
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 오블완
- cv
- 폰트생성
- NLP
- 모션매칭
- deep learning
- ddpm
- 생성모델
- GAN
- dl
- Font Generation
- RNN
- WinAPI
- Few-shot generation
- ue5.4
- Diffusion
- animation retargeting
- multimodal
- userwidget
- Generative Model
- BERT
- Unreal Engine
- motion matching
- 언리얼엔진
- 디퓨전모델
- WBP
- Stat110
- CNN
- 딥러닝
- UE5
- Today
- Total
Deeper Learning
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 본문
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Dlaiml 2024. 7. 26. 18:03Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou (2022.01) [Google Research, Brain Team]
Abstract
일련의 중간 추론 과정을 뜻하는 사고의 흐름, Chain-of-Thought(이하 COT)를 사용하여 Large Language Model(이하 LLM)의 복잡한 추론성능을 향상시키는 방법을 소개한다. 간단하게 몇 가지 예시를 주는 방식으로 만든 COT 프롬프팅으로도 LLM의 추론 능력이 향상되었다.
Arithmetic, Commonsence, Symbolic Reasoning 에서 더 좋은 퍼포먼스를 보였으며 PaLM 540B에 8개의 예시를 주는 COT를 사용하여 GSM8K 벤치마크에서 GTP-3을 넘는 SOTA를 달성하였다.

1. Introduction
언어모델의 크기를 증가시키는것은 샘플링 효율, 성능 향상에서 효과가 있다고 밝혀졌다. 하지만 단지 모델 사이즈를 키우는 것으로는 arithmetic, commonsence, symbolic reasoning 같이 어려운 태스크에서 충분한 성능 향상을 보여주지 못하였다.
논문에서 제시한 LLM의 추론능력의 한계를 간단하게 끌어올릴 수 있는 COT 방법론은 두 가지 아이디어에서 영감을 받았다.
1. arithmetic의 경우 정답에 접근할 수 있도록 중간 근거를 사용하는 방식으로 학습시키거나 fine-tuning 시키는 방식으로 성능을 향상시킬 수 있다는 것이 이전 연구들에서 밝혀졌다.
2. LLM은 프롬프트를 통한 in-context few-shot learning에 뛰어나 fine-tuning 없이도 태스크를 설명하는 input-output 예시를 제공함으로써 성능을 향상시킬 수 있다.
1번 방식의 경우 추론에 도움되는 중간 근거를 포함한 데이터셋을 만들어야 되는데 성능을 끌어올릴 수 있을 정도로 대량의 데이터를 만들기 위해 드는 비용이 매우 크다는 문제가 있으며 2번 방식의 경우 단순하지 않은 추론 문제에서 효과를 보이지 못하였다는 문제가 있다.
저자는 이 두 방식을 조합하여 <input, chain of thought, output>으로 구성된 예시들로 프롬프트를 구성하는 방식을 제안하고 있다.
COT 프로프팅을 사용한 모델은 앞서 설명한 3개의 Task에서 일반 프롬프팅 대비 성능이 크게 향상되었으며 심지어 PaLM 560B 모델에 COT 프롬프팅을 사용한 결과, 기존 SOTA를 크게 뛰어넘는 성능을 기록하였다.
2. Chain-of-Thought Prompting
복잡한 여러 단계로 구성된 서술형 수학 문제를 푼다고 생각해 보자.
7이라는 정답을 내기전에 분명 "Jane이 그녀의 엄마에게 2송이의 꽃을 주어서 그녀의 엄마는 10개의 꽃을 가지고 있고, 그녀의 엄마가 남편에게 3개의 꽃을 주었기 때문에 정답은 7이다" 와 같이 중간 단계들을 생각하였을 것이다.
LLM에게도 비슷하게 사고의 흐름(COT)를 생성할 수 있는 능력을 부여하는 것이 이 논문의 목표이다. 저자는 few-shot prompting으로 LLM이 COT를 생성할 수 있다는 것을 소개하려 한다.
LLM의 추론능력을 향상시키는 COT 프롬프팅은 여러 장점이 있다.
