
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 딥러닝
- 언리얼엔진
- animation retargeting
- ue5.4
- cv
- RNN
- 오블완
- motion matching
- Unreal Engine
- Font Generation
- ddpm
- Few-shot generation
- UE5
- deep learning
- WBP
- 폰트생성
- 모션매칭
- multimodal
- Generative Model
- CNN
- 디퓨전모델
- userwidget
- WinAPI
- dl
- GAN
- NLP
- Stat110
- BERT
- Diffusion
- 생성모델
Archives
- Today
- Total
Deeper Learning
DG-Font: Deformable Generative Networks for Unsupervised Font Generation 본문
AI/Deep Learning
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Dlaiml 2021. 9. 25. 15:27Abstract
- 현존 methods는 대부분 supervised learning, 매우 많은 paired data가 필요
- image-to-image translation은 style을 텍스쳐와 색깔로 정의 냉림
- Feature Deformation Skip Connection (FDSC)를 제시
- predict pairs of displacement map
- employs the predicted maps to apply deformable convolution to the low-level feature maps from content encoder
- style-invariant feature 표현을 학습하기 위해 content encoder에 3개의 deformable convolutional layers를 사용
- SOTA보다 high-quality 글자를 생성하였음
1. Introduction
- 글자 수가 많은 언어의 폰트를 디자인하는 것은 매우 노동집약적이고 시간이 많이 든다.
- "Rewrite", "zi2 zi"는 하나의 스타일을 여러 스타일에 매핑하는 것을 학습하여 폰트를 생성
- EMD, SA-GAN은 content, style 표현을 disentangle 하여 새로운 style이나 content의 글자 생성
- 그러나 위 방법들은 supervised learning이며 많은 paired training samples 필요
- DM-Font, LF-Font는 특정 writing system에만 적용 가능.
- FUNIT은 AdaIN을 사용하여 target font의 추출된 style feature를 stylization but blurry, missing some strokes 문제
- feature statics을 조정하여 style을 바꾸는 AdaIN은 주로 texture와 color를 transform 하는 경향이 있으며 local style patterns(Serif)를 transform 하기에 적합하지 않다
- 다른 method도 두 폰트의 매핑을 디렉트 하게 학습하기 때문의 폰트의 geometric deformable을 무시한다.
⇒ deform과 transform을 사용하는 DG-Font를 제시
- style, content를 분리하고 다시 섞어서 target glyph을 생성
- content encoder에서 나온 low-level feature map에 deformable convolution을 적용
- 폰트의 Style을 geometric transformation, stroke thickness, tips and joined-up writing pattern으로 정의
- FDSC는 spatial deformation을 위해 사용하였으며 generated image가 구조적으로 완벽할 수 있도록 한다. (spatial deformation을 수행하기 때문에 획이 사라지는 문제가 없음)
2. Related works
2.1. Image-to-Image Translation
- Pix2 Pix, CycleGAN, GatedGAN
- FUNIT, TUNIT, DUNIT
2.2. Font Generation
- Zi2 zi, Rewrite, PEGAN, HAN, AEGG, DC-Font
- SA-VAE, CalliGAN, RD-GAN
2.3. Deformable Convolution
- CNN의 내재된 한계는 fixed kernel을 사용하는 것
- additional offsets을 사용하여 sampling 하는 위치를 수정
- object detection, video object detection, semantic segmentation, human pose estimation 등 여러 taks에 사용
- DG-Font에서는 offset을 latent style code를 사용하여 추정
3. Methods
3.1. overview

- Style Encoder: input images의 style representation을 학습, style latent vector $Z_s$ 로 input을 매핑
- Content Encoder: content images의 구조적 특성을 학습, spatial feature map $Z_s$ 로 input을 매핑
- 3개의 deformable convolution layer 포함 → 같은 content(글자)에 대해 style-invariant feature를 만들 수 있도록 해줌
- Mixer: $Z_c, Z_s$ 를 AdaIN을 사용하여 섞어준다
- Feature Deformation Skip Connection (이하 FDSC): content encoder를 통과하여 나온 deformed low-level feature를 mixer에게 전달해준다.
- Multi-task discriminator: 각각 style에 대한 discrimination을 수행. binary classification ****
3.2. Feature Deformation Skip Connection (FDSC)

- 위 그림을 보면 2개의 폰트에서 각 획을 대응시켜 비교할 수 있다.
- 대응관계를 활용하기 위해 geometric deformation convolution을 적용
- low-level feature에서 geometric transformation을 하기 위한 offset을 FDSC가 prediction
- $K_s$ = AdaIN에 의해 style code $Z_s$ 가 injection 된 guidance map
- $K_c$ = content encoder의 feature map
- $K_c, K_s$ 를 concatenation 한 것이 FDSC의 input

