
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- BERT
- 딥러닝
- cv
- Few-shot generation
- Unreal Engine
- Diffusion
- RNN
- 모션매칭
- ddpm
- 생성모델
- 언리얼엔진
- UE5
- Font Generation
- userwidget
- deep learning
- WinAPI
- GAN
- 폰트생성
- 오블완
- Stat110
- WBP
- animation retargeting
- dl
- multimodal
- motion matching
- CNN
- ue5.4
- Generative Model
- 디퓨전모델
- Today
- Total
Deeper Learning
LDM: High-Resolution Image Synthesis with Latent Diffusion Models 본문
LDM: High-Resolution Image Synthesis with Latent Diffusion Models
Dlaiml 2023. 6. 2. 10:53Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, (2021.12) [Ludwig Maximilian University of Munich & IWR, Heidelberg University, Runway ML]
(이전 Diffusion Models paper review(DDPM, DDIM, Improved-DDPM 등)에서 다루었던 중복된 내용은 자세하게 적지 않았음)
Abstract
- Diffusion model은 이미지 생성에서 좋은 성능을 보였고 재학습 없이 guidance를 주어 이미지 생성 프로세스를 조정할 수 있는 능력 또한 갖추고 있다
- 하지만 pixel level에서의 연산이 이루어지기 때문에 수백일의 GPU days가 필요한 문제가 있다
- 한정된 컴퓨팅 자원하에 퀄리티와 flexibility를 유지하기 위해 강력한 autoencoder를 사용하여 latent space에서 Diffusion model을 적용하는 방식을 제안한다
- Cross-attention layer를 모델 아키텍처에 사용하여 bbox, text와 같은 다양한 모달리티의 condition input을 사용가능하도록 하였다
- 논문에서 제시하는 Latent Diffusion Models(이하 LDM)은 pixel-based Diffusion model보다 적은 연산량으로 inpainting, class-conditional 이미지 생성에서 SOTA를 달성하였고 text-to-image 생성, unconditional 이미지 생성, SR에서도 좋은 성능을 보였다
1. Introduction
- 강력한 Diffusion Model(이하 DM)을 학습시키기 위해서는 수백일의 학습이 필요하고 high-resolution에서 진행되는 inference 또한 50k의 샘플을 생성하는데 A100 GPU에서 5일이 걸릴 정도로 오래 걸린다
- DM을 학습시키는 것도 수많은 자원을 필요로 하기 때문에 누구나 할 수 없으며 학습된 모델의 활용도 많은 memory와 시간을 요구한다
- 저자는 DM 학습을 perceptual compression, semantic compression 두 단계로 나누어 분석하였다.
- perceptual compression: high-frequency detail을 지우며 약간의 semantic variation을 학습
- semantic compression: 생성모델이 실제로 semantic, conceptual한 데이터의 composition을 학습하는 단계

- 위 Figure를 보면 이미지의 많은 bits가 imperceptible detail에 대응되는 것을 볼 수 있는데 DM은 semantic한 의미가 없는 정보를 suppress하는데 전체 pixel에 대한 loss, gradient를 사용하기 때문에 불필요하게 많은 연산이 이루어진다 (큰 의미가 없는 인지하기 힘든 디테일을 지우는 Perceptual Compression을 DM이 아닌 Autoencoder를 사용하여 해결)
- 따라서 perceptually equivalent하며 연산량을 줄일 수 있는 space인 latent space에서 DM을 적용하는 LDM을 제시
- LDM은 두 단계의 학습으로 구성되어 있음
- data space와 perceptually equivalent한 lower-dimensional representation space를 만드는 autoencoder를 학습하는 단계
- 학습된 latent space에서 DM을 학습하는 단계
- LDM의 장점은 autoencoder를 한 번 학습하면 다양한 task에서 이미 학습한 autoencoder를 사용할 수 있다는 것이다
- DM의 UNet backbone에 Transformer를 사용하여 token-based conditioning 방식도 연구하였음
- contributions
