

| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 언어모델
- 폰트생성
- 딥러닝
- BERT
- WinAPI
- inductive bias
- multimodal
- CNN
- cv
- Stat110
- 디퓨전모델
- 모션매칭
- motion matching
- ue5.4
- Few-shot generation
- WBP
- userwidget
- RNN
- 언리얼엔진
- deep learning
- Generative Model
- 생성모델
- animation retargeting
- Font Generation
- NLP
- GAN
- ddpm
- Diffusion
- UE5
- dl
- Today
- Total
Deeper Learning
Recurrent Neural Network 본문
Vocabulary
Recurrent Neural Network(이하 RNN)은 주로 비정형 문자 데이터를 다루는데 사용된다.
딥러닝 신경망 알고리즘의 적용을 위해 비정형 데이터는 수치형 데이터로 전환되어야 한다.
Lorem ipsum dolor sit amet.
consectetur adipiscing elit.
위와 같은 문장 2개가 데이터로 주어졌을 때 이를 수치형 데이터로 변환하기 위해 간단한 Vocab을 만들면 다음과 같다.
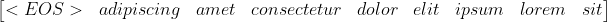
첫 번째 문장에 Vocabulary를 사용하여 One-hot encoding을 적용한다.

각 행은 단어를 나타내고 각 열은 vocab의 단어의 출현 여부를 1 또는 0으로 나타낸다.
이와 같이 수치로 변환한 텍스트 데이터를 input으로 모델을 학습시킬 수 있다.
Sequence Models
위에서 만든 One-hot encoding된 matrix들을 input으로 모델을 학습시킨다고 하자.
먼저 Dense Neural Network(DNN)은 input의 size가 일정하여야 한다.
하지만 위의 경우 두 번째 문장을 One-hot encoding하면 4x9 matrix가 되어 문제가 생긴다.
이는 zero padding으로 해결이 가능하지만 Network의 성능은 여전히 저조하다.
DNN의 저조한 성능은 텍스트 데이터의 상호 연관성에 기인한다.
다음 단어를 예측하는 모델을 학습한다고 하면 DNN은 Sequence내 모든 element를 고려하여 예측을 하는데 이는 매우 비슷한 Sequence가 자주 주어지는 특정 데이터에서만 좋은 성능을 보인다. 실제 데이터에서 이러한 상황은 한정적이다.
문장은 문맥을 가지고 있다. 다음에 나올 단어는 앞에 나온 단어의 영향을 받는다. "나는 10분 전 배가 고파서 사과를 먹었다." - '먹었다'라는 단어는 앞의 단어를 통해 유추가 쉽게 가능하다.
따라서 새로운 Neural Netowrk의 형태가 필요하다.
RNN Architecture
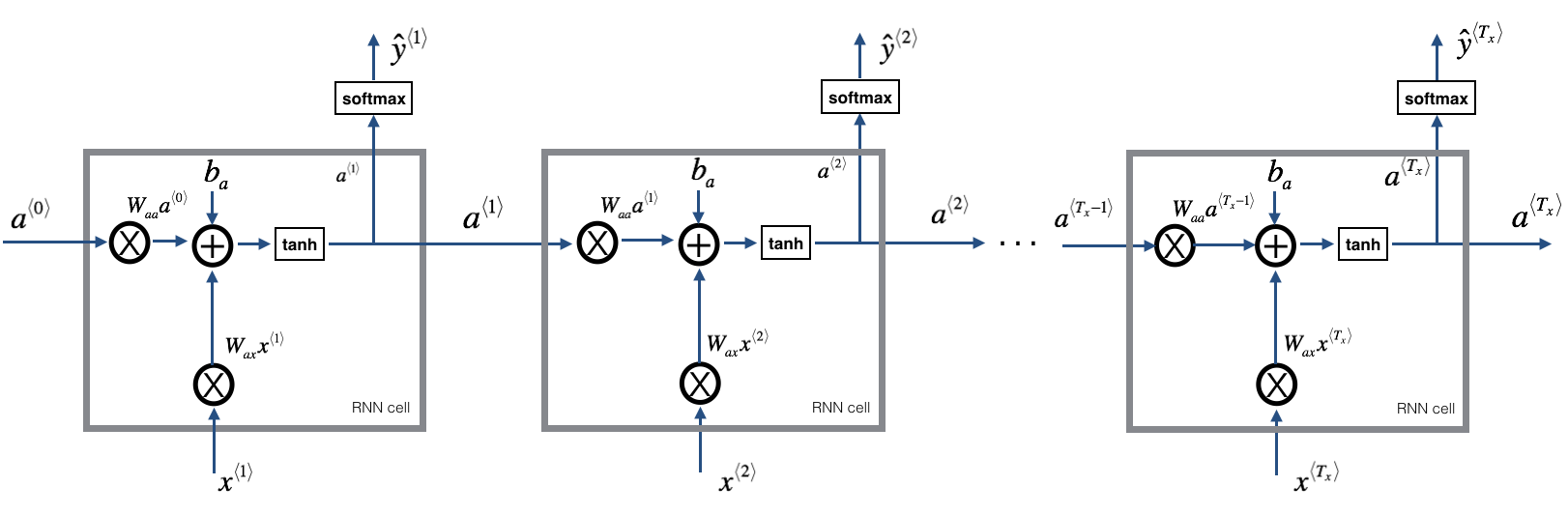
위 그림은 시간에 따른 RNN의 Forward propagation과정을 펼친 모형이다.$x^{<n>}$는 Sequence의 n 번째 element(단어 or 문자)를 말한다. a는 Layer를 통과한 activation으로 다음 input element을 계산할 때 사용된다.

input과 output에 따라 다른 3가지 종류의 Weight matrix가 존재한다. (input, output) = (a, x), (last a, a), (a, y)
Loss Function

Loss는 y값의 마지막 activation function이 softmax이므로 Cross-entropy loss를 사용한다.

Back propagation 과정에서 기존 DNN과 다른점은 $a^{t+1}$에서 $a^{t}$방향으로 추가로 역전파가 이루어지는것이다.
'AI > Deep Learning' 카테고리의 다른 글
| Gated Recurrent Units (GRU) (0) | 2020.12.03 |
|---|---|
| Language Model (0) | 2020.12.01 |
| Fréchet inception distance (FID) (0) | 2020.11.30 |
| Neural Style Transfer (0) | 2020.11.28 |
| One Shot Learning (0) | 2020.11.27 |