- f는 convolution layer, theta는 convolution kernel의 offset과 mask

- $K_c$ 와 sampling parameter theta를 사용하여 deformable convolution $f_{DC}$ 를 적용하면 geometrically deformed feature map $K_{c}'$ 이 나오게 된다.
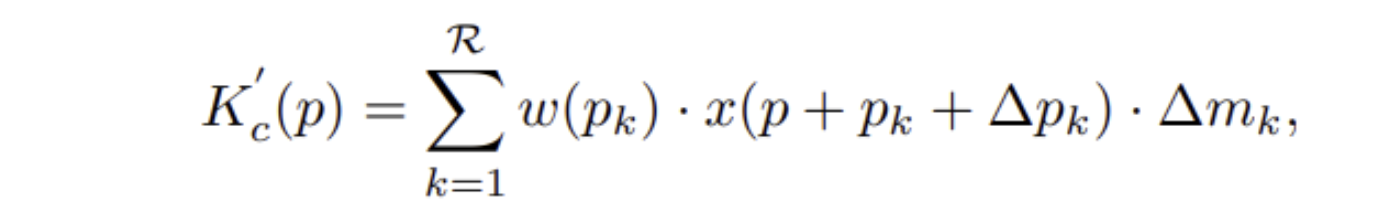
- w(p_k)는 deformable convolution kernel의 k-th location weight를 나타낸다.
- pk + ∆ pk position의 값이 input이 된다. (normal convolution layer에서는 pk, ∆ pk = offset )
- 위 식으로 도출된 $K_c'$ 는 $K_s$ 와 skip-connection을 통해 concatenate 한다. (overview의 그림 참고)
- 폰트 이미지 특성상 같은 색을 가진 영역이 매우 많다. (background / glyph )
- deformable convolution을 사용할 때 same color의 다른 영역과 연관성이 생김 (이미지를 작게 잘랐다고 가정하면 같은 조각이 매우 많음, but 다르게 처리해야 하는 one-to-many problem)
- 위 문제를 핸들링하기 위해 offset ∆p에 제약을 줌
- content image의 feature space에서 spatial structure를 deform 하기 위한 목적으로 FDSC를 사용
- AdaIN을 사용하면 전체적인 위치, 굵기 등 stylization만 가능하기 때문에 geometric specific feature (특정 획의 Serif) 등 style을 살리기 위해 content image의 low-level spatial feature를 transform
- low-level feature가 spatial information을 어느 정도 보존하고 있기 때문에 1, 2번째 convolution layer에 FDSC 모듈을 적용
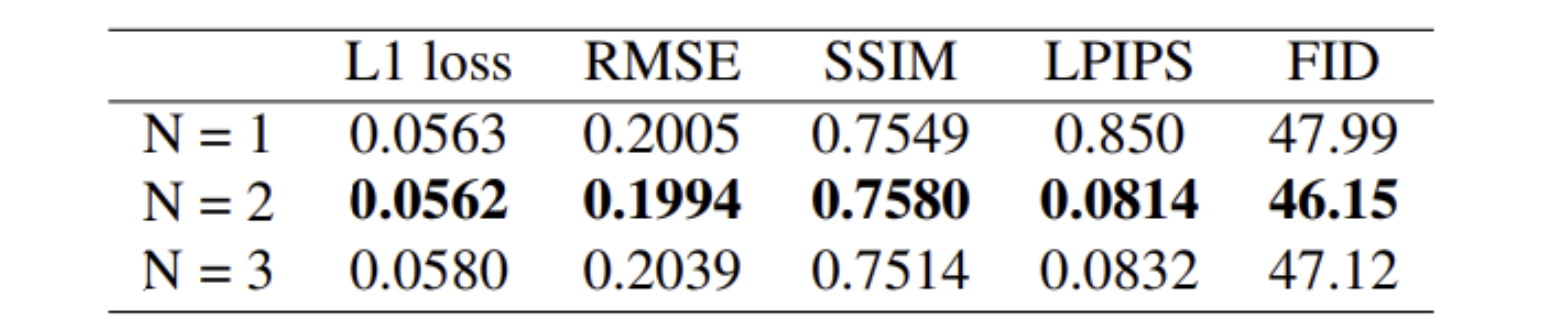
- 2개의 FDSC 모듈을 사용하였을 때 가장 좋은 결과를 보였다
3.3. Loss Function
Adversarial loss

Content consistent loss

Image Reconstruction Loss

Deformation offset normalization

Overall Objective Loss

4. Experiments
4.1. Dataset
- 800개의 glyph으로 이루어진 400개의 중국어 폰트 데이터
4.2. Comparison with State-of-art Methods



5. Conclusion
- unseen font에 대한 effective unsupervised font generation model을 제시
- FDSC 모듈을 사용하여 deformable low-level spatial information을 mixer에게 transfer
- deformable convolution layer를 사용하여 style-invariant feature representation을 학습
Insight
- Font Generation task에서 AdaIN으로 stylization이 쉽지 않은 부분을 deformable convolution layer를 사용하여 content image의 low-level feature를 transfer 시켜 해결한 논문
- Font Domain의 서로 대응되는 획이 있다는 특성에서 시작하여 성공적으로 SOTA quality를 달성
Reference
[0] DG-Font, (2021), Yue Lu. et al., https://arxiv.org/abs/2104.03064
[1] https://dlaiml.tistory.com/entry/Deformable-Convolutional-Networks
'AI > Deep Learning' 카테고리의 다른 글
| Full Stack Deep Learning - Lecture 1 ~ 3 (0) | 2021.10.07 |
|---|---|
| Universal Approximation Theorem (0) | 2021.10.02 |
| Deformable Convolutional Networks (0) | 2021.09.25 |
| EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (0) | 2021.09.20 |
| Multiple Heads are Better than One: Few-shot Font Generation with Multiple Localized Experts (0) | 2021.09.19 |
'AI/Deep Learning' Related Articles
more




Comments