- compression level에서 연산이 이루어지기 때문에 transformer-based 모델들보다 scale up이 쉬움
- 여러 task와 dataset에서 적은 컴퓨팅 자원을 사용하고도 좋은 성능을 보임
- encoder, decoder, score-based prior를 동시에 학습하는 이전 연구보다 더 안정적이고 latent space에 대한 제약이 적음
- 1024 resolution에서도 Super resolution, inpainting, semantic synthesis 가능
- cross-attention을 사용한 conditioning으로 class-conditional, text-to-image, layout-to-image 등 multi-modal 학습 가능
- pretrained LDM과 autoencoder를 공개 https://github.com/CompVis/latent-diffusion
GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
github.com
2. Method
- Autoencoder를 사용하여 이미지 space와 perceptually equivalent 하지만 연산량을 줄일 수 있는 latent space를 학습
- Autoencoder를 사용함으로써 저차원에서 DM을 적용하기 때문에 연산량에서 이점이 있으며 UNet의 inductive bias인 spatial structure 데이터에서의 강점을 가지며, general-purpose compression 모델을 얻게 됨
2.1. Perceptual Image Compression
- perceptual loss, patch-based adversarial objective를 pixel-space loss와 함께 사용하여 Autoencoder를 학습하여 compression 이미지가 흐릿하지 않으며 local realism을 살릴 수 있었음
- high-variance latent space를 피하기 위해 2가지 regularization 방식을 제시
- KL-reg: 학습된 latent에 KL-penalty를 주는 VAE와 비슷한 방식
- VQ-reg: decoder에 vector quantization layer를 사용하여 vector quantization layer가 decoder 내부에 위치하는 VQGAN의 형태
[공개 코드로 테스트해본 KL-reg AE와 VAE의 차이]
github에 공개된 pre-trained KL-reg Autoencoder로 Reconstruction을 해보았는데 전체적인 구조를 잘 유지하는 것을 볼 수 있다.
VAE와 다르게 논문에서 나온 대로 “Slightly” regularization이 들어가 VAE처럼 가우시안 분포에서 샘플링 →이미지 생성은 잘 되지 않았음.

2.2. Latent Diffusion Models
- pixel-level DM과 다르게 latent space에서 Diffusion process를 적용하는데 high-frequency, imperceptible detail이 추상화되었기 때문에 Diffusion process가 더 중요한 semantic bits에 집중할 수 있으며 저차원에서 Diffusion을 하기 때문에 더 효율적이 연산이 가능함
- 이전 연구인 autoregressive attention-based transformer와 다르게 image-specific inductive bias의 장점을 가져갈 수 있음
2.3. Conditioning Mechanism
- DM에서 class-label, blurred input을 제외한 다른 conditioning 방식은 연구가 더 필요한 영역
- cross-attention을 UNet backbone에 사용하여 다양한 modalities의 conditioning이 가능하도록 하였음
- UNet의 intermediate representation을 flatten하고 이를 Query값으로 domain specific encoder를 사용하여 만든 conditioning 정보를 Key, Value로 사용하여 cross-attention 적용
3. Experiments
(f는 downsampling factor로 원본 이미지가 H,W이고 Autoencoder를 통과한 latent가 h,w이면 f = H/h=W/w, LDM-f는 dowmsampling factor f 세팅의 LDM)
3.1. On Perceptual Compression Tradeoffs
downsampling factor가 작은 LDM-1,2은 느린 학습을 보였으며 f가 너무 크면 학습이 진행되어도 fidelity가 개선되지 않았는데 저자는 perceptual compression을 Diffusion에게 너무 많이 맡기게 되어 학습이 느렸으며, compression이 너무 많이 되어 information loss가 커서 Diffusion process에서 문제가 발생하였다고 분석하였다.
LDM-4~16이 적당한 밸런스를 보였다.
