
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- Generative Model
- animation retargeting
- 딥러닝
- 모션매칭
- WBP
- 언리얼엔진
- Diffusion
- 디퓨전모델
- dl
- motion matching
- Stat110
- UE5
- 오블완
- WinAPI
- Few-shot generation
- Font Generation
- multimodal
- deep learning
- RNN
- ddpm
- 생성모델
- 폰트생성
- CNN
- userwidget
- cv
- BERT
- GAN
- NLP
- Unreal Engine
- ue5.4
- Today
- Total
Deeper Learning
Generative modeling 본문
생성 모델링
생성모델은 deterministic이 아닌 probabilistic 모델로 학습 데이터를 나타내는 분포를 최대한 학습하여 그 분포내에서 샘플링하여 output으로 하는 모델.
판별모델링은 x가 주어졌을 때 레이블 y의 확률인 P(y|x)를 추정
생성모델링은 x의 관측확률 p(x)를 추정한다. label이 있다면 p(x|y)를 추정.
생성모델에 대한 연구는 앞으로 인공지능을 이해하는데 매우 큰 도움이 될 것.
supervised 판별 모델은 데이터가 생성된 방식에 집중하고 있지 않다.
강화학습 분야에서 강점을 가진다.
사람은 코끼리 이미지를 상상할 수 있음. 지금까지 봐온 코끼리를 정확히 그대로 상상하는것이 아닌 코끼리의 특성을 토대로 분포내에서 상상.
생성 모델이 만족해야하는 조건 (절대적이진 않으나 통상적으로)
- 샘플 데이터셋 X
- 샘플이 모수를 알 수 없는 분포 p_data로부터 생성되었다고 가정.
- 생성모델은 p_data를 흉내내려고 학습. 목표를 완전하게 달성하였다면 생성모델이 자신이 학습한 분포에서 샘플링한 데이터는 p_data에서 샘플링한 그것과 매우 유사하다.
- p_data에서 뽑은 것과 같은 샘플을 생성해야함
- X에 있는 샘플뿐만 아니라 다른 샘플을 생성할 수 있어야됨. (단순 복사가 아니어야함)
표본공간: 샘플 x가 가질 수 있는 모든 값의 집합
확률밀도함수 p(x): 표본공간의 포인트 x를 0~1의 숫자에 매핑하는 함수. 표본 공간의 모든 포인트에 대한 확률밀도함수의 합은 1이되어야함.
데이터에서 확률밀도함수를 정확히 구하는 것이 그 분포를 정확히 아는것과 동일.
현실세계의 확률밀도함수 p_data를 추정하는것이 목표
p_data를 추정하기위해 사용할 수 있는 확률 밀도 함수 p_model은 무수히 많다. 적합한 p_model을 찾기위해 모수모델(parametric model)기법을 사용한다.
모수모델
p_theta(x)는 한정된 개수의 파라미터 theta를 사용하여 묘사하는 확률 밀도함수의 한 종류
ex) 세계지도를 생성하는 모델, 주어지는 데이터는 대륙의 특정지역의 좌표.
세계지도에서 바다가 아닌 대륙에서 샘플링한 데이터가 X 일 때 모수모델을 직사각형 모양으로 디자인 한다고 하면 상자의 왼쪽 위, 오른쪽 아래 좌표 4개가 각각 파라미터가 되고 모수모델의 확률 밀도 함수는 4개의 숫자로 표현이 가능하다.
Likelihood
L(a|x)는 샘플포인트 x가 주어졌을 때 파라미터 a의 알맞은 정도를 측정
L(a|x) = p_a(x)
샘플포인트 x가 주어졌을때 파라미터 a의 likelihood는 파라미터 set a를 사용하여 정의된 확률밀도함수에서 포인트 x의 값으로 정의한다.
독립된 샘플로 이루어진 데이터셋 X = (x1,x2,x3)가 있다면
L(a|X) = p_a(x1) * p_a(x2) * p_a(x3)
곱셈식의 scale 문제로 log-likelihood를 사용하는 경우가 많다.
직관적으로 파라미터 집합 theta의 가능도를 theta로 정의된 모델 하에서 데이터가 발견된 확률가 동일하다고 이해할 수 있다.
ex) 세계지도 예시에서 파라미터 4개 ( box의 좌표 )로 정의된 상자가 북미의 좌표만 담고있다면 이 모수모델의 가능도는 0이 될 수 있다. 아시아 지역의 데이터셋을 발견할 확률이 0이기 때문.
모수모델은 데이터셋 X가 관측될 가능도를 최대로 하는 파라미터 집합 theta의 최적값을 찾는 것에 가장 관심이있다.
이런 기법을 최대 가능도 추정이라고 부른다. (maximum likelihood estimation)