1. COT는 모델이 여러 단계의 문제를 중간 단계로 분리하도록 하기 때문에 더 많은 연산이 필요한 문제에 대해 추가 연산이 수행될 수 있도록 한다.
2. COT는 모델에게 왜 추론 과정이 잘못되었는지 디버깅할 수 있는 기회를 주며 답까지 도달하는 과정 또한 함께 제시하기 때문에 모델에게 문제를 분석할 수 있는 방법을 알려주는 것과 같다.
3. COT 추론방식은 사람이 자연어로 풀 수 있는 모든 문제에 적용이 가능하다.
4. 기존 거대 언어모델에 COT 예시들을 few-shot prompting 방식으로 쉽게 적용할 수 있다.
3. Result
Arithmetic(녹색), commensence(주황색), symbolic reasoning(하늘색)에 COT 프롬프팅을 주는 방식은 아래와 같다.
<input, COT, output>으로 구성되어 있다.

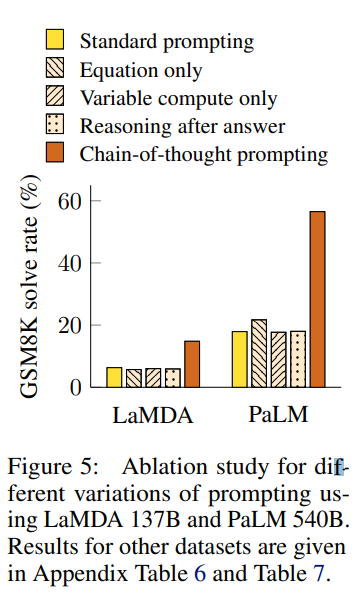
arithmetic 태스크에서는 여러 벤치마크에서 모두 Standard Promping보다 좋은 성능을 기록하였으며 답변 이후 Reasoning, equation only 등 여러 세팅의 Ablation study로 COT 프롬프트의 효과를 입증하였다.
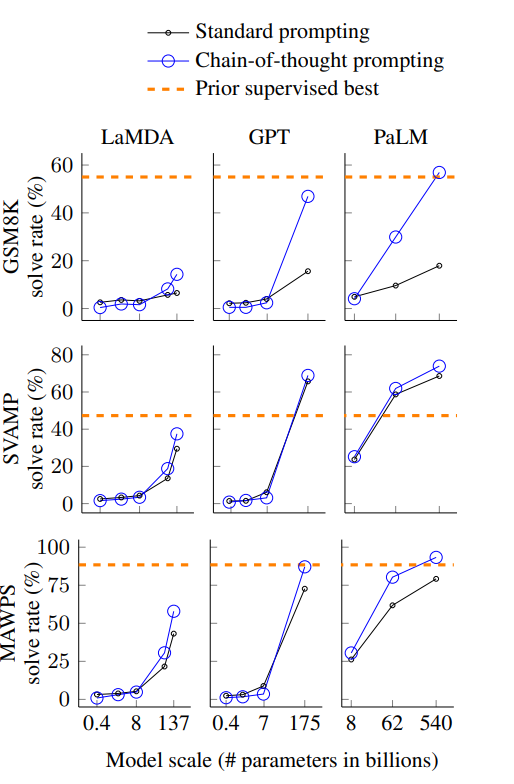
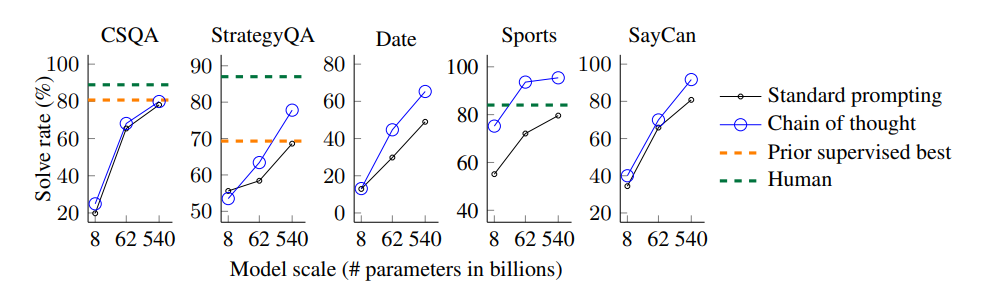
Commensense Reasoning, Symbolic Reasoning에서도 일반 프롬프팅을 뛰어넘는 성능을 보여주었다.
