) layer는 각 style s 쌍의 parameters를 학습한다.
- 학습 후, CIN layer의 affine parameters만 바꿔줘도 스타일이 완전히 다른 이미지를 생성해 낼 수 있었다.
- 학습을 위해 총 2 x F x S 개의 parameter가 추가로 필요하다 ( F는 feature maps, S는 styles )
- style 수에 따라 선형적으로 학습해야할 parameters가 늘어나고 다시 학습시켜야 한다는 한계가 있다.
Interpreting Instance Normalization
- Instance Normalization은 style transfer에서 큰 성공을 거두었다. 그러나 그 이유는 완벽하게 알기어렵다.
- Ulyanov et al.의 논문에서 저자는 IN의 content 이미지에서 contrast normalizing (정규화) 효과를 성공의 이유로 지목하였다.
- 하지만 pre-trained style transfer network을 사용하여 style normalized image를 input으로 사용할 때 style loss의 차이가 Contrast normalized image를 사용할 때 loss의 차이보다 작았다.
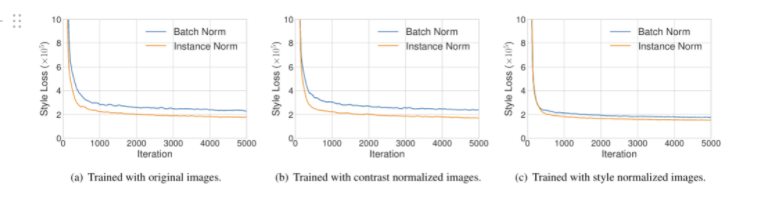
- IN의 효과는 feature 통계량 (mean&variance)을 normalizing하는 style normalization에 있다고 해석이 가능하다.
- BN은 직관적으로 single style을 중심으로 batch의 sample들을 정규화하는 것으로 각각 single sample은 여전히 조금씩 다른 style을 가진다 (style = mean , var )
- IN은 각 single sample을 target style에 맞추어 normalizing 하기 때문에 style transfer 측면에서 더 좋은 결과를 보인다.
Adaptive Instance Normalization (AdaIN)
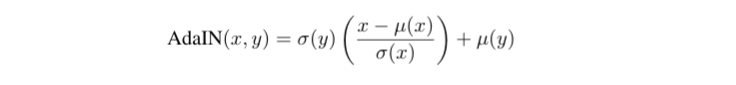
- IN이 해석대로 input을 affine parameter에 따라 정의된 single style에 맞추어 Normalization시킨다면 arbitrary affine parameters을 사용하여 주어진 style에 맞게 바로 normalization이 가능하지 않을까? 라는 생각에서 저자는 IN을 단순하게 확장한 adaptive instance normalization(AdaIN) 을 제시하였다.
- AdaIN은 content input x와 style input y를 input으로 받아 x의 channel-wise mean과 variance를 y의 그것들과 맞춰준다.
- 표준정규분포로 x의 분포를 바꿔주고 y의 mean과 variance를 각각 더해주고 곱해주어 분포의 scale, shift가 이루어진다.
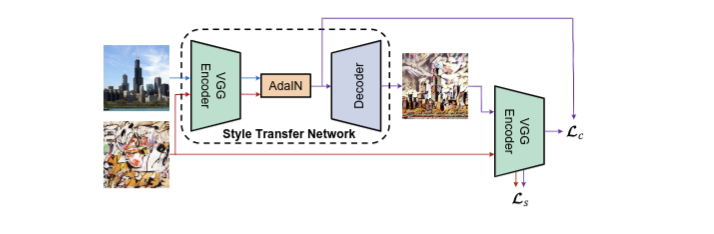
- VGG Encoder는 pretrained VGG-19의 초기 몇몇 layer를 사용하여 Content image와 Style image를 Encoding한다.
- AdaIN layer는 feature map에서 통계량를 변경하여 style transfer가 이루어지도록 한다.
- Decoder는 AdaIN output이 image space로 변환되도록 학습된다.
- 마지막에 VGG Encoder는 앞에 사용한 VGG Encoder와 동일하며 content loss인 Lc와 style loss인 Ls를 계산한다.
Experimental Setup
- c = content image, s = style image
- Encoder f : pre-trained VGG-19 ( ~relu4_1 까지)
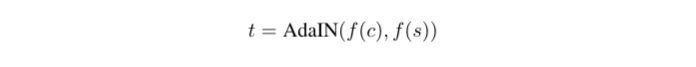
- t = target feature maps
- g = randomly initialized decoder
- t를 다시 image space로 매핑하도록 학습된다.
- T(c,s) = stylized image
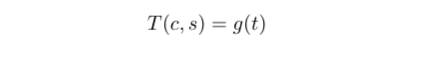
- Decoder는 거의 Encoder의 구조를 뒤집은 것과 동일하며 체커보드 패턴을 피하기 위해 모든 Pooling layer를 nearest-up sampling으로 대체하였다.
- Encoder와 Decoder에서 border artifact를 줄이기 위해 reflection padding을 사용하였다.