theta_hat = maximum likelihood estimate
정형 데이터 (discrete)에서 모수모델: 다항분포
얼굴 데이터셋의 구성이 다음과 같다고 한다.
- 안경 3가지
- 옷색 8가지
- 머리색 6가지
- 헤어스타일 7가지
- 옷 4가지
총 38674 = 4032개의 조합이 가능하다.
이 표본공간에는 총 4032개의 데이터 포인트가 있다고 할 수 있다.
50개의 샘플로 이루어져있는 데이터셋 X를 가지고 있다고하면 먼저 문제는 p_data를 모른다는 것이다. 현재 소유한 데이터셋인 X은 p_data에서 샘플링한 값이기 때문.
단순하게 주어진 조합마다 확률을 부여할 수 있다. 이 경우 모수모델의 파라미터 개수는 총 4031개가 된다. 4032개가 아닌 이유는 전체 합이 1이 되기 위해 자동으로 결정되는 파라미터가 있기 때문이다.
이와 같은 모수모델을 다항 분포라고 하며 각 파라미터의 최대 가능도 추정은

긴 머리, 검은 옷.... , 조합이 총 2번 등장하였으면 이 조합에 대한 theta_1 = 2 / 50 = 0.04
한번도 등장하지 않은 조합은 0의 값을 가지게 된다.
이를 토대로 만든 모수모델은 기존 데이터셋에서 그대로 샘플링하기 때문에 생성 모델이라고 할 수 없다.
원본 데이터셋 X에 없는 조합을 생성하기 위해서는 가상의 등장횟수 1을 모든 조합에 더해준다.
이를 Addtive Smoothing(가법 평활화)라고 한다.

현재 모델은 모든 표본공간에 동일하게 추가 확률을 부여하였다.
하지만 이상적인 생성모델은 표본 공간에서 가능성 있다고 판단하는 영역에서 가중치를 높여야 한다.
데이터에서 학습한 추정 분포를 바탕으로 가중치를 정해야 한다.
위 프로세스를 수행하기 위해서는 다항분포가 아닌 다른 모수모델이 필요하다.
나이브 베이즈 모델
모든 특성이 독립적이라는 간단한 가정을 통해 필요한 파라미터를 크게 줄인다.
가정을 적용하기 위해 chain rule을 사용하여 확률 밀도 함수를 조건부 확률의 곱으로 작성.



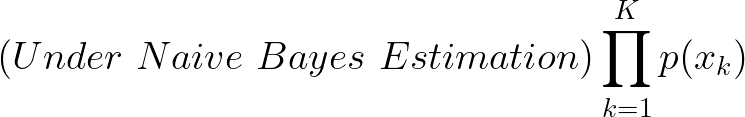
추정해야할 파라미터는 총 7 + 6 + 3 + 8 + 4 - 5 = 23개의 파라미터로 모수모델 특정가능.