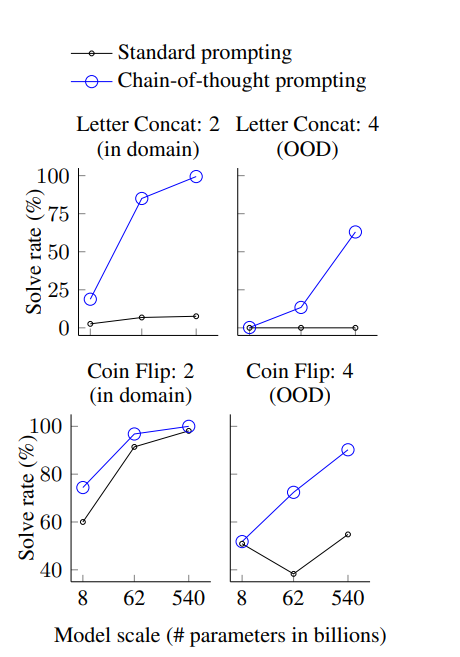
다른 사람(Annotator)이 작성한 COT로 LLM의 성능을 비교하는 방식으로 Robustness를 측정하였는데 누가 작성하여도 대조군을 뛰어넘는 성능을 보여 Robustness 또한 실험하였다.
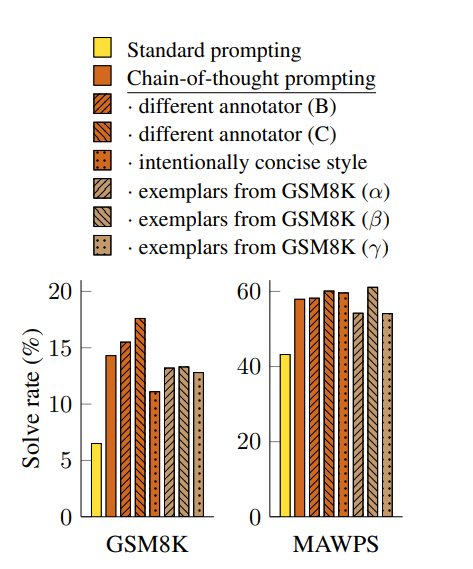
Conclusions
LLM의 추론능력을 쉽게 끌어올릴 수 있는 COT를 제시하였다. COT 프롬프팅은 arithmetic, symbolic, commonsence 추론에서 LLM의 Scaling curve(scale에 따른 성능 그래프)을 큰 폭으로 향상시키는 것을 확인하였다. 언어모델이 다룰 수 있는 추론 문제의 영역을 넓히는 것이 이후 언어 기반의 추론 연구에 영감을 주기를 바란다.
후기 & 정리
예전에 읽었던 논문인데 최근 언어모델을 사용한 게임 기능을 개발하다가 다시 읽고 정리한 논문이다. Few-shot 프롬프팅의 성능 향상폭에 대해 소개한 논문도 놀라웠는데 헤당 논문 또한 같은 이유로 놀라웠다.
LLM에서 데이터 수집, 학습 Cost가 이미 일반인과 보통 기업은 손댈 수 없을 정도로 커진 현재 Fine-tuning 없이 프롬프팅으로 가장 어려운 태스크로 꼽히는 추론에서의 성능을 크게 끌어올렸다는 것 자체가 유의미한 논문이라고 생각한다.
처음 논문을 읽고 나서 항상 언어모델을 사용할 때 COT 형식으로 프롬프팅을 하는 것이 습관이 되었다
Reference
[0] Jason Wei et al., (2022). "Chain-of-Thought Prompting Elicits Reasoning in Large Language Models" https://arxiv.org/abs/2201.11903
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
We explore how generating a chain of thought -- a series of intermediate reasoning steps -- significantly improves the ability of large language models to perform complex reasoning. In particular, we show how such reasoning abilities emerge naturally in su
arxiv.org
'AI > Deep Learning' 카테고리의 다른 글
| LDM: High-Resolution Image Synthesis with Latent Diffusion Models (0) | 2023.06.02 |
|---|---|
| Score-Based Generative Modeling through Stochastic Differential Equations (0) | 2023.05.27 |
| Score-based Generative Models과 Diffusion Probabilistic Models과의 관계 (0) | 2023.05.16 |
| Diffusion Models Beat GANs on Image Synthesis (0) | 2023.05.05 |
| Improved-DDPM: Improved Denoising Diffusion Probabilistic Models (0) | 2023.04.19 |