- [[ 1 2 3 ] [ 4 5 6 ]]에 reflection padding을 적용한 결과
- 2nd row를 보면 1 2 3 다음 열에서 3이 포함된 열을 기준으로 거울이 있는것 처럼 앞의 1과 2가 2, 1로 순서가 바뀌어 padding value가 채워진 것을 볼 수 있다.
- Constant padding의 단점인 padding value와 기존 feature map의 차이로 인한 edge가 나타나는 현상이 없다.
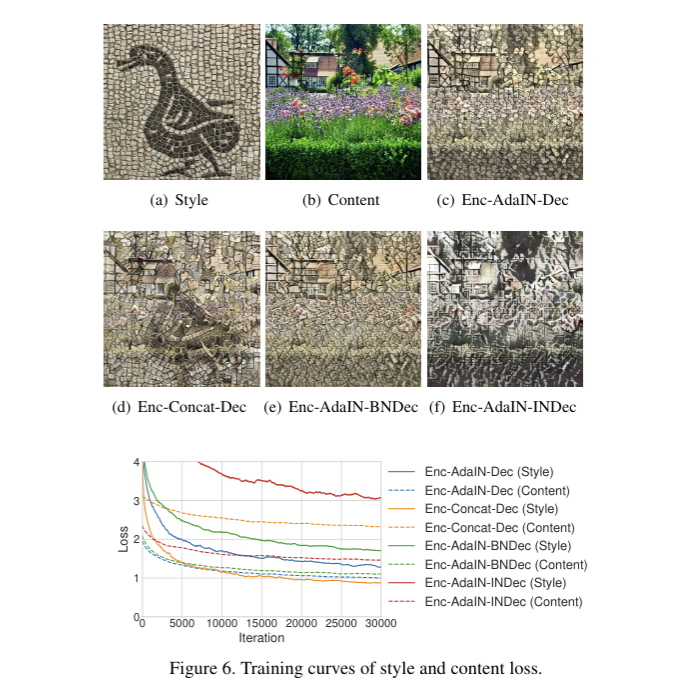
- IN은 각 샘플을 single style에 맞추며, BN은 single style centered하게 batch의 샘플을 normalize 하는데 두 방법 모두 현재 task인 multiple styled image를 generating하는 것과 다르기 때문에 Decoder에서 normalization layers는 하나도 사용하지 않았다.
- 실제로 아래 c, e, f를 보면 Decoder에 BN과 IN을 적용하였을 때 performance에 악영향을 끼치는 것을 볼 수 있다.
- 정량적으로 Training loss도 BN, IN이 Decoder에 포함되었을 때 더 높았다.
- Adam optimizer 사용
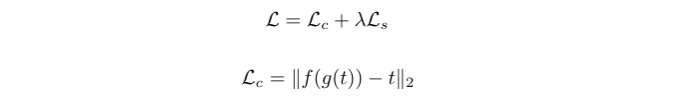
- Content loss는 AdaIN layer의 output인 target feature t와 / t를 Decoder에 input으로 주어 생성된 이미지 g(t), g(t)를 pre-trained VGG Encoder에 넣어 나온 output인 f(g(t)) 사이의 Euclidean distance로 설정하였다.
- AdaIN은 오직 mean과 standard-deviation 를 transfer하기 때문에 style loss는 mean과 std를 match 시키지 못하는 정도로 계산된다.