예시로 머리색이 검은색, 갈색 2개고 각각 50개의 데이터포인트에서 20번 30번 등장하였으면
Black에서 $\hat{\theta}$= 0.4, Brown $\hat{\theta}$= 0.6
어떤 샘플 x를 생성하는 모델의 확률은 개별 특성의 곱으로 계산한다.
원본 데이터셋에 검은머리, 선글라스, 흰옷 조합이 나타나지 않았더라도 개별 확률의 곱이 0이 아니면 생성이 가능하다.
하얀 옷이 데이터셋에 많다면 그만큼 하얀 옷이 포함된 데이터가 생성될 확률이 높아진다.
나이브 베이즈 가정하에 완전한 확률 밀도 함수를 만들 수 있다.
이미지 데이터셋에서 문제점
기존 정형데이터는 고수준의 feature를 제공하였다. (머리색, 옷색 등)
32x32 픽셀값으로 구성된 데이터는 총 1024개의 특성을 가지고 각 특성은 모두 256개의 값중 1개의 값을 가진다.
이 픽셀데이터에서 나이브 베이즈 모델을 사용하여 학습하고 생성하게 되면 문제가 발생한다.
안경, 머리모양, 옷색깔이 명확하게 구분되지 않은 이미지가 출력된다.
이는 나이브 베이즈 모델이 픽셀을 독립적으로 샘플링하기 때문이다. 인접한 2개의 픽셀이 비슷하다고 생각하지 않는다. 티셔츠 부분의 픽셀 하나는 데이터셋에서 그 위치에 해당하는 픽셀에 의해 학습되기 때문에 인접한 픽셀을 전혀 고려하지 않는다.
표본공간에 가능한 샘플 개수는 매우 많다. 총 256^1024개의 조합이 가능하다. 이 표본공간에서 매우 작은 일부분이 데이터셋과 비슷한 분포를 가진다. (머리, 상체, 헤어, 안경)
따라서 나이브베이즈 모델이 유효한 픽셀의 조합을 생성할 확률은 매우 희박하다.
기존 tabular 데이터는 독립적이고 표본공간이 매우 작기 때문에 나이브 베이즈 모델로 성공적인 생성이 가능하였다. 하지만 이미지 데이터는 각 픽셀이 서로 독립적이라는 가정이 맞지 않다.
픽셀은 서로 상호연관 되어있고 표본공간은 전과 비교할 수 없을 정도로 크다.
생성 모델은 2가지 난관을 극복하여야한다.
- 특성 간에 조건부 의존성이 클 때 대처법
- 모델이 고차원의 표본공간의 생성가능한 샘플 중 만족할 수 있는 하나를 찾는 방법
딥러닝은 2가지를 어느정도 해결할 수 있다.
데이터로부터 의미있는 구조를 추론할 수 있는 모델이 필요한데 딥러닝이 가장 적합하다.
딥러닝 모델이 주로 이미지 생성모델로 사용되는 이유는 여기에 있다.
Represent Learning
- 표현학습은 고차원 표본 공간을 직접 모델링하는 것이 아니라 대신 저차원의 latent space를 사용해 훈련 세트의 각 샘플을 표현하고 이를 원본 공간의 포인트에 매핑하는것.
- 잠재 공간의 각 포인트는 고차원 이미지에 대한 표현.
중앙에 위치한 원기둥 이미지 데이터셋이 있다고 가정하자.
원기둥은 높이와 너비로 고유하게 표현이 가능하다. 하지만 모델이 이를 학습하기는 쉽지 않다.
먼저 모델은 높이와 너비가 원기둥을 가장 잘 표현할 수 있는 잠재공간 차원이라는 것을 알야아한다. 그리고 매핑함수 f를 학습하여 잠재 공간의 한 포인트를 고차원인 이미지에 매핑할 수 있어야한다.
표현학습의 장점은 latent space에서 연산이 가능하다는 것이다. 원기둥 이미지에서 높이를 늘리려면 픽셀을 어떻게 하나하나 조정해야할 지 알기 어렵다. 하지만 높이와 너비 2차원의 잠재공간에서 값을 수정하는 것으로 간단하게 조정이 가능하다.
인간은 표현학습에 능하다. 만약 누군가에게 어떤 사람의 얼굴을 묘사하라고하면 왼쪽 위 픽셀부터 RGB값을 말하지 않고 머리색, 안경 등으로 표현한다.
표현학습의 강점은 샘플을 묘사하는 데 가장 뛰어난 특성과 이 특성을 원본 데이터셋에서 추출하는 방법을 학습한다.
표현학습을 통해 모델은 데이터의 비선형 매니폴드를 찾고 이 매니폴드 공간을 설명하기 위해 필요한 차원을 구성한다.
매니폴드 학습은 데이터 압축, 데이터 시각화, 차원의 저주 감소, feature 추출 등 장점이 있다.
고차원 공간에서 의미적으로 비슷한 두 샘플은 거리가 매우 멀 수있고 거리가 가까워도 의미적으로 멀 수 있다.

[Reference]
[1] Generative Deep Learning - David Foster
'AI > Machine Learning & Data Science' 카테고리의 다른 글
| 직관과 MLE, MAP(2) (0) | 2023.06.27 |
|---|---|
| 직관과 MLE, MAP (1) (0) | 2023.06.22 |
| MLE(Maximum Likelihood Estimation), MAP(Maximum A Posterior) (0) | 2022.11.25 |
| Netflix Challenge - Recommendation System (0) | 2021.02.25 |
| Feature Engineering (0) | 2020.11.27 |