3.2. Image Generation with Latent Diffusion
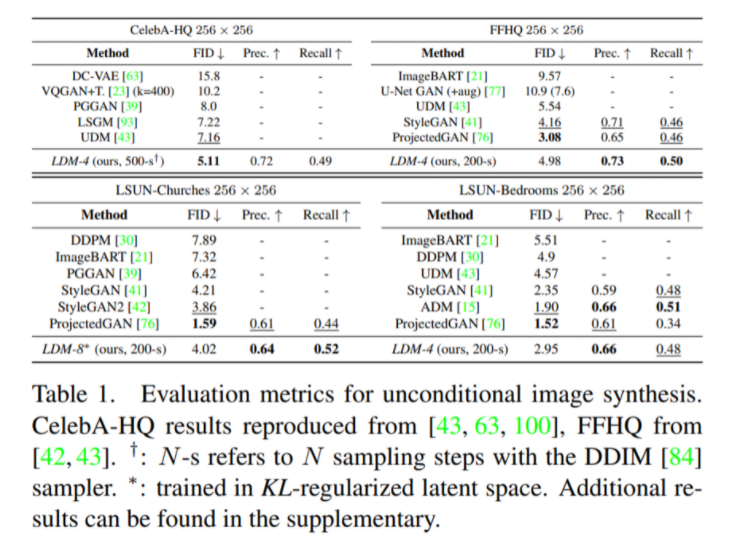
3.3. Conditional Latent Diffusion
LAION-400M 데이터셋과 BERT-tokenizer를 사용한 text-to-image 생성에서 좋은 성능을 보였으며 autoregressive method보다 적은 parameter를 사용하며 비슷한 성능을 기록
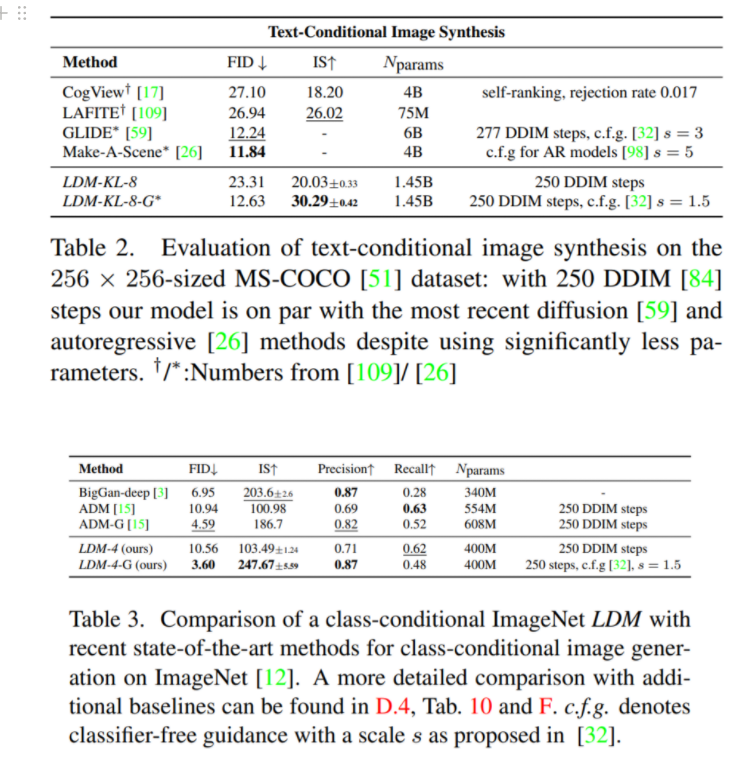
Inpainting, Super resolution task에서도 좋은 결과를 보임

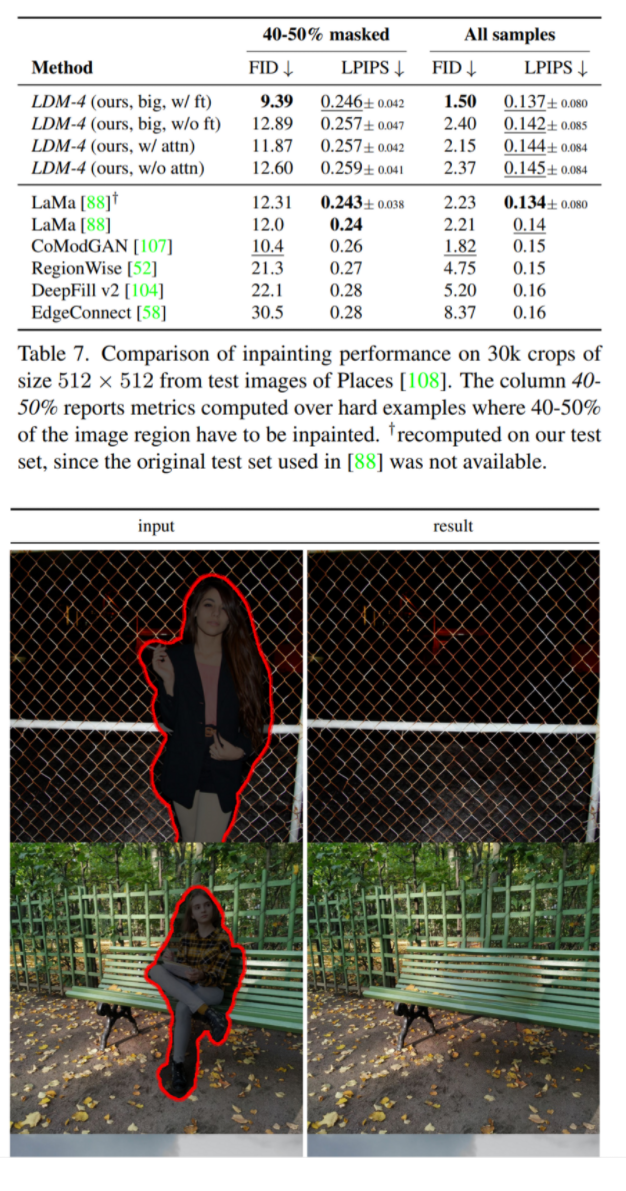
4. Limitations & Societal Impact
- LDM도 여전히 GAN보다 느린 샘플링이 문제
- autoencoder의 reconstruction 성능이 fine-grained accuracy가 필요한 이미지 생성에서 bottleneck이 될 수 있음 (SR의 경우 bottleneck을 확인)
- 다양한 창작물을 만들 수 있으나 잘못된 정보를 퍼뜨리는데 사용될 수 있음
- 데이터에 존재하는 bias를 답습하는 문제가 존재
5. Conclusion
- autoencoder를 사용하여 얻은 latent space에서 diffusion process를 진행하는 DM의 퀄리티를 유지하면서도 효율적인 LDM을 제시
- cross-attention conditioning으로 task-specific 아키텍처 없이 다양한 conditional image 생성 태스크에서 SOTA에 견줄만한 결과를 보임
후기 & 정리
- autoencoder를 사용하여 latent space에서 diffusion process를 진행하여 pixel-level diffusion의 퀄리티를 유지한 채로 연산량, 메모리 효율을 개선한 LDM을 제시
- cross-attention conditioning으로 여러 모달리티를 다룰 수 있도록 하였고 domain-specific 아키텍처를 사용하지 않고 여러 image 생성 task에서 좋은 성능을 기록
- 딥러닝 이미지 생성으로 매우 유명한 Stable Diffusion의 모델인 Latent Diffusion Model
- perceptual compression, semantic compression으로 DM의 학습 과정을 나누고 의미가 적은 pixel의 학습에 연산이 사용되는 것을 줄이고자 Autoencoder를 사용하여 latent space에서 diffusion process
- autoencoder bottleneck의 한계로 나중에는 연산 효율을 증가시킨 pixel-level diffusion이나 autoencoder 부분을 개선한 연구에 의해 대체될 수 있는 방법론이라고 생각함
- Appendix에 중요한 실험들이 많아 시간 되면 나중에 이어서 끝까지 읽어볼 예정
Reference
[0] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer, (2021), "High-Resolution Image Synthesis with Latent Diffusion Models", https://arxiv.org/abs/2112.10752
High-Resolution Image Synthesis with Latent Diffusion Models
By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond. Additionally, their formulation allows for a guiding mechanism t
arxiv.org