- pre-trained VGG-19의 relu1_1, relu2_1, relu3_1, relu4_1 layers의 output을 사용하며, generated image인 g(t)와 style image인 s의 위 layer들의 output의 mean의 Euclidean distance와 std의 Euclidean distance의 합을 Style loss로 정의한다.
- 초기의 layer의 filter는 edge나 단순한 color를 감지하므로 이를 style loss를 계산하기 위한 layer로 사용한다.
Results
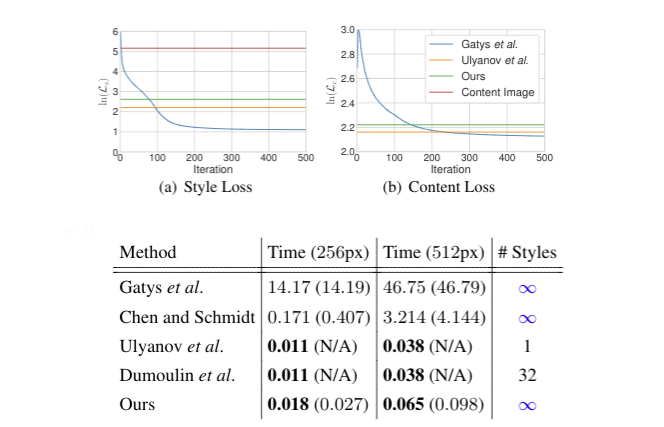

- 위와 같이 speed와 quality를 모두 고려하였을 때 좋은 성능을 보였다.
- degree of stylization, 다른 스타일에 대한 interpolation, content image의 색상을 유지하며 style transfering, 다른 부분에 다른 스타일 transfer가 가능하다.
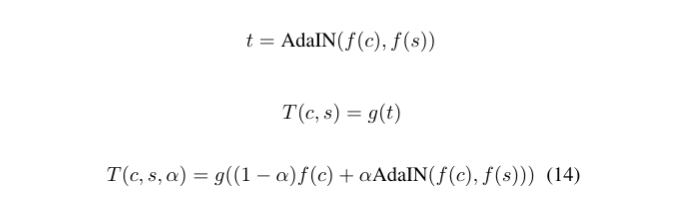
- 기존의 Stylized image인 T는 아래식에서 alpha가 1인 경우에 해당한다.
- alpha를 0에 가깝게 줄이면 content image가 Encoder를 통과한 feature map인 f(c)가 차지하는 비율이 증가하며 이는 style이 적용되지 않은 content image의 비율이 증가한 것으로 아래와 같은 결과가 나온다.
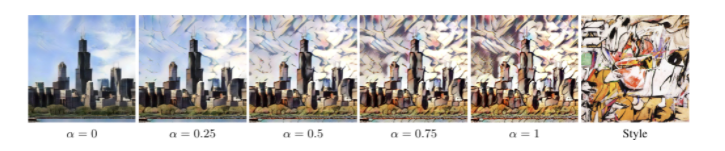
- Content image의 color를 보존하기 위해서는 style image의 color distribution을 content image의 color distribution과 맞춰준다. 그리고 그 style image를 사용하여 style transfer를 하면 color가 보존된 결과물이 나온다.

- K개의 style image에 자체 설정한 weight(w1 ~ wk)를 곱해 아래와 같은 식으로 T를 생성하면 style간 interpolation이 가능하다.

Discussion and Conclusion
- real-time style transfer를 가능케하는 adaptive instance normalization (AdaIN)의 제시
- residual architecture의 적용, 단순한 mean과 std을 맞춰주는 AdaIN 대신 correlation alignment, histogram matching을 통해 higher-order statistics을 넘겨주어 quality의 향상을 기대할 수 있다.
Reference
[1] Xun Huang et al. (2017). Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization https://arxiv.org/abs/1703.06868
'AI > Deep Learning' 카테고리의 다른 글
| CS231n - Lecture 1 ~ 4 (0) | 2021.08.21 |
|---|---|
| cGANs with Projection Discriminator (0) | 2021.08.07 |
| XLNet: Generalized Autoregressive Pretraining for Language Understanding (0) | 2021.05.08 |
| BERT (Bidirectional Encoder Representations from Transformers) (0) | 2021.04.18 |
| Multimodal Learning (0) | 2021.03.17 |
'AI/Deep Learning' Related Articles
more




Comments