
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 |
- WBP
- animation retargeting
- Stat110
- Few-shot generation
- motion matching
- ddpm
- Generative Model
- 오블완
- multimodal
- NLP
- 폰트생성
- 디퓨전모델
- 모션매칭
- Unreal Engine
- deep learning
- userwidget
- dl
- CNN
- 언리얼엔진
- cv
- ue5.4
- 딥러닝
- 생성모델
- GAN
- Diffusion
- Font Generation
- BERT
- UE5
- WinAPI
- RNN
- Today
- Total
Deeper Learning
Fréchet inception distance (FID) 본문
Fréchet inception distance
GAN의 모델의 학습이 어려운 이유 중 하나는 완벽한 평가지표가 없기 때문이다.
Generator와 Discriminator의 Loss는 실질적으로 유의미한 정보를 담고 있지 않기 때문이다.
Fréchet inception distance은 GAN으로 생성된 output과 real data를 비교할 수 있는 지표로 사용된다.
생성된 이미지들과 실제 이미지의 분포를 비교하여 이를 평가지표로 선정한다.
Intuitive definition
Imagine a person traversing a finite curved path while walking their dog on a leash, with the dog traversing a separate finite curved path. Each can vary their speed to keep slack in the leash, but neither can move backwards. The Fréchet distance between the two curves is the length of the shortest leash sufficient for both to traverse their separate paths from start to finish. Note that the definition is symmetric with respect to the two curves—the Frechet distance would be the same if the dog were walking its owner.
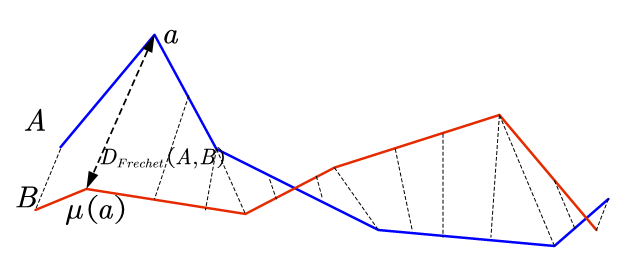
개와 함께 산책하는 남자가 있다고 가정하면 산책을 하면서 남자와 개 사이의 거리는 위와 같이 변하게 된다. 개와 남자의 산책경로를 기록하고 산책경로의 수정은 불가능하다. 이때 개 목줄의 최소 길이가 Fréchet distance가 된다.
Fréchet inception distance Graph and Formula

단변량의 두 분포를 비교할 때 위 수식으로 Fréchet Distance를 계산할 수 있다.

위는 서로 독립인 두 feature의 분포를 나타낸 그래프다.
단변량과 다르게 표준편차가 아닌 feature들 사이의 Covariance값이 Fréchet Distance 계산을 위해 필요하다.

이는 Covariance가 다를 경우 위처럼 분포가 달라지기 때문이다. (음의 상관관계)

Trace는 대각합으로 대각원소(diagonal elements)의 합을 말한다.
Example, Shortcomings
FID (Fréchet inception distance)는 pretrained Inception Network의 마지막(또는 중간) Convolution layer를 통과한 activations을 비교하여 Fréchet Distance를 구한 값을 의미한다.
예를 들어 500x229x229x3 (500개의 229x229 size의 RGB 이미지)와 생성된 같은 형태의 데이터가 Inception을 통해 Embedding되어 500 x 2048로 차원이 축소된다. 이 두 matrix 사이의 FID를 구하여 이를 GAN의 결과를 평가하는 평가지표로 사용한다.
한계는 Imagenet에서 pre-trained된 Inception v3를 이용하기 때문에 중간 layer가 잡아내지 못하는 feature가 두드러지는 데이터에서는 좋은 결과를 말해주지 못한다.
속도가 느리고 size가 작은 데이터에서 두 분포의 유사도 측정 성능이 좋지 않으며, 오직 Mean, Covariance만을 고려하는 것도 단점 중 하나다.
FID는 널리 사용되는 GAN을 평가하는 metrics중 하나로 단순하게 Generator와 Discriminator의 mean loss를 지표로 사용하는 것보다 유용하다.
'AI > Deep Learning' 카테고리의 다른 글
| Gated Recurrent Units (GRU) (0) | 2020.12.03 |
|---|---|
| Language Model (0) | 2020.12.01 |
| Recurrent Neural Network (0) | 2020.12.01 |
| Neural Style Transfer (0) | 2020.11.28 |
| One Shot Learning (0) | 2020.11.27 |